
Cite
Anthony Brohan, Noah Brown, Justice Carbajal, Chelsea Finn, Sergey Levine, et al.; arXiv preprint arXiv:2307.15818 [cs.RO]
- https://navila-bot.github.io/static/navila_paper.pdf?utm_source=chatgpt.com
- 출간일: 2024. 12. 03
- 저널: arXiv (Robotics [cs.RO] category)
Abstract
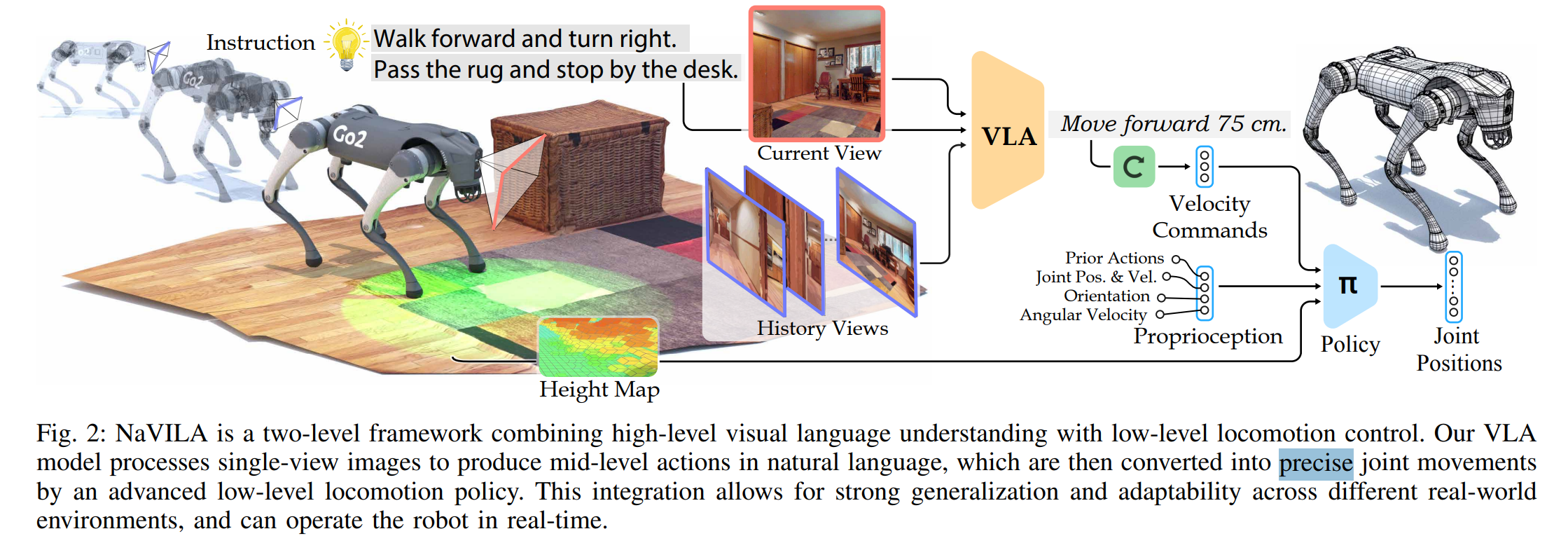
우리는 2단계 프레임워크를 제안한다. NaVILA(VILA모델을 기존 VLM을 기반으로 하여 내부 구조를 VLN에 맞게 조정한 모델 → Navigation + VILA)는 기존의 VLA처럼 저수준 동작을 직접 예측하는 대신, “앞으로 75cm 전진”과 같은 공간 정보를 포함한 중간 수준(mid-level) 언어 기반 행동을 먼저 생성하고, 이를 시각 기반 보행 강화학습 정책(visual locomotion RL policy)의 입력으로 사용하여 실제 동작을 수행한다.
Instruction
VLN에서 로봇이 자연어 지시를 따라 움직이기 위해서는 두 가지 능력이 필요하다
- 지속적으로 센서를 읽어 상황을 판단하는 closed-loop planning
- 다리, 관절을 실시간으로 조절하는 저수준 제어 컨트롤러(보행 제어)
자연어 지시를 곧 바로 저수준 명령으로 변환하는 것은 매우 어려운 문제다.
이에 따라 본 연구는 VLM이 중간 수준(mid-level)의 언어 기반 행동을 출력하도록 미세조정한다.
