
서론
이 장은 문장을 구성하는 단어들이 어떻게 DeepLearning에 표현되어 적용되는지에 대한 방법(Sparse Representation, Dense Representation)과 학습하는 알고리즘(Word2Vec, FastText)을 다룬다.
목차
- Feature Representation
- Sparse representation
- Sparse representation
- Dense(Distributed) representation
- Word2Vec
- FastText
Feature Representation
데이터는 대상의 속성을 표현해놓은 자료로 예를들어 버섯을 조사해 놓은 자료가 있다면 이 자료에는 버섯의 색깔, 크기, 종류 등의 각각의 속성(데이터)들로 표현되어 있을 것이다. 이런 속성을 표현하는 방식을 말한다.
언어의 표현방식은 크게 sparse representation, dense representation이 있다.
Example
자연어 처리의 경우 대상은 텍스트이고 텍스트의 속성을 표현해놓은 것이 데이터가 된다.
텍스트의 속성으로는 단어 그 자체, 단어의 품사, 문장속 단어의 위치, 단어의 길이 등이 될 수 있다.
이런 언어적 정보를 추출해서 표현하는 것이 언어의 feature Representation이다.
Sparse representation
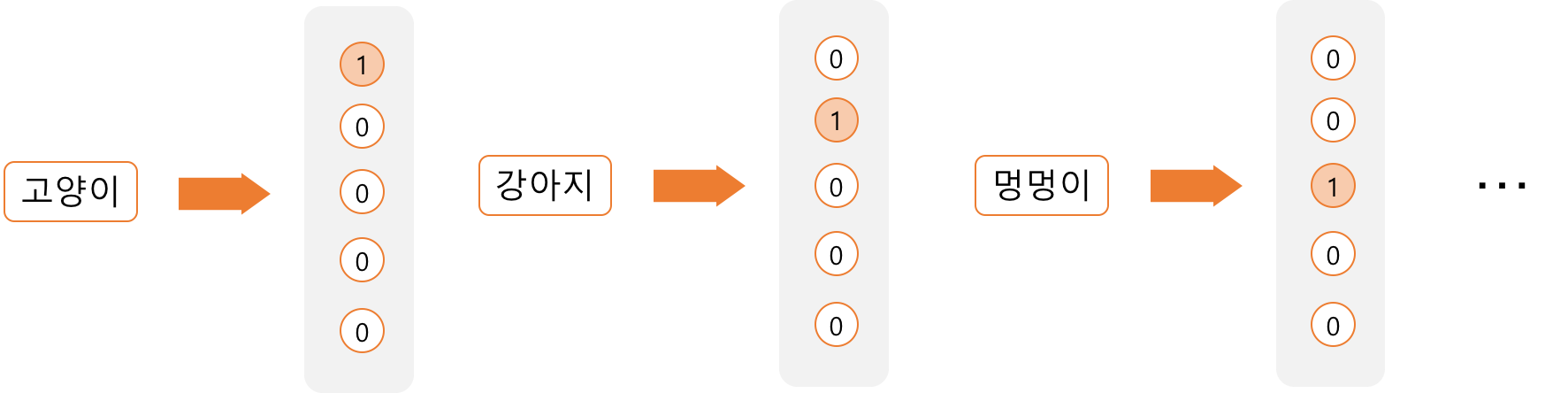
문장에 속해있는 단어들을 One-hot Encoding으로 표현한 것으로 단어의 벡터가 sparse해서 단어가 가지는 의미를 벡터 공간에 표현이 불가능하다.
벡터나 행렬이 sparse하단 의미는 벡터나 행렬의 값 중 대부분이 0이고 몇몇 개만 값을 갖고 있다는 것을 뜻한다.
One-hot Encoding으로 만들어진 벡터는 0이 대부분이기 때문에 sparse한 벡터가 되는 것이다.
Example
문장의 단어가 총 N개라면 가질 수 있는 경우의 수는 총 N차원의 One-hot Encoding으로 표현할 수 있다.
