
목차
- Kafka란?
- Kafka 기본 개념
- Kafka 동작 원리
- Kafka Replication
Kafka란?
Kafka는 Apache에서 만들었으며 스칼라로 개발된 오픈소스 메시지 브로커 프로젝트입니다.
성능 좋은 ‘메시지 큐’라고 볼 수 있으며 대용량 데이터를 실시간으로 빠르게 안정적으로 처리하는 분산형 스트리밍 플랫폼 입니다.
발행 구독 모델
Kafka는 발행-구독 모델을 기반으로 동작합니다.
- 발행자(Publisher): 데이터를 직접 받는 사람에게 보내지 않고 Kafka와 같은 중간 시스템(브로커)에게 전송
- 브로커(Broker): 중간 역할을 하는 Kafka가 데이터를 보관하고 필요한 사람들에게 전달
- 구독자(Consumer): 필요한 특정 데이터를 Kafka에서 가져감
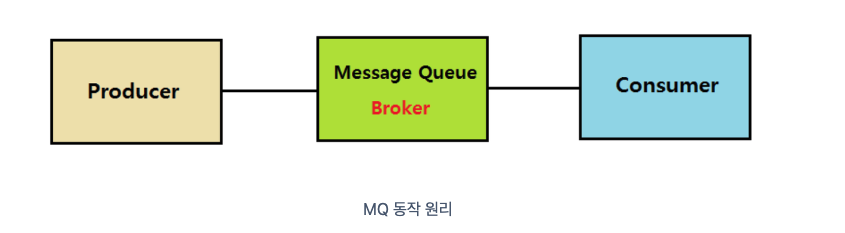
Kafka 동작원리
이벤트 브로커 동작방식을 사용
메시지 브로커 동작 방식
- 생산자가 메시지를 보내면 브로커가 이를 지정된 소비자에게 전달하고 전달되면 메시지를 삭제
이벤트 브로커 동작 방식
- 이벤트 브로커는 메시지를 삭제하지 않고 일정 기간 동안 보관
- Kafka와 같은 이벤트 브로커는 메시지(이벤트) 소비 후에도 일정기간 삭제하지 않고 저장해 두기 때문에, 이후 특정 시점부터 다시 가져와서 처리가능
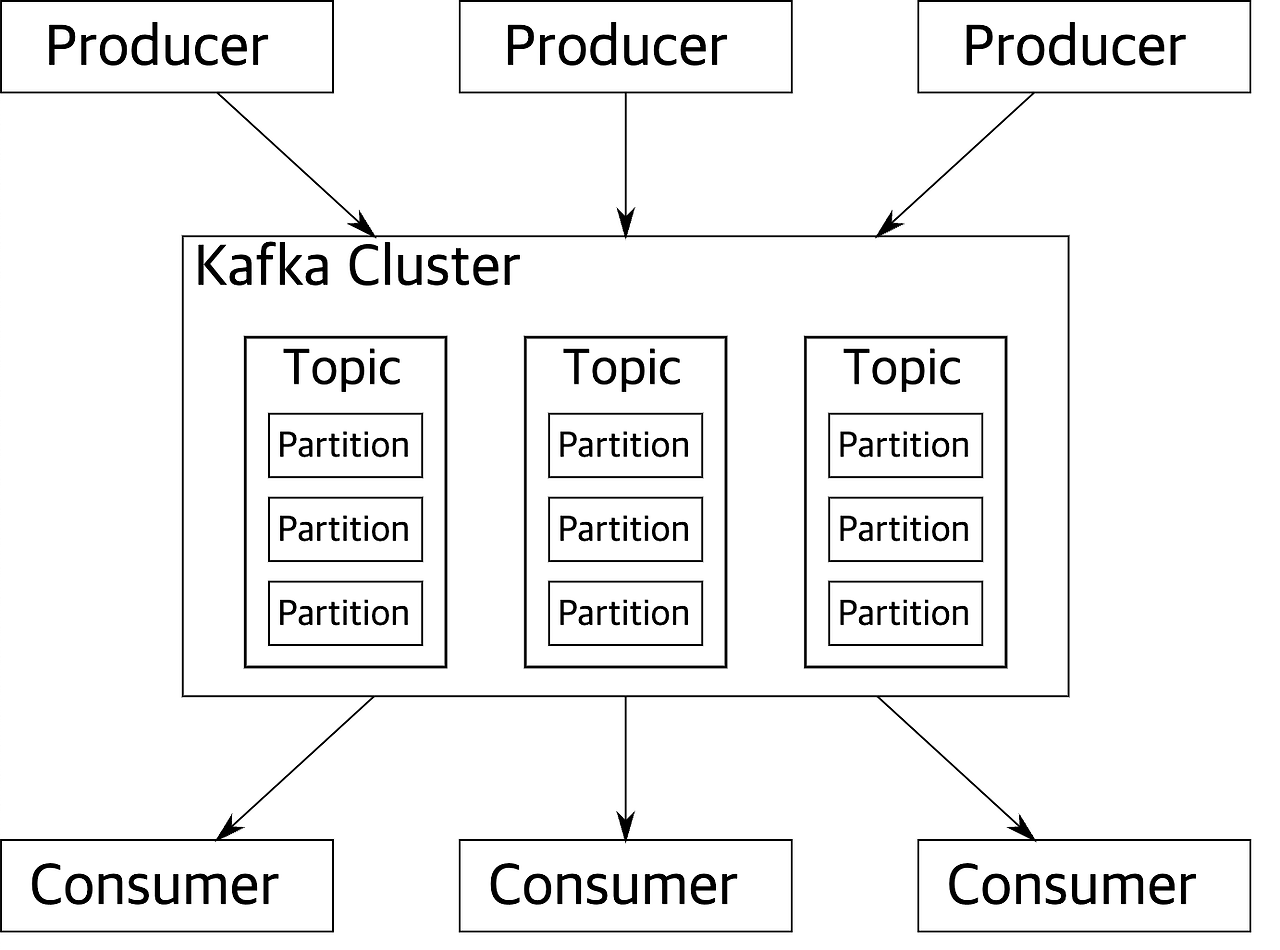
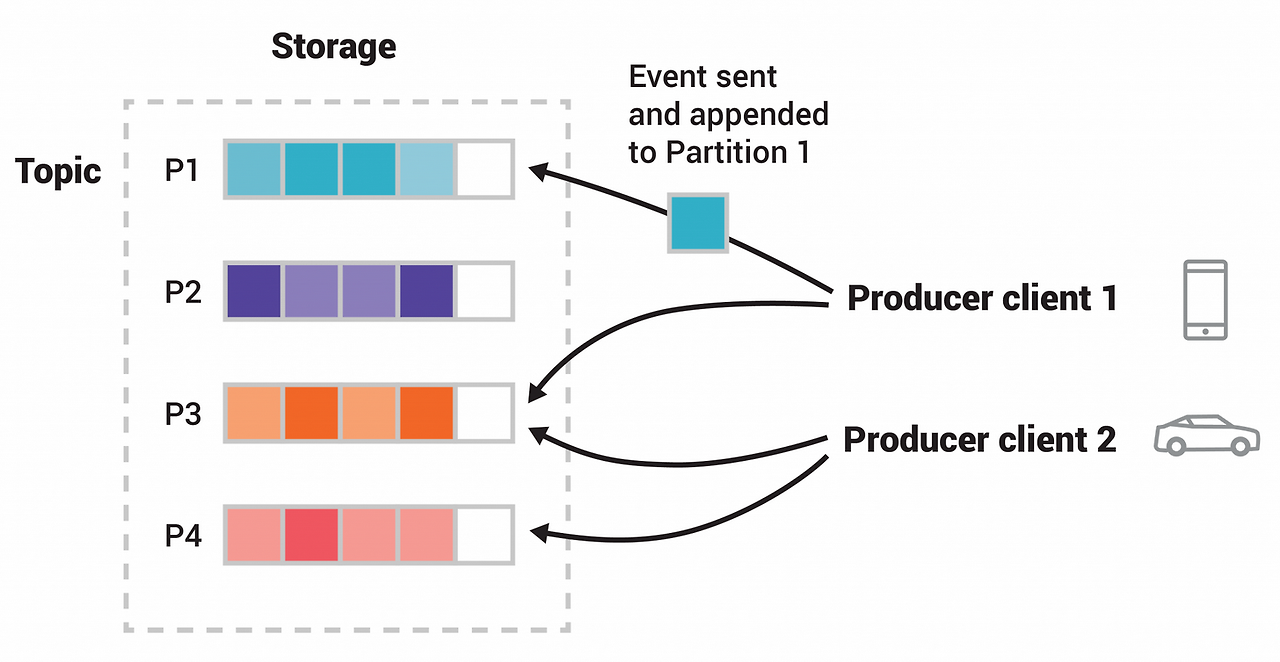
Producer
- Producer는 토픽을 지정하여 데이터를 Partition에 저장
- 파티션이 여러개인 경우 랜덤으로 파티션을 선택하여 저장한다.