예를 들어 VLM은 “오른쪽으로 30도 회전”, “앞으로 75cm 전진”을 출력하고 저수준 보행 정책은 이 언어 명령을 받아 실제 다리 관절 제어로 변환한다.
closed-loop 의미 [현재 상태/센서] → [계획·결정] → [동작] → (결과가 환경에 반영) → 다시 [센서로 입력] 처럼 되돌아오는 순환 구조가 닫혀 있는 상태
open-loop 의미 [입력] → [시스템] → [출력] 출력이 입력으로 되돌아오지 않는 상태로 출력을 통해 시스템이 스스로를 수정하거나 보정하지 못한다.
이러한 구조의 장점은 다음과 같다.
- 저수준 제어와 고수준 행동 생성을 분리함으로써 동일한 VLA모델을 여러 로봇에서 공유할 수 있다.
- 행동을 중간 수준의 자연어로 표현하기 때문에 폭넓은 비전-언어 자료를 활용하여 VLA를 학습할 수 있다.
- Two-frequency 구조를 사용해 계산량이 큰 VLA(큰 뇌)는 느린 주기로 계획을 담당하고 보행 정책(작은 뇌)은 실시간으로 다리를 제어한다. 이로써 높은 안정성과 견고성을 확보한다.
Train Strategy
- 단순 정적 이미지 대신, 이전 이동 경로(히스토리)까지 이해하도록 기존 VLM 입력 구조를 확장하였다.
- 로봇이 내비게이션 중 어떻게 행동해야 하는지 명확히 지시하는 특별한 프롬프트를 설계했다.
- Youtube의 실제 투어 영상을 활용하여 연속적 공간 이동을 이해하고 VLN성능을 향상시켰다.
- 여러가지 내비게이션 데이터셋을 잘 섞어서 학습시켜 새로운 환경에서도 잘 일반화되도록 만들었다.
Visual locomotion Controller
- LiDAR 포인트 클라우드로에서 height map(바닥의 높이만 보여주는 2D지도)을 구성하여 지형(바닥) 정보를 기반으로 로봇이 직접 “어디에 발을 디딜지” 배우게 했다.
- 시뮬레이터에서 학습한 보행 정책이 실제 환경에서도 안정적으로 동작하기 위해, 학습 과정에서 마찰 계수, 조명 조건, 지형 형태, 센서 노이즈 등을 다양하게 변화시키며 랜덤화한다.
Result
실험 결과, 본 VLA는 기존 VLN 방법 대비 17% 높은 성공률 을 기록했다.
또한 새로운 벤치마크인 VLN-CE-Isaac을 도입해 보행 내비게이션을 정확하게 평가했다.
Unitree Go2, Unitree H1, Booster T1 등 서로 다른 로봇 플랫폼에서도 정상적으로 동작하며,
실제 환경 테스트에서 25개 지시 중 88% 성공, 특히 복잡한 지시에서는 75% 성공률을 달성하며 높은 견고성을 입증했다.
Methods
VLN은 비디오를 바탕으로 로봇의 시각 정보를 반영하지만 비디오 인코더는 학습 데이터가 부족하여 성능이 제한된다. 그래서 비디오 대신 이미지 기반 VLM(VILA)를 사용한다.
이미지 기반 VLM은 데이터도 많고 일반화 능력도 뛰어나며, multi-image reasoning(이미지를 연결해서 이해하는 능력)이 좋아 연속된 장면을 해석해야하는 VLN에 적합하다.
VILA Preliminary
VILA에서 Vision Encoder는 입력 이미지를 처리하여 Visual token들이 순서대로 나열된 형태(sequence)로 변환한다.
이후 Visual token은 down-sampling과정을 거쳐 MLP Projector에 전달되며 MLP Projector는 이 시각 벡터들을 자연어 모델이 이해할 수 있는 text token space로 변환한다.
변환된 visual token들은 텍스트 토큰과 함께 LLM에 입력되며, LLM은 auto-regressive 방식으로 출력을 생성한다.
Visual Tokens: 이미지를 그리드 형태로 분할하고 각 그리드 셀은 패치(조각)이라 하는데, 이 패치들을 의미있는 숫자로 변환하여 하나의 고정 길이 벡터로 바꾼 형태를 말한다.
auto-regressive: 자기 자신의 이전 값들을 이용해 다음 값을 예측하는 모델로 이전에 생성한 토큰을 기반으로 다음 토콘을 하나씩 예측하며 문장을 완성하는 방식
VILA의 3단계 학습 과정
VILA를 VLN수행에 적합한 형태로 만들기 위해, 모델은 다음 세 단계를 거쳐 조정된다.
