
서론
이 장은 NLP에서 사용되던 Transformer에서 self-attention기반의 아키텍처가 Vision Task에 적용한 Vision Transformer에 대해 설명한다.
본 논문에서 ViT는 CNN보다 데이터셋의 갯수가 적을경우 Inductive Bias학습이 어려워 일반화가 어렵다는 단점이 있지만 충분한 데이터를 가지고 학습할 경우 CNN보다 좋은 성능을 보인다고 한다.
목차
DataSet
Pre-train
LLSVRC-2012 ImageNet, ImageNet-21K, JFT의 데이터셋을 학습에 활용
Transfer Learning
ImageNet, CIFAR 10/100, Oxford-IIT Pets 데이터셋을 활용
Training
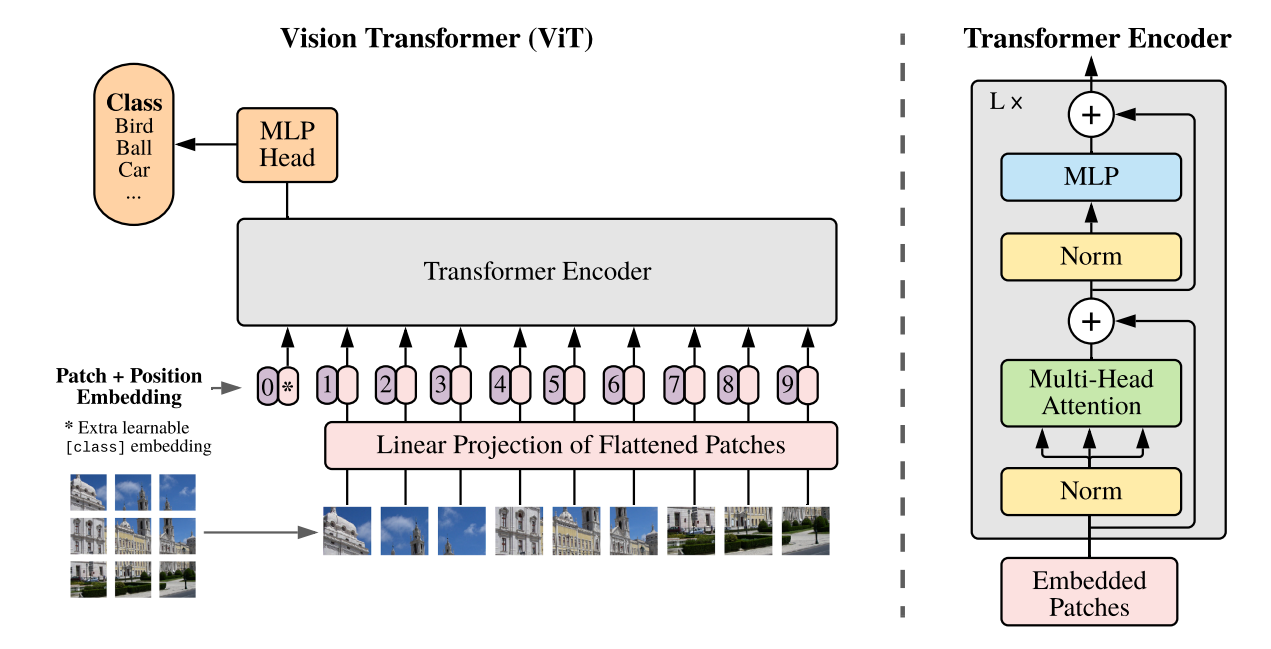
- 이미지를 고정된 크기(e.g. 16x16)의Patch로 분리하고 Flatten을 통해 1-Dimension Vector로 나열한다.
- ViT-L/16 means the “Large” variant with 16×16 input patch size
- 1-Dimension Vector에 위치 정보를 담고있는 Position Embedding과 클래스 분류를 위해 Bert에 사용된 CLS토큰처럼 해당 이미지의 class정보를 담고있는 classification Token을 더해준다.