- 따로 분할 방식을 구현하여 적용할 수 있다.(ex. Round robin)
- 같은 키를 같는 메시지는 같은 파티션에 저장되며 순서가 유지된다.
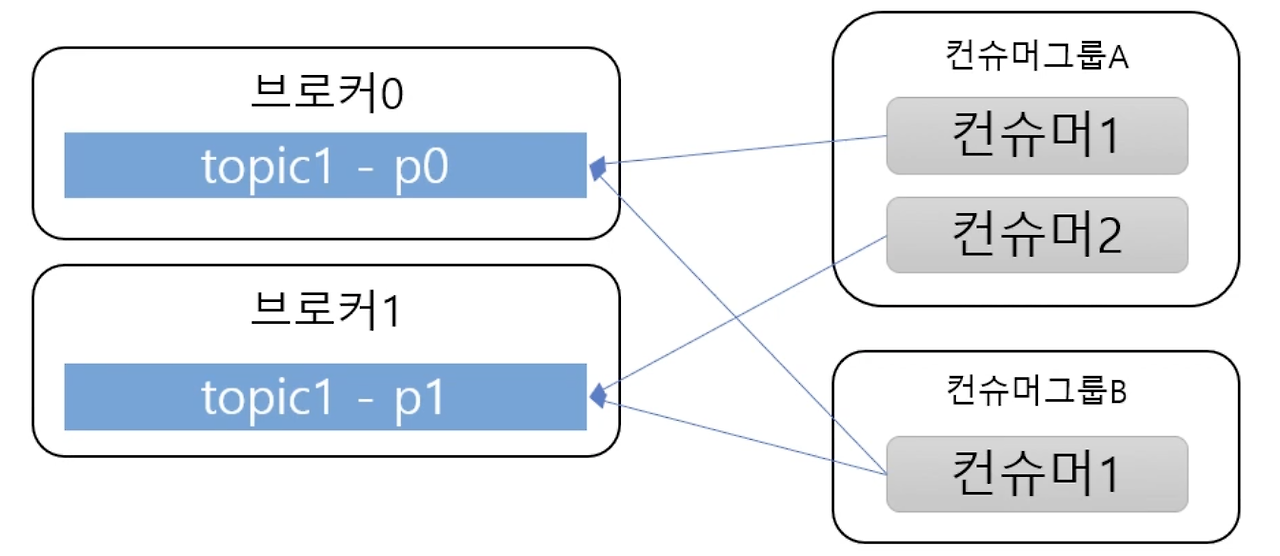
Consumer
- 소비자들은 같은 Group끼리 하나의 팀이 되어 같은 토픽을 나눠서 데이터를 읽을 수 있다.
- 같은 Group끼리는 하나의 토픽에 대하여 각기 다른 파티션을 소유함으로써 중복 없이 데이터를 분배 받을 수 있다.
- Group이 없는 경우 파티션의 모든 데이터를 소비자가 전부 받게되어 중복으로 데이터를 분배받는다.
Broker
- 실행되는 Kafka서버를 말한다. 즉, 하나의 브로커는 하나의 Kafka 서버 프로세스
- Kafka 서버 내부에 메시지를 저장하고 관리하는 역할
ZooKeeper