- 1단계: 이미지를 LLM이 잘 이해할 수 있는 토큰 형식으로 변환하는 것(connector pre-training)
- Vision Backbone과 LLM은 frozen상태로 두고, 둘 사이를 연결하는 커넥터(MLP)만 pre-train한다.
- 2단계: 이미지와 텍스트 간 의미 정렬(semantic alignment)
- connector와 LLM을 함께 학습시키며 text-image interleaved corpus로 이미지의 의미가 텍스트 개념과 대응되도록 학습한다(조정한다).
- 예를 들어 이미지 안의 ‘의자’ 개념이 텍스트 토큰 “chair”와 자연스럽게 연결되도록 만드는 단계이다.
text-image interleaved corpus: 이미지에 대한 설명이 섞여있는 말뭉치 <이미지: 방사진> “The Room has a wooden desk and a window”
- 3단계: 로봇 명령 수행 능력 구축(Instruction Tuning)
- Visual Encoder, Connector, LLM을 모두 학습시켜 instruction tuning data로 fine-tunning 한다.
Instruction tunning data: 명령 → 행동 구조의 데이터 지시: “이 구조에서 가장 가까운 출구로 이동하세요.” 이미지: <Camera Frame> 답: “Go forward and turn left.”
Navigation Prompts
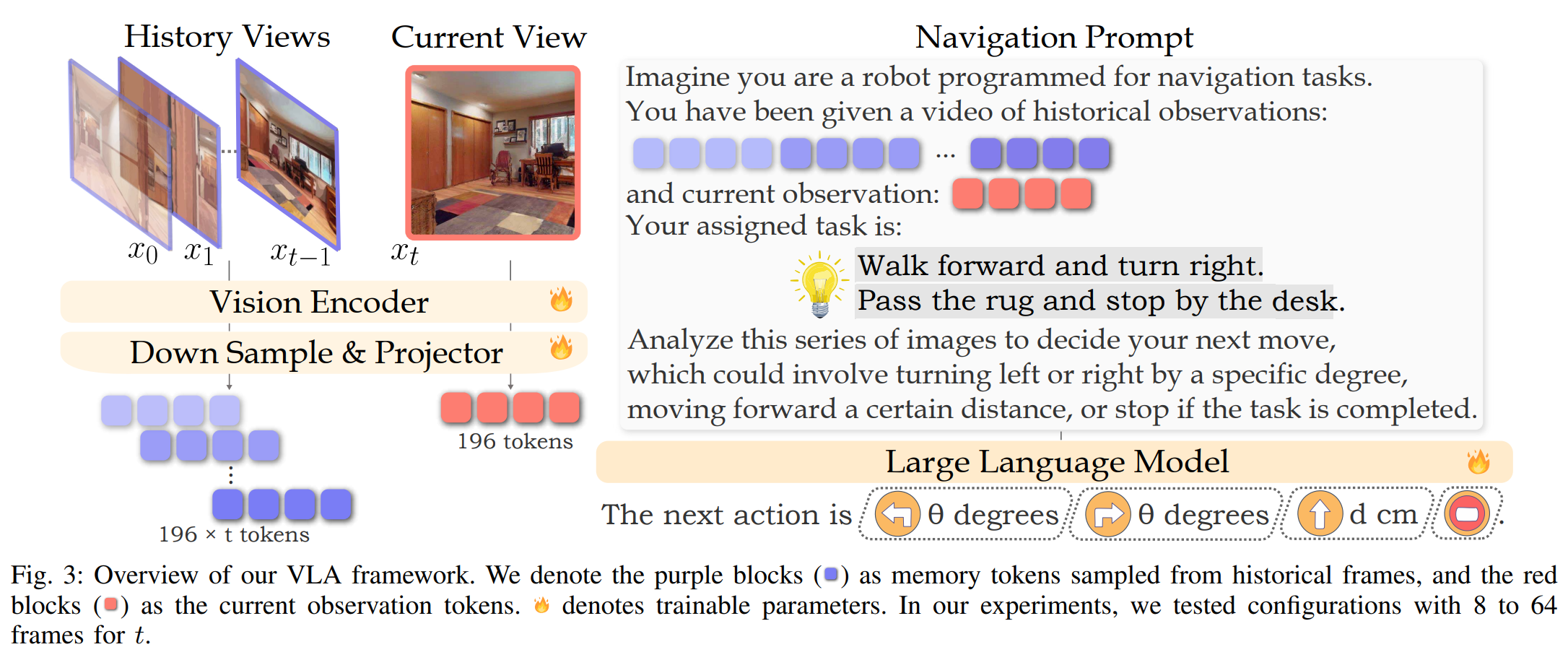
VLN에서는 현재 시점과 과거 시점의 이미지가 서로 다른 역할을 수행한다.
