
Variation Inference(VI, ELBO)
복잡한 데이터를 이해하고싶어 어떤 요인들이 관측값(데이터)들에 영향을 주는지 알고 싶다. 즉 우리가 보는 데이터가 왜 그렇게 나왔는지 숨은 원인을 알고 싶은 것. (데이터 x가 주어졌을때 숨은 요인 z가 어떻게 나오는지를 알고싶음 p(z|x))
그런데 p(z|x)의 실제 정답은 복잡한 다봉분포처럼 생겼다.
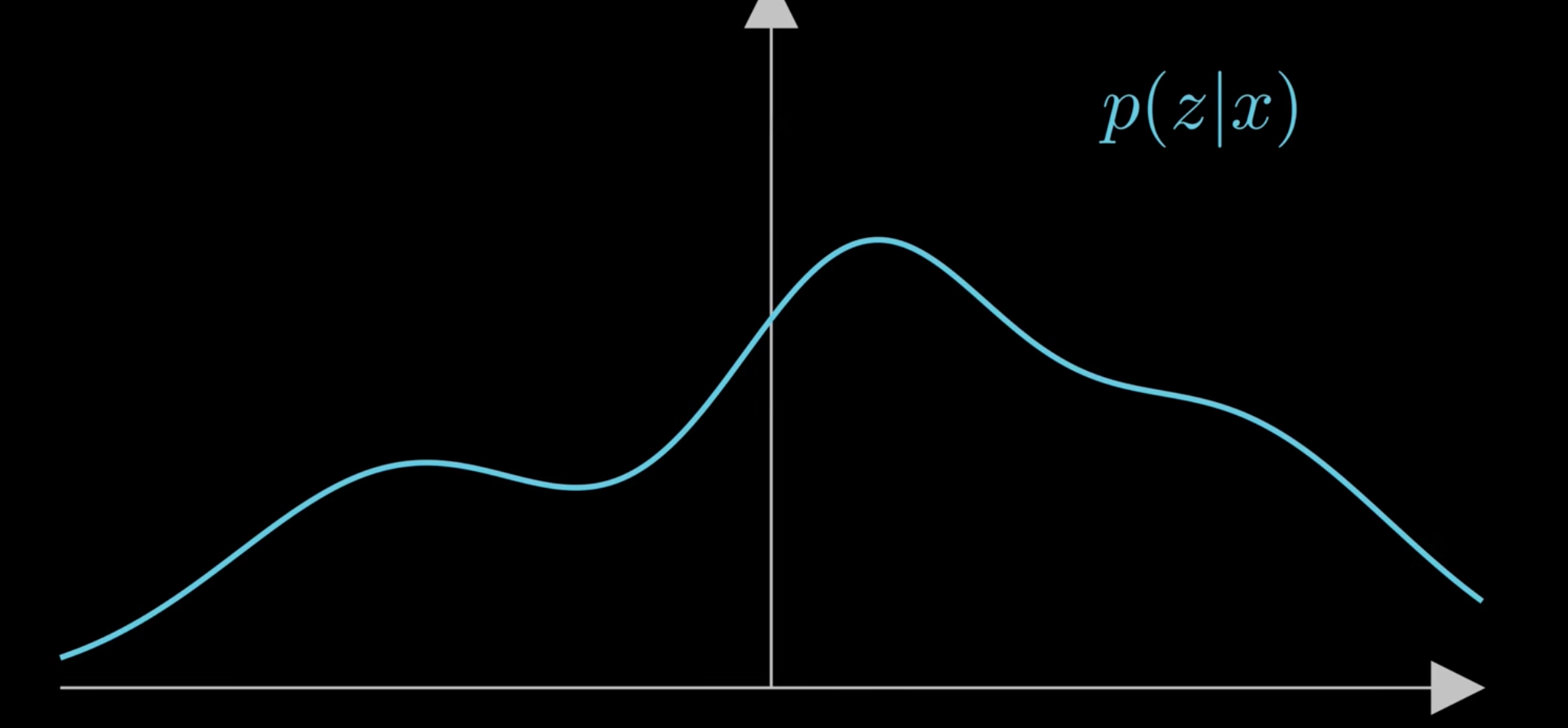
그래서 정확한 분포를 그대로 계산하려면 너무 복잡하다.