단어 그 자체를 속성으로 둔다면 다음의 각 단어들은 독립적인 차원으로 나타내어진다
ex) I love you → [1, 0, 0], [0, 1, 0], [0, 0, 1]
Dense(Distributed) representation
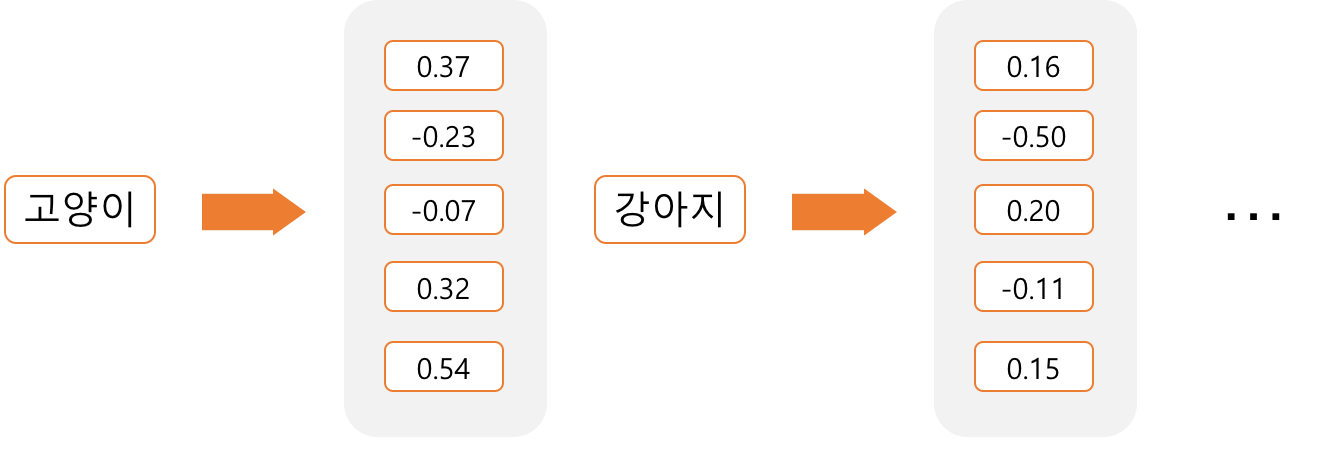
문장내 단어들을 한정된 차원으로 표현이 가능하며 하나의 차원이 여러 속성들관의 유기적인 관계로 연결되어 있어 단어간 의미 관계 유추가 가능하다. 이러한 벡터로 표현한 방식이 워드 임베딩이다.
이러한 임베딩은 머신러닝 학습 알고리즘을 통해 가능하다.(ex Word2Vec, FastText ..)
Example
아래 그림과 같이 특정 단어를 5차원 **벡터에 대응(임베딩)**시켜 표현되어지며 고양이와 강아지라는 단어가 얼마나 유사한지 다른지는 벡터간의 거리를 통해 알 수 있다.
Word2Vec
위에서 언급한 Dense Representation의 장점들은 모두 Word Embedding이 잘 학습되었다는 전제 하에서 성립한다. Word2Vec는 Word Embeding을 학습하는 알고리즘 중 하나이다.
두가지 방법으로 학습한다.
- 문장의 맥락으로 단어를 예측(Continuous bag of words)
- 현수의 ____가 짖는다. → 강아지
- 단어로 문장의 맥락을 예측(Skip-gram)
- ____ 강아지가 ____ → 주어와 동사
장점
- 단어간 유사도 측정이 용이
- 단어간 관계 파악이 쉬움
- 벡터 연산을 통해 추론 가능
단점
단어의 subword information(ex. 서울, 서울시, 고양시와 같이 ‘시’라는 부분단어의 정보)이 반영되지 못해 Out of vocabulary(사전에 학습되지 않은 단어들)에서는 추론이 불가능하다.
FastText
Facebook research에서 공개한 Open Source library로 단어를 기존의 word2vec과 유사하나 단어를 n-gram으로 나누어 학습을 수행하는 워드 임베딩 방법.
기존 word2vec의 단점인 Document frequency(문서에 포함된 단어의 빈도수)가 낮을 경우 word2vec의 out of vocabulary문제를 어느정도 해결할 수 있다.
Example
n-gram의 범위가 2-5일 때 assumption = {as, ss, su, …., ass, ssu, sum, ump, mpt, …, ption, assumption) 위 방식으로 학습하면 assume이라는 학습되지 않았지만 assumption과 유사한 의미를 가진 단어가 들어왔을 때 subward information을 통해 에측이 가능하다.
그러나 word2vec, FastText는 아래와 같은 상황에 대해서는 임베딩 성능이 좋지못하다
- Account
- (~라고 생각하다) I account him to be my friend
- (~ 때문에) He is angry on account of being excluded from the invitation
- (보고서) The police wrote an account of the accident
- (계좌) I have T.A bank account
[Reference]
[토크ON세미나] 자연어 언어모델 'BERT' 2강 - 언어 모델 (Language Model) | T아카데미
Comment