- 현재 프레임(t):
- 로봇이 지금 보고 있는 장면으로 “오른쪽으로 꺾기”, “앞으로 전진하기” 같은 즉각적이 판단에 중요한 정보이다.
- 과거 프레임(t-1):
- 로봇이 이전에 지나온 경로에 대한 기억(historical observations)을 제공하며, 시작 지점과 이동 경로를 추론하고 다음 행동을 계획하는데 도움을 준다.
하지만 VILA는 여러 이미지를 단순히 나열해 처리하는 multi-image reasoning구조이기 때문에, 시간 순서를 구분하여 이해하는 능력이 없다.
따라서 VILA는 모든 프레임을 동등한 이미지 집합으로 처리하기 때문에 VLN처럼 시간적 문맥이 주용한 작업에는 그대로 사용할 수 없다.
이를 해결하기 위해 NaVILA는 모델 구조를 바꾸지 않고, 프레임의 역할을 텍스트로 명시하는 Prompt 설계
를 도입한다.
Historical observations:
<과거 이미지 embeddings>
Current observation:
<현재 이미지 embedding>예를들어 위 처럼 Historical observations, Current observations라는 일반 텍스트 토큰을 사용해 두 종류의 프레임을 명확히 구분해준다.
추가적인 Special Token을 만들 필요가 없기 때문에 모델 구조 변화 없이도 시간적 문맥을 LLM에 효과적으로 전달할 수 있다.
이러한 설계를 통해 모델은 세 가지 종류의 정보를 하나의 입력(prompt)으로 통합하여 사용한다.
- 과거 프레임을 표현하는 토큰들 - 로봇이 지금까지 지나온 경로(히스토리)를 나타낸다.
- 현재 프레임을 표현하는 토큰 - 로봇이 지금 보고 있는 장면(현재 관측)
- 자연어로 주어진 내비게이션 지시문 - 사람이 로봇에게 내린 명령
이 3가지 요소를 결합하여 Navigation Task Prompt를 구성하여 로봇이 “과거에 어디를 지나왔는지”, “지금 무엇을 보고 있는지”, “무엇을 해야 하는지”를 하나의 입력 안에서 모두 이해하도록 설계하였다.
Learning From Human Videos
기존 연구들은 사람이 걷는 영상에서 데이터를 뽑아와도
- 주로 격자 기반 (이산적) 네비게이션 알고리즘에만 사용했다.
- 그래서 “얼마큼 이동했는지 / 어디로 회전했는지” 같은 연속적인 행동(action label)을 직접 추출해본 적이 거의 없다.
왜냐하면 연속적인 경로를 인간 영상에서 자동으로 얻기가 너무 어려웠기 때문이다.
그러나 Metric-pose estimation(정밀한 사람의 자세·위치 추정 기술)이 발전했기 때문에 이제는 유튜브 비디오만 있어도,
- 사람이 몇 도로 회전하고
- 몇 미터 이동했는지
- 실제 공간에서 어느 위치에 있었는지
를 정량적으로 추출할 수 있다.
따라서 사람이 촬영한 비디오를 통해 로봇 내비게이션 모델을 학습시키는 것이 가능해졌다.