이러한 복잡한 분포중에서 중요한 정보를 대부분 담을 수 있는 단순한 분포를 사용할 수 있다면 어떨까? (예 가우시안 분포) 즉 복잡한 분포를 단순한 정규분포로 근사하자는 아이디어이다.
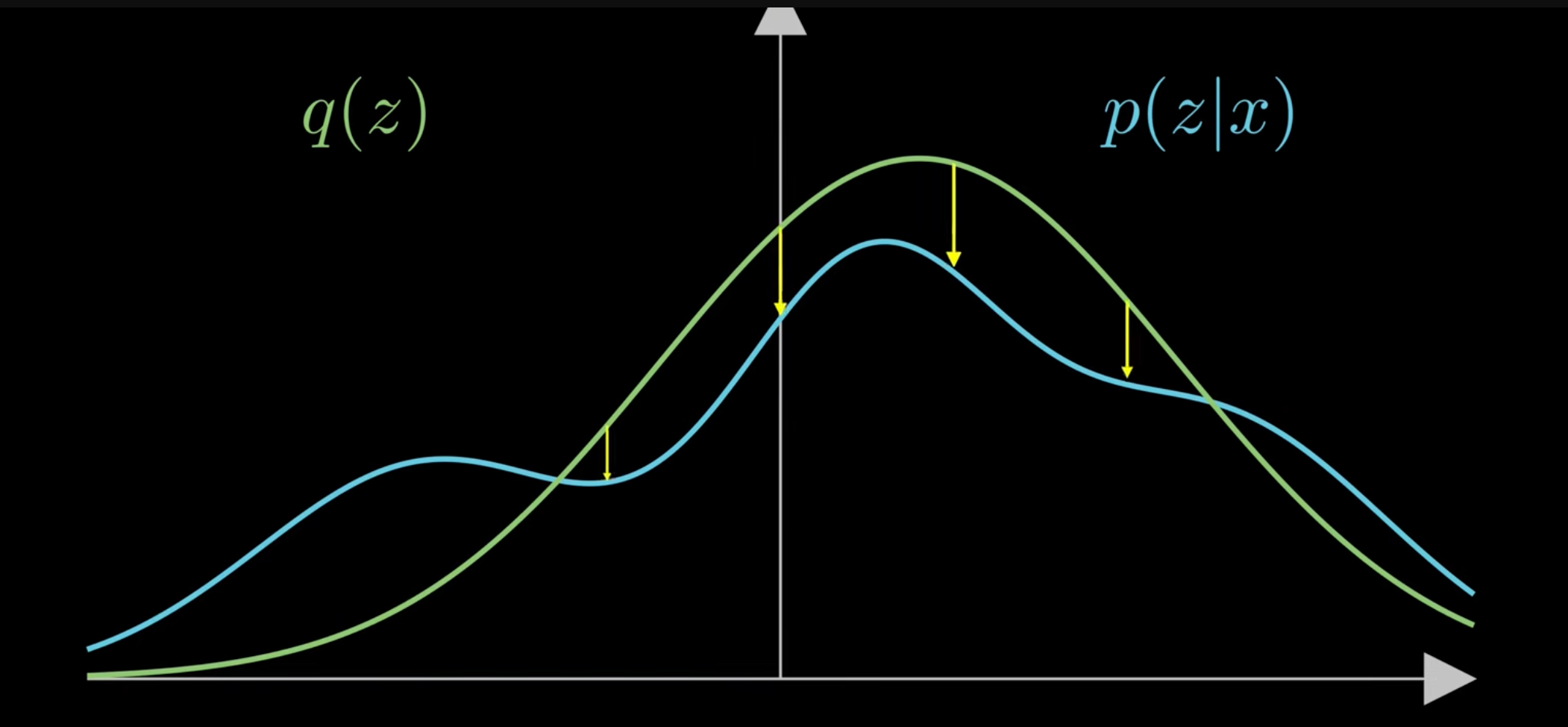
이것이 바로 변분추론(Variational inference)이다.