- 2번에서 나온 각 vector들을 Transformer Encoder의 input으로 들어간다.
- MLP Head로부터 class를 분류한다. (Fine-tuning시 MLP Head를 downstream task에 맞게 수정한다)
Training Parameter Details
- Adam Optimizer ( \(\beta_1=0.9, \beta_2 = 0.999)\)
- Batch_size = 4096
- Overfiting 억제를 위한 Weight Decay 적용
Fine-Tuning
- Pre-Trained 보다 더 높은 해상도로 Fine-Tune 하는 것이 성능에 도움
- Path size는 동일한 반면 더 많은 정보를 닮은 Sequence를 생성
- Pre-Trained된 Prediction Head를 제거하고 0으로 초기화된 \(D\times K\)차원의 Feedforward layer 붙인다.(K→ Number of downstream classes)
- Optimizer → SGD with momentum, batch_size = 512
Hybrid Architecture Model
CNN의 Feature map을 적용한 방법으로
CNN의 output인 feature map을 flatten하여 Transformer의 Input으로 사용
ViT 연구
ViT는 많은 양의 데이터셋에서 Pre-Train을 했을 때 잘 작동함을 아래 그래프로 보여주고 있다.
- JFT-300M인 큰 데이터 셋으로 갈 수록 정확도가 상승함