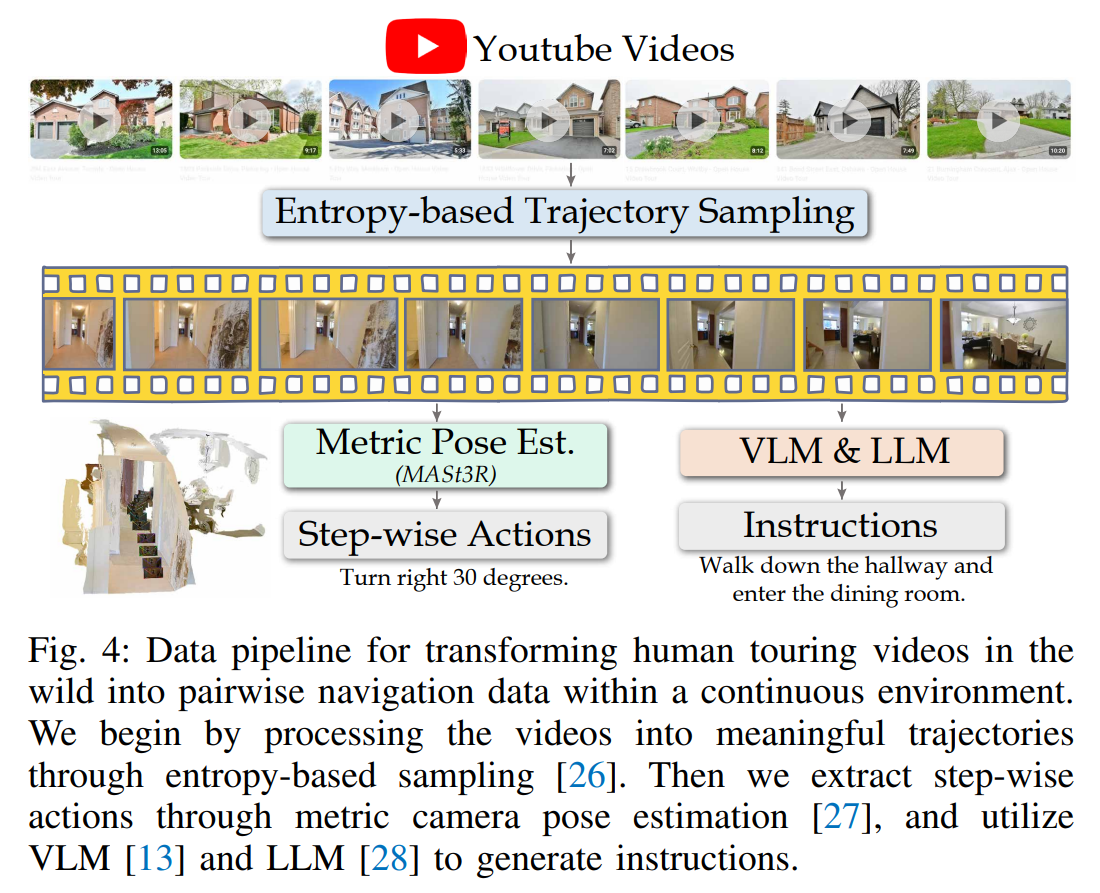
데이터 파이프라인(Fig. 4)은 YouTube에서 수집한 2000개의 1인칭 시점 투어 영상을 사용한다.
우리는 이 영상들을 엔트로피 기반 샘플링(entropy-based sampling) 방법을 사용해 서로 다른 움직임 구간으로 나누고 결국 약 20,000개의 다양한 이동 경로를 만들어 냈다.
사람이 걸어다니는 긴 영상을 그대로 쓰지 않고 영상 속에서 움직임의 변화가 뚜렷한 구간을 골라서 짧은 이동 경로 조각으로 나누는데 이때 뚜렷한 구간을 고르는 방법을 entropy-based sampling을 사용한 것이다.
그 다음 추출된 각 경로에 대해 VLM 기반 캡셔닝 모델 [13]로 자연어로 장면 설명을 생성하고, 이 문장을 LLM [28]으로 자연스럽고 명령 형태의 내비게이션 지시문으로 다시 다듬는다(rephrasing). (모델의 입력)
그리고 MASt3R을 이용해 각 장면의 카메라 위치와 방향을 추정하여 사람이 영상 속에서 얼마나 이동했는지, 어떤 방향으로 회전했는지와 같은 연속적인 행동 정보(action label)를 자동으로 얻는다. (모델의 정답 라벨)
Supervised Fine-tuning Data Blend
모델은 로봇이 embodied tasks을 잘 수행하도록 학습되어야 한다.
이를 위해 NaVILA는 SFT(Supervise Fine-tunning)을 4가지 관점으로 구성했다.