따라서 핵심은 가능한 가장 좋은 근사분포를 어떻게 찾을 것인가?
이것이 왜 필요한가?
머신러닝과 통계에서는 이미지나 측정값처럼 직접 관측한 데이터를 자주 다루며, 이를 X라고하자
그리고 직접 관측할 수는 없지만 데이터에 영향을 주는 어떤 잠재변수가 있으며, 이를 Z라고 하자
예를 들어 이미지(X)가 데이터라면 잠재 변수는 사진이 찍힌 각도(Z) 등이 있다.
우리의 목표는 사후분포 P(Z|X)를 구하는 것 입니다.
이는 관측된 X가 주어졌을 때 어떤 Z 값들이 그럴듯한지를 알려준다.
즉, 데이터를 보고 그 데이터를 만든 숨은 원인이 무엇일지 추정하는 것이다.
P(Z|X)를 구하기 위해 베이즈 정리에 따르면 다음과 같이 쓸 수 있다.
사후분포 = 우도 × 사전분포 ÷ 증거로 계산된다.
수식은 간단해 보이지만 계산이 쉽지 않다
왜냐하면 분모 P(X)를 구하려면 잠재변수 Z가 가질 수 있는 모든 값에 대해 적분해야 하기 때문입니다.
가능한 모든 숨은 원인을 다 고려해서 더해야하고 차원이 많아지면 이 적분은 계산적으로 거의 불가능해진다.(Z값이 너무 많아서)
여기서 변분 추론의 핵심 아이디어가 등장한다. 이러한 사후분포를 직접 계산하는 대신, 실제로 다룰 수 있는 더 단순한 분포 q(Z)로 근사합니다. (예를들면 q(Z)는 가우시안, 지수분포, 감마분포 처럼 단순한 분포라고 가정한다)
이러한 분포를 우리가 선택하면 사후분포에 최대한 가까운 Q분포의 파라미터를 찾아야한다. 그러기 위해서는 먼저 어떤 분포인지 선택해야 한다. 예를들어 X가 이미지이고 Z가 촬영각도(우리가 정함)라면 [-무한대, 무한대]의 범위를 설정하면됨으로 정규분포로 선택한다. 즉, z의 서포트를 기준을 기준으로 q분포를 설정한다.
이러한 파라미터를 찾기위해 정답 사후분포와 Q 확률분포가 얼마나 유사한지를 측정하기 위해 KL divergence를 사용한다. (그리고 그 분포에서의 파라미터를 건들여서 정답 사후분포의 모양과 최대한 유사하게 만드는 것)
KL divergence를 계산하기 위해선 구하기 어려운 정답 사후분포인 P(Z|X)가 필요하다.
이를 베이지안 룰을 사용하면 다음과 같이 바꿀 수 있고
q분포를 바꿔가며 정답 사후 분포에 근사해야함으로
다음과 같이 L(q)함수를 정의하자. 이를 ELBO라고 한다.
또는 아래와 같이 풀이하는 것도 가능하다.
여기서 \(- \mathbb{E}_q[\log q(z)]\) 는 Entropy로 우리가 control해야 하는 부분이고 \(\mathbb{E}_q[\log p(x, z)]\)부분은 우리가 모델로부터 얻을 수 있는 값이다.
\(p(z)\)는 잠재변수 z에 대한 prior distribution이다.
- 따라서 우리가 z의 support를 바탕으로 z의 분포를 결정해주면된다.
- 베이지안 추정에서는 likelihood와 conjugate 관계에 있는 사전분포를 선택하면 posterior 계산이 쉬워진다. 하지만 항상 conjugate prior를 써야 하는 것은 아니다.
- 일반적으로 계산이 쉽고 해석이 편한 표준정규분포로 z~N(0, 1)를 많이 사용한다.
\(\log p(x|z)\)는 우도이다.
- 여기서는 우도를 observation x의 특성과 support를 바탕으로 분포를 결정한다.
- 예를들어 정규분포 \(N(\mu, \sigma^2)\)를 설정하고 이 분포의 parameter는 데이터 x에 대하여 신경망을 통해서 구한다.