- 분산 메시지큐의 메타 정보를 중앙에서 관리하는 역할
- ex) 클러스터 설정 관리, 브로커, 파티션, 클라이언트등 관리
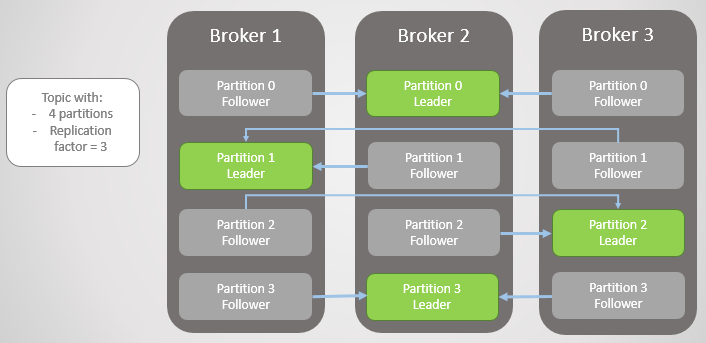
Kafka Replication
- Replication Factor: 각 파티션이 가지는 원본 데이터를 포함한 복제본의 총 개수
- 동일한 Replication에 대해서는 Leader, Follower가 존재
- Leader를 통해서만 읽기/쓰기가 가능함으로 생산자와 소비자 들은 리더를 통해서 데이터를 등록하고 가져감
- Follower들은 Leader에게 이슈가 있는 경우를 대비해 언제든지 새로운 Leader가 될 준비를 함
- 지속적으로 새로운 메시지를 확인하고 새로운 메시지가 있으면 Leader로부터 메시지를 복사함
디스크 순차 저장 및 처리
Write