- 실제 Real Video 기반의 내비게이션 데이터
- 시뮬레이션 환경에서 얻은 내비게이션 데이터
- 내비게이션 이해를 돕는 보조(auxiliary) 데이터
- 일반적인 VQA 데이터
embodied task: 물리적인 몸을 가진 로봇이 실제 세계에서 행동하며 수행하는 과업
시뮬레이션 환경에서 얻은 내비게이션 데이터
시뮬레이션 환경에서 활용 가능한 내비게이션 데이터로는 R2R-CE와 RxR-CE 두 가지가 있다.
그러나 이 데이터셋들은 원래 이산적(discrete) VLN 환경에서 구축된 것으로,
연속적인 이동 정보가 아닌 드문드문 배치된 경로 지점(sparse path points)만 제공한다.
- A → B 지점의 좌표값
Discrete VLN 환경에서는 공간이 바둑판처럼 그리드 단위로 구성되어 있어, 로봇은 0.1m·0.4m 같은 연속적인 거리 이동이 아니라 정해진 격자 셀 단위로만 움직일 수 있고, 회전 또한 90도와 같은 고정된 각도에서만 가능하다.
따라서 이 데이터는 실제처럼 continuous하게 이동하는 action label을 얻을 수 없다.
이를 해결하기 위해, 우리는 Habitat 시뮬레이터를 이용한다.
각 sparse path point 사이를 잇는 연속적인 실제 이동 경로(continuous trajectory)를 재생성하고,
이를 기반으로 NaVILA 학습에 필요한 연속 행동(action labels)을 구성하였다.
또한 전체 데이터셋의 크기를 줄여 효율을 높이고 과적합을 줄이기 위해 위해 여러 개의 연속된 행동을 병합한다.
예를 들어:
- 25 cm 전진 → 25 cm 전진
- 두 행동을 하나로 묶어 50 cm 전진
또한 레이블 불균형 문제 특히 전진은 많은데 멈춤(stop)은 부족함으로 재균형(rebalancing)기법을 적용하여 행동 분포를 더 고르게 만든다.
그리고 시뮬레이션 데이터에도 앞서 설명한 Navigation Prompt(현재프레임 + 과거 프레임)형태로 동일하게 적용한다.
일반적인 VQA 데이터
마지막으로 NaVILA의 general capabilities를 유지하기 위해 일반 VQA(Visual Question Answering) 데이터셋을 사용한다
Visual Locomotion Policy(GO2)

LiDAR
Fig 5에서 보이는 것 처럼 Go2 로봇은 머리 하단에 LiDAR센서가 장착되어 있으며 초당 15Hz(1/15초 마다 한번씩 새로운 포인트 클라우드를 갱신한다.) 주기로 포인트 클라우드를 송신한다.
Joint
로봇은 3개의 축에서 회전과 이동을 할 수 있다.
이동 - 3 DoF
- 앞/뒤 (x방향)
- 좌/우 (y 방향)
- 위/아래 (z방향 - 다리 관절을 움지경서 Body Height 조절)
회전 - 3 DoF
- 롤(roll) - 옆으로 기울기
- 피치(pitch) - 앞뒤로 기울기
- 요(yaw) - 좌우로 회전(방향 틀기)
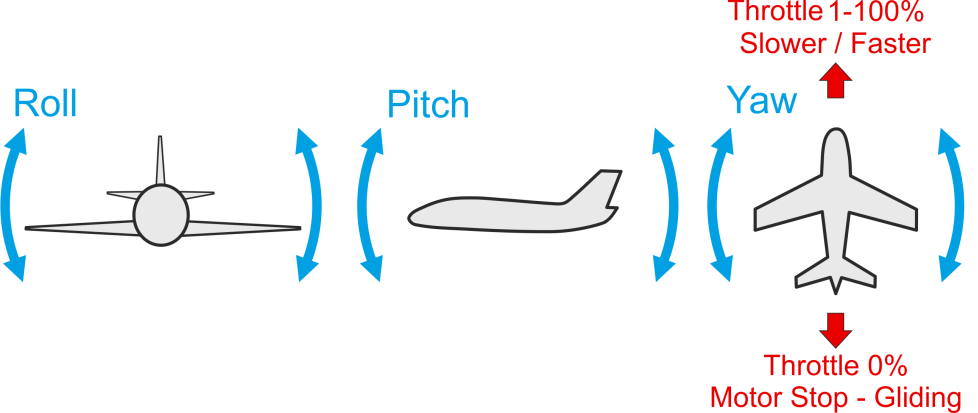
몸통은 총 6 DoF를 가진다.