따라서 ELBO는 계산이 가능하다.
위 처럼 정의하면
처럼 되서 ELBO는 p(x)의 Lower bound의 조건이 된다.
L(q)가 제일 클 때 좌측 KL Divergence가 최소가된다!
따라서 L(q)를 가장 크게 만드는 q를 찾으면(q를 가우시안 분포로 가정하면) 초기에는
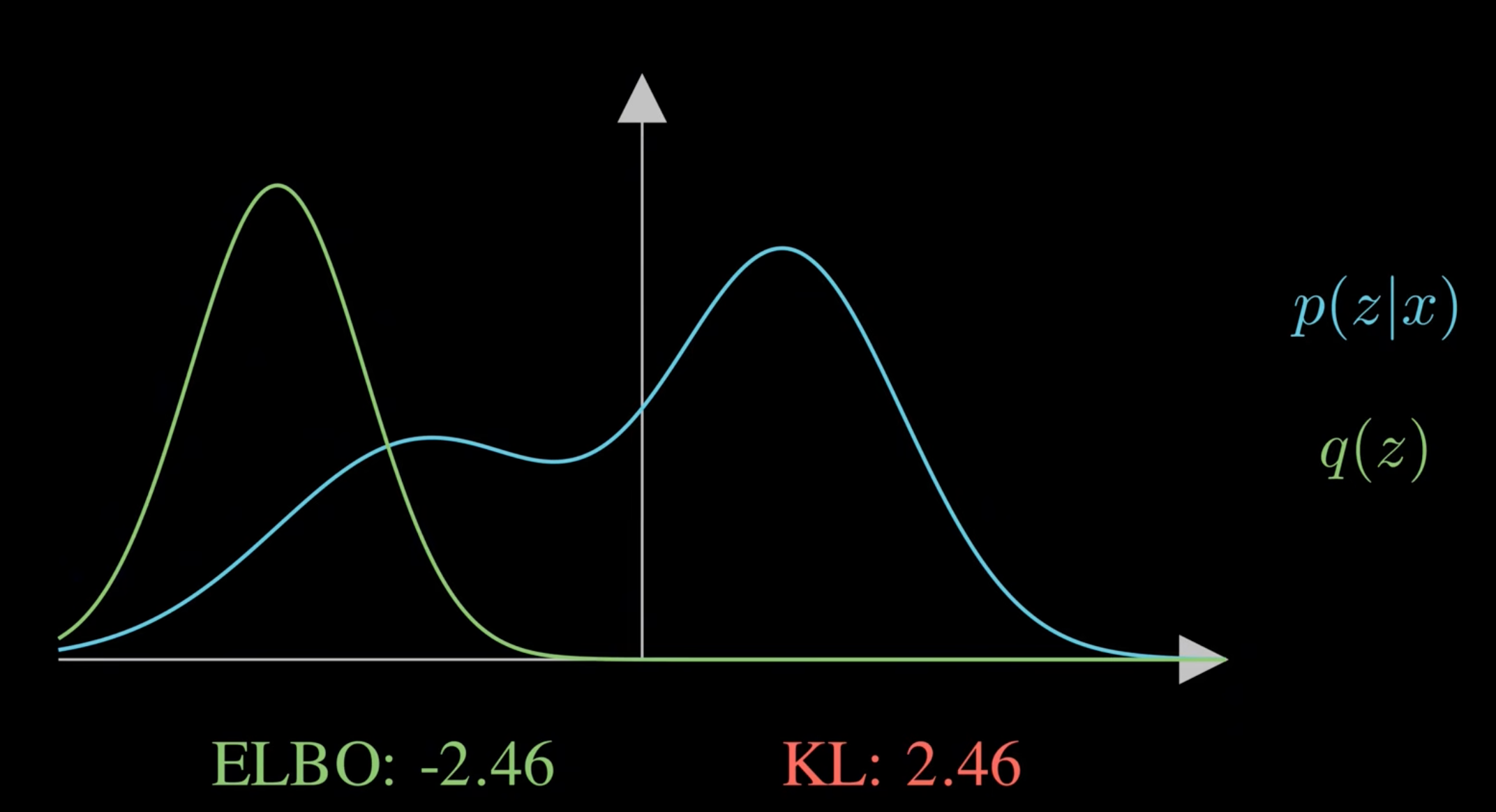
에서 KL을 줄여갈 수록
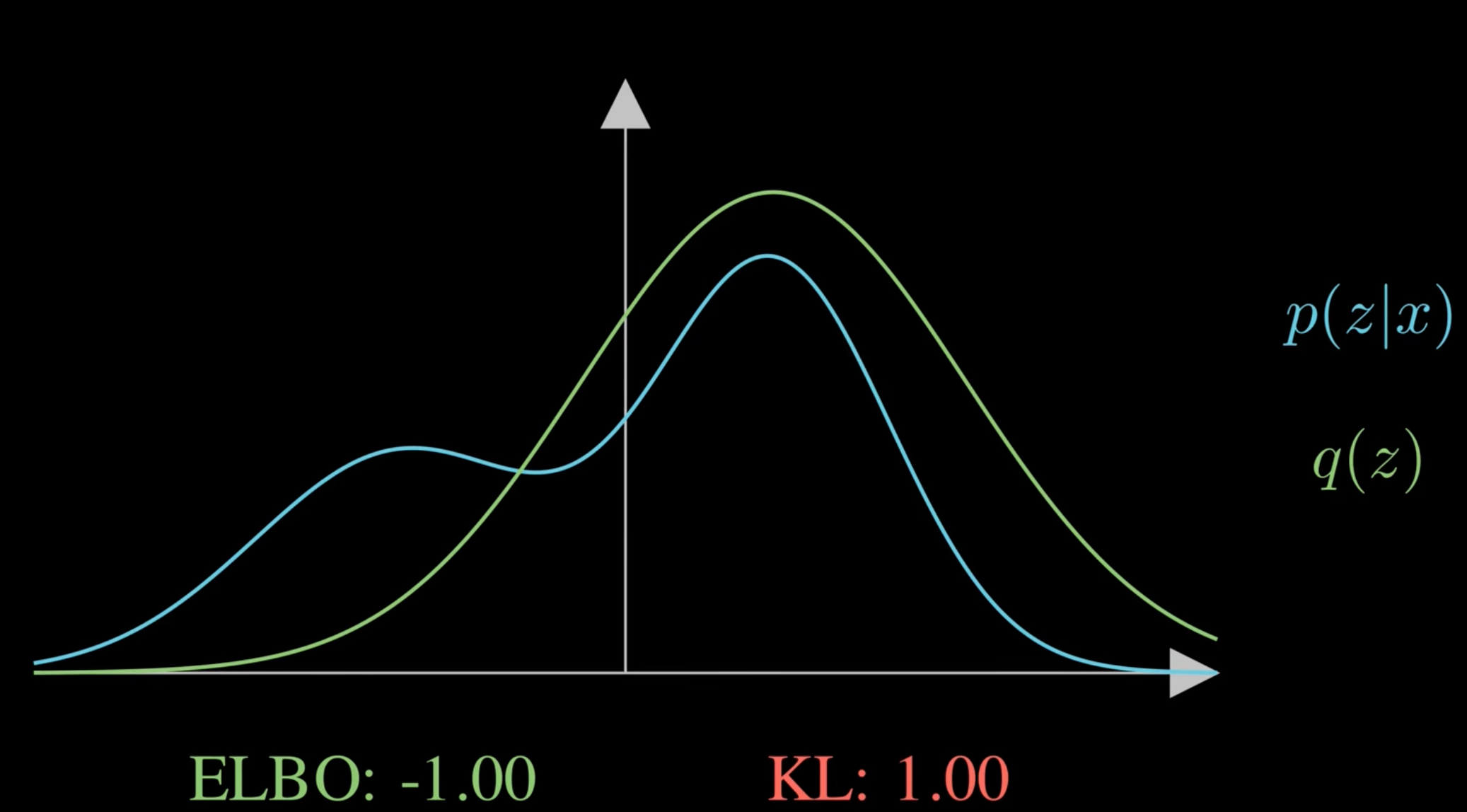
가 된다.
[reference]
Comment