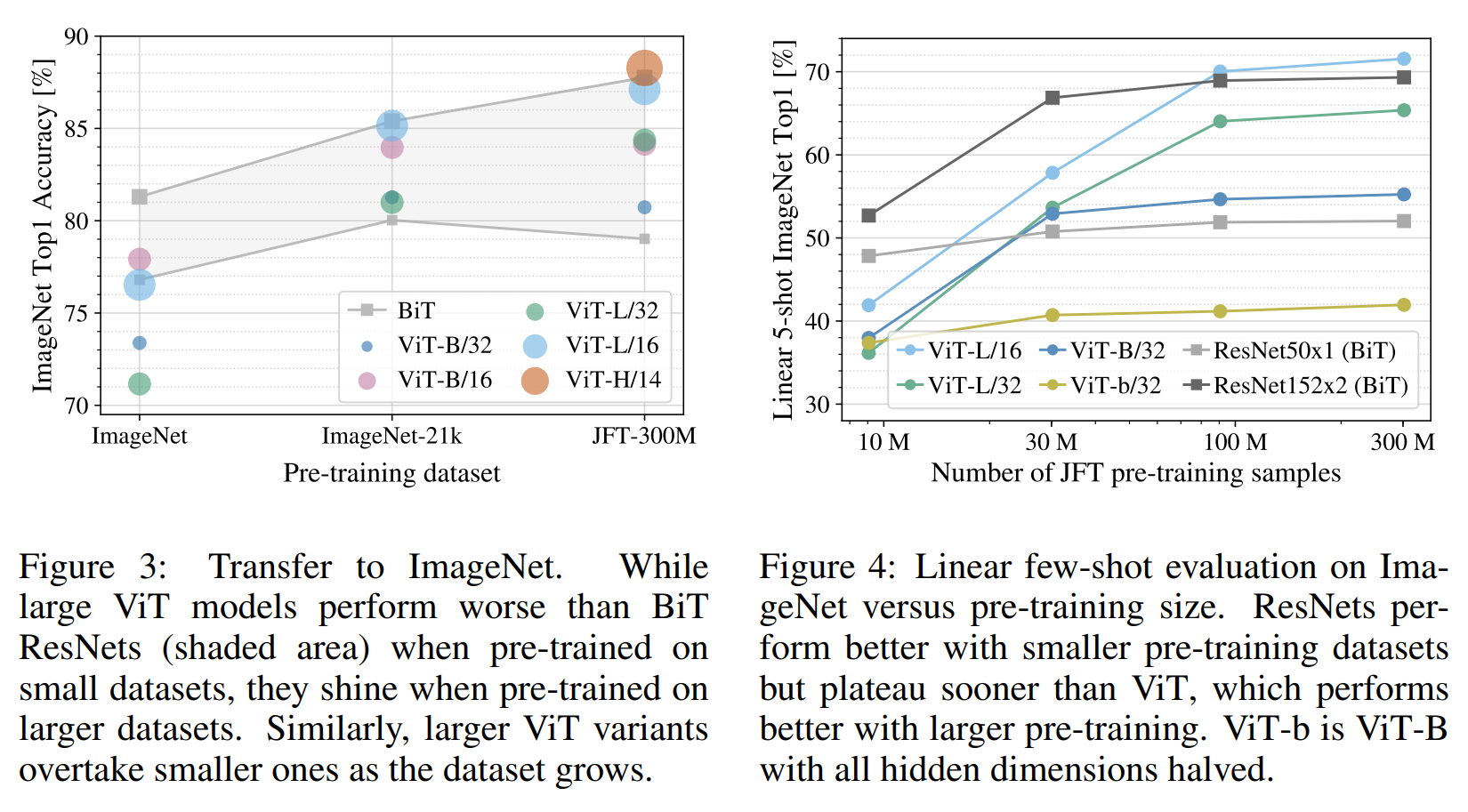
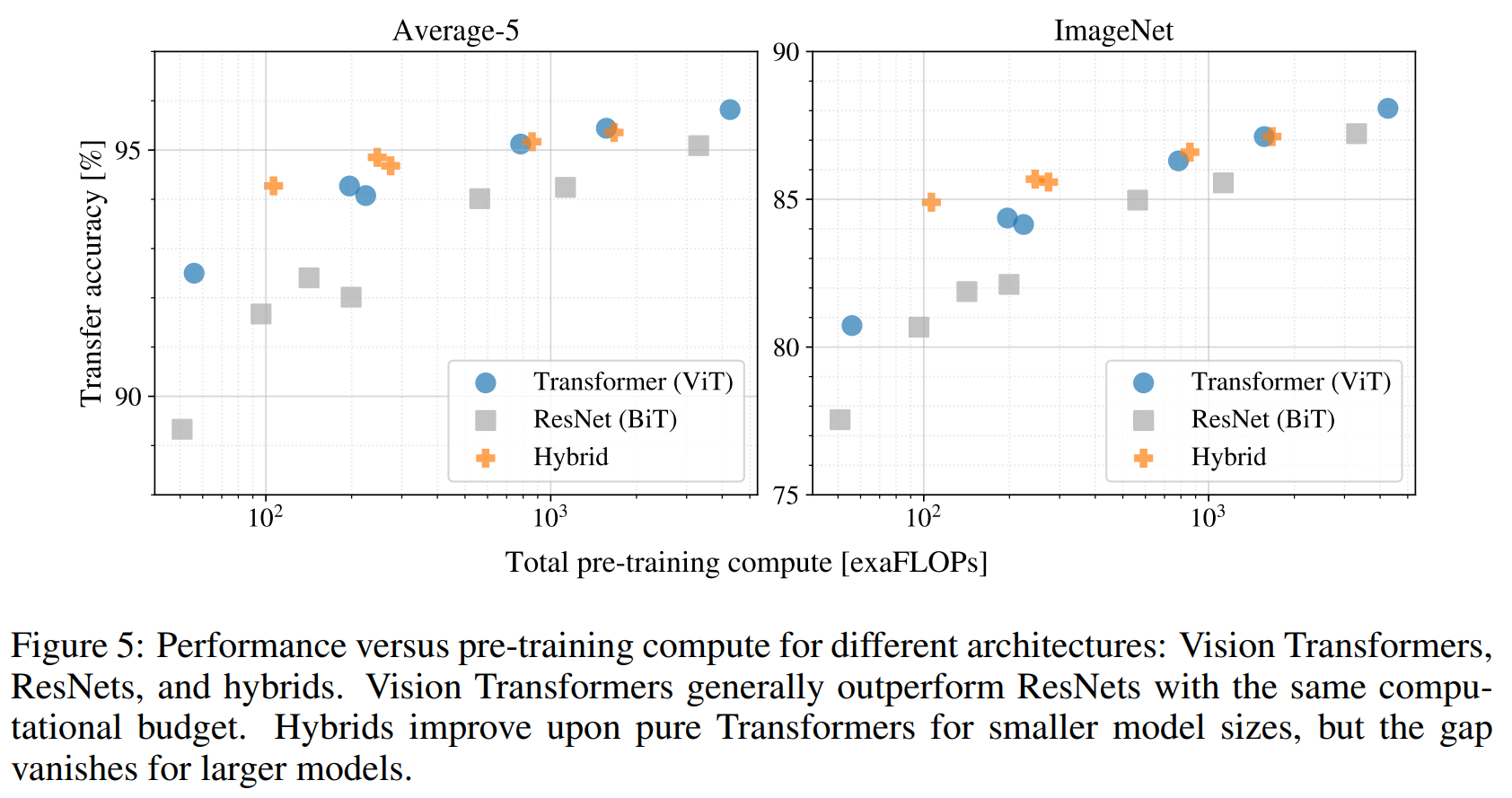
Figure 5
JFT-300M Dataset으로 Pre-Train 이후, Transfer learning 성능평가를 수행함에 있어 각 모델의 performance 대비 pre-training cost를 평가
- ResNet 7개, ViT 6개, Hybrid Architechure Model 5개의 모델을 평가
- ViT는 ResNet보다 동일한 성능을 내기 위해 Computing Cost 두배이상 적다.
- Hybrid Architechure Model 성능이 ViT를 능가하지만 ViT의 모델 크기가 커지면서 차이가 없어짐
- ViT는 실험을 시도해본 range 내에서 saturated 되지 않았다.
아래 그림을 보면 Attention은 이미지의 Class정보와 관련있는 영역에 주의를 기울인다는 것을 확인함
We find that the model attends to image regions that are semantically relevant for classification.

Figure 7
- 맨 왼쪽은 RGB값에 대한 Embedding을 초기화한 필터로 많은 데이터를 가지고 학습한다면 CNN Filter와 비슷한 기능을 보임
- 가운데는 각 이미지 patch들에 대해서 Position Embedding을 추가
- 가까운 Patch간의 유사도가 높다 → Input Patch간의 공간정보가 잘 학습
- Layer가 깊어질 수록
- 맨 오른쪽은 네트워크가 이미지를 전체적인 정보를 얼마나 수용하는지를 보여줌
- Attention Distance는 CNN에서의 receptive field size와 유사한 개념
- 층이 깊어질수록 Attention Distance가 증가
- 정보를 global하게 integrate할 수 있는 능력을 모델이 실제로 사용하고 있음

Self-Supervision
- NLP Task에서 수행되는 Self-supervision 학습 방법을 시도
- 예를 들어, BERT는 Input을 Masking후, Masking 한 단어를 올바르게 예측하도록 학습(Self-Supervised Learning)
- Vision Self-Supervision 결과
- Smaller Model ViT-B/16은 79.9 % 정확도를 보여 우수함
- 하지만, Supervied Learning 방식보다 정확도가 4% 낮음
Conclusion
- Large Dataset(JFT-300M(3억))에서 잘 동작
- PreTrain cost가 상대적으로 저렴함
- 추가적인 연구 필요
- Detection, segmentation task, self-supervision
- Scaling 여지가 남아있어 추가적인 성능 향상
- e.g. 대표적인 scaling방법은 model의 width, depth, resolution 을 증가
- 이를 적용한 것이 Scaling Vision Transformers
[참조]
Comment