Go2의 하나의 다리에는 3개의 관절이 있다:
- Hip Roll


- Hip Pitch


- Knee Pitch


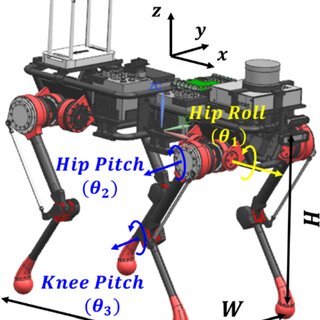
따라서 몸통 6개 + 4개의 다리 4 * 3(관절) = 12 총 18개의 DoF(자유도)를 가진다.
Locomotion Policy에서는 로봇의 몸통 6 DoF를 직접 제어하지 않고 12개의 다리 관절 모터만 제어하도록 하였다.
Interpreting High-level Commands
VLM에서는 action words를 출력한다:
- Move forward
- turn left, right
- stop
하지만 이 단어만으로 로봇이 실제로 어떻게 움직여야 하는지 알 수 없다.
그래서 이 단어를 Velocity로 변환해 주어야 한다. VLM이 언어를 출력하면 보행 정책(Locomotion Policy)이 구체적인 숫자로 바꾸어 준다.
| 언어 출력 | 속도 명령(로봇 제어 입력) |
|---|---|
| move forward | 0.5 m/s (앞으로 0.5m/초) |
| turn left | +π/6 rad/s (왼쪽으로 30°/초 회전) |
| turn right | −π/6 rad/s (오른쪽으로 30°/초 회전) |
| stop | 0 (이동·회전 중단) |
또한 VLM은 거리나 각도와 같은 continuous value도 함께 출력하는데,
- move forward for 2 meters
- turn left by 45 degrees
그러면 속도 명령과 duration을 조합하면 된다.
Ex) forward movement
- 속도 = 0.5 m/s
- VLM 지시: 2m 전진
- 필요한 시간 = distance / speed = 2 / 0.5 = 4초
→ 4초 동안 0.5 m/s로 이동
Low-level Action and Observation Space
Locomotion Policy는 매 스탭바다 12개 관절의 목표 위치(desired joint position)을 출력한다.
- 왼쪽 앞 다리 힙 관절은 몇도 회전?
- 오른쪽 뒷다리 무릎은 몇도 회전?
관절의 목표 위치: 각 관절을 몇 도로 회전하고 싶은지를 나타내는 목표값
이 목표위치는 강성(stiffness), 감쇠(damping) 이 두 값을 이용해 실제 로봇 모터가 적용할 토크(torque)로 변환된다.
강성(stiffness): 관절의 목표 각도로 얼마나 강하게 당길지 결정
감쇠(damping): 움직일 때 관절이 흔들리지 않도록 제동을 거는 값
Locomotion Policy는 Proximal policy optimization algorithms알고리즘(정책기반 강화학습)을 사용한다.
로봇은 주변 지형 정보를 LiDAR 센서로부터 얻은 height map을 통해 인지한다.
Incorporating Height Map from LiDAR Point Cloud.

Unitree L1 LiDAR는 360° × 90°의 넓은 시야각(Field of View)을 가진 포인트 클라우드를 생성하며,
우리는 Supplementary(부록)에 제시된 파라미터들을 기반으로 이 데이터를 이용해 2.5D height map
을 구성한다.
각 voxel(격자)안에서 가장 낮은 z값을 바닥의 높이라고 가정하고 사용한다.
그러나 LiDAR 노이즈 때문에 급격히 낮은 값이 확 튀어나오는 경우가 있는데 이러면 height map이 구멍처럼 팍 꺼진 상태로 보인다. 이런 경우에는 Max Filter를 적용하여 매끄러운 height map을 구성한다.
Max Filter: 최근 5개의 스캔 값을 비교해서 그 칸에서 가장 높은 z값을 선택하여 보정한다.
Training
2단계(teacher–student) 학습 패러다임을 사용하는 것과 달리, 우리는 단일 단계(single-stage) 방식으로 보행 정책(locomotion policy)을 학습한다.
Isaac Lab의 ray-casting 기능 덕에 보행 정책을 강화학습하는데 RTX 4090 GPU에서 초당 60,000 프레임(FPS) 이상의 매우 높은 처리 속도를 달성한다.
Comment