- 데이터를 디스크에 순차적으로 기록(데이터가 각 파티션에 연속된 파일로 기록)
- 데이터를 일정한 크기로 분할하여 파일에 저장
- 페이지 캐시 활용
- 디스크에 저장되기 전에 페이지 캐시에 먼저 저장
- 페이지 캐시는 운영체제가 관리하는 구조로 바뀜
- 운영체제가 자주 사용하는 데이터는 페이지 캐시에 유지해 두기 때문에, 필요한 데이터를 메모리처럼 빠르게 읽을 수 있는 효과를 얻음
- 여러 메시지를 배치로 묶어서 저장
- 오프셋 기반으로 데이터를 관리
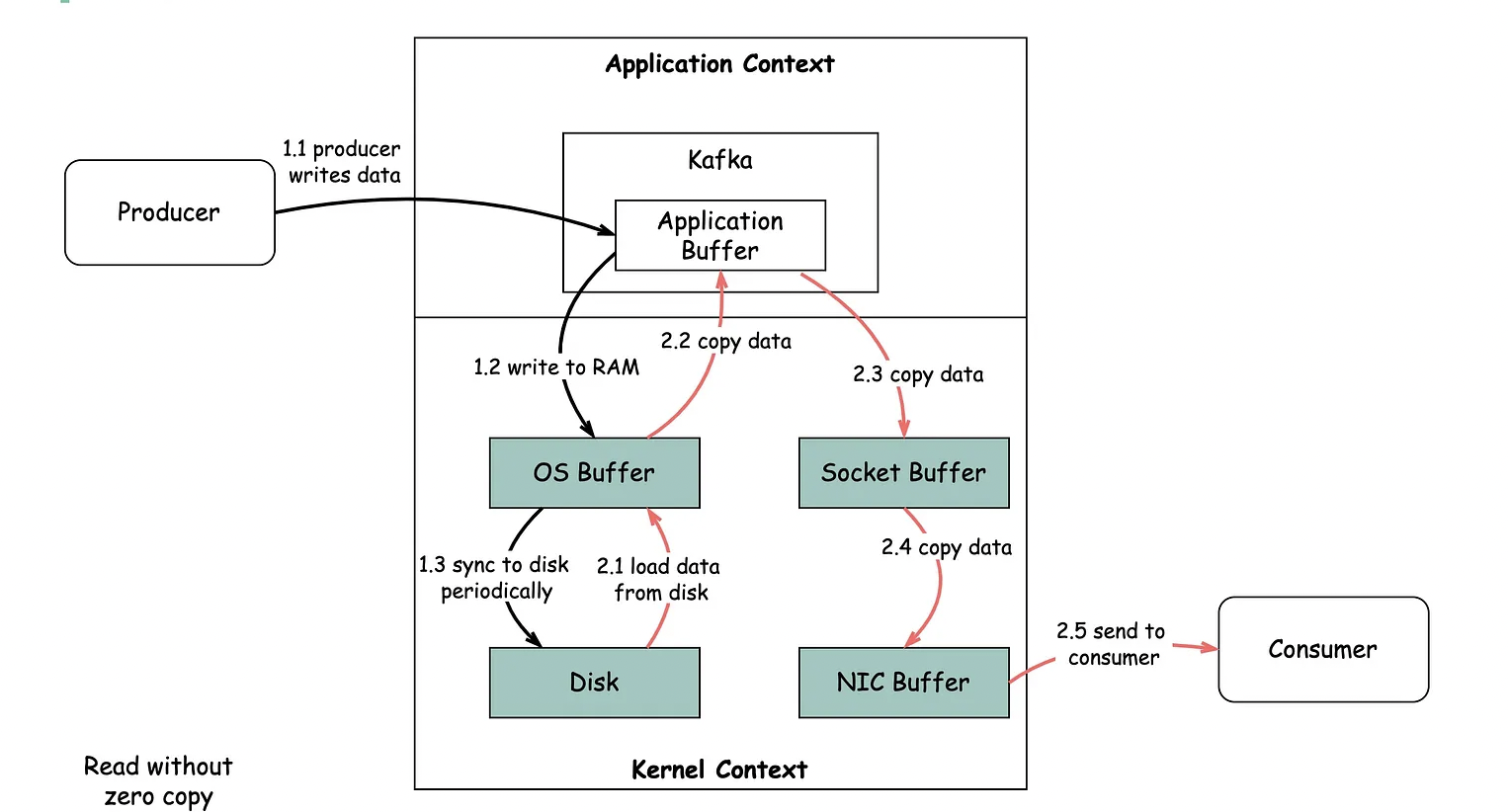
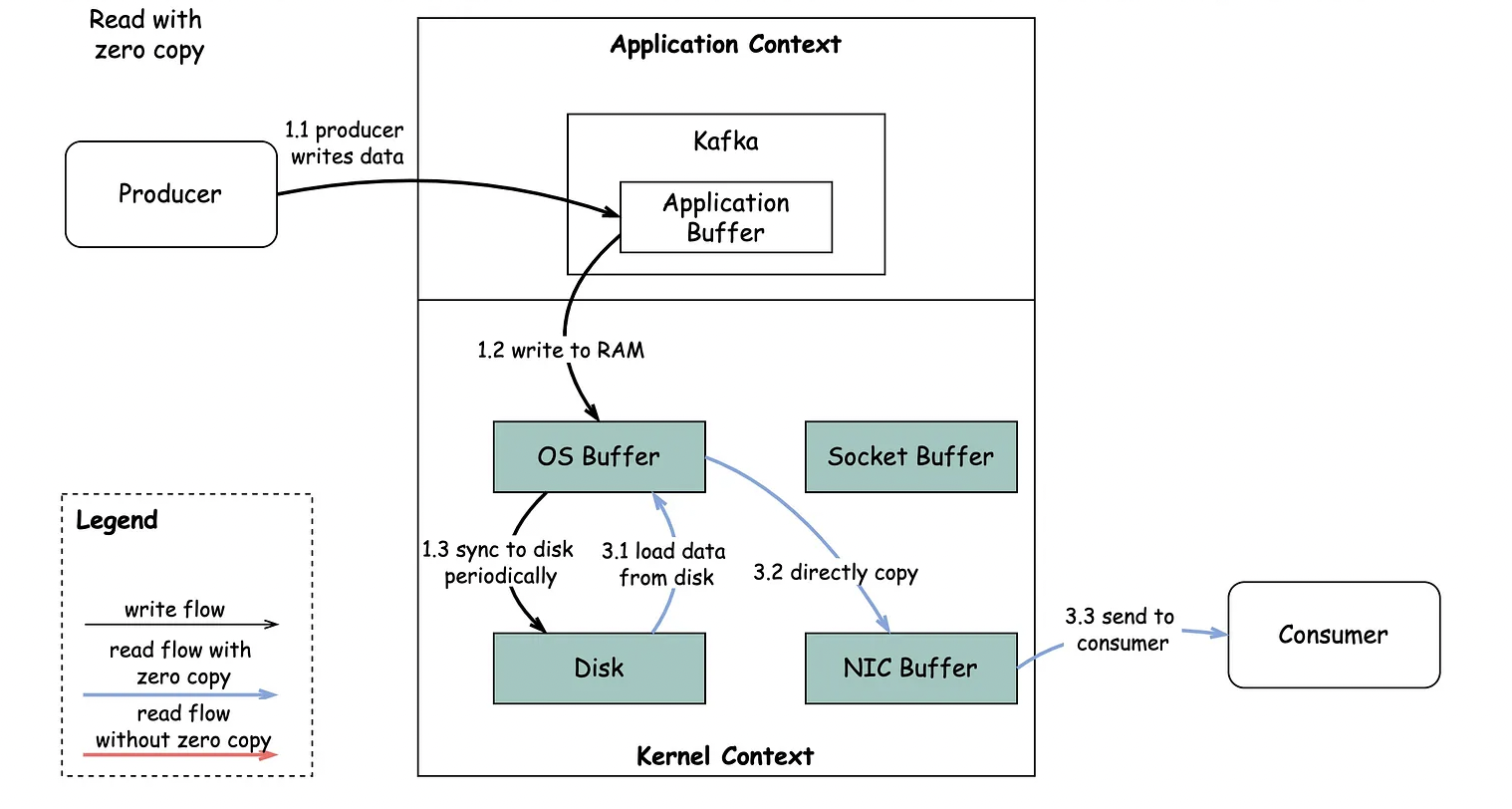
Read
- Zero Copy() 기법을 사용해 디스크에 저장된 데이터를 메모리로 복사하지 않고 직접 전송
With out Zero Copy
With Zero Copy
Comment