
서론
기존 DDPG는 성능의 단조개선(Monotonic Improvement)가 이론적으로 보장되지 않았다.(목적함수 \(J(\theta)\))가 매 iteration마다 증가한다는 보장이 없다.)
왜냐하면 Actor( \(\mu\) )가 Ciritic(Q 함수)의 gradient를 따라가도록 학습하는데 critic 자체도 학습중이라 부정확하다.
또한 Gradient는 현재 시점에 대한 선형근사 정보(한 점에서의 방향정보)뿐이여서 그 정보가 어디까지 유요할지 알 수 없다.(Step size를 모름)
이러한 문제를 해결하기위해 MM(Minimization - Maximization)알고리즘과 Trust Region Concept을 도입한다.
목차
- Trust Region
- Objective Function
- ㅇ
Trust Region
Trust Region 내부에서 정책파라미터 \(\theta\)를 업데이트하면 목적함수 \(J(\theta)\)의 단조개선이 이론적으로 보장된다.
이 Trust Region은 KL Divergence 제약조건으로 신뢰 영억을 정의한다.
그 영역 안에서는 Gradient 방향으로 이동해도 항상 성능이 개선된다는 것을 보장한다.
따라서 step-size를 고려하지 않고 Trust region영역안에서 가장 좋은 점으로 이동하면 된다.

Objective Function
- Maximizing the Expected Return
- \(s_0,\;a_0,\;...\): 주어진 Policy(\(\pi\))에 의해 만들어진 모든 에피소드에 대하여
- \(\sum_{t=0}^{\infty} \gamma^{t} r(s_t)\): 단일 에피소드에 대한 return 값
- 모든 에피소드에 대하여 받을 수 있는 보상의 기대값을 계산함
- 목적함수의 의미는 수식 (1)와 같으나 실제로는 아래 수식(2)를 통해서 \(\eta(\pi)\)를 구한다.
[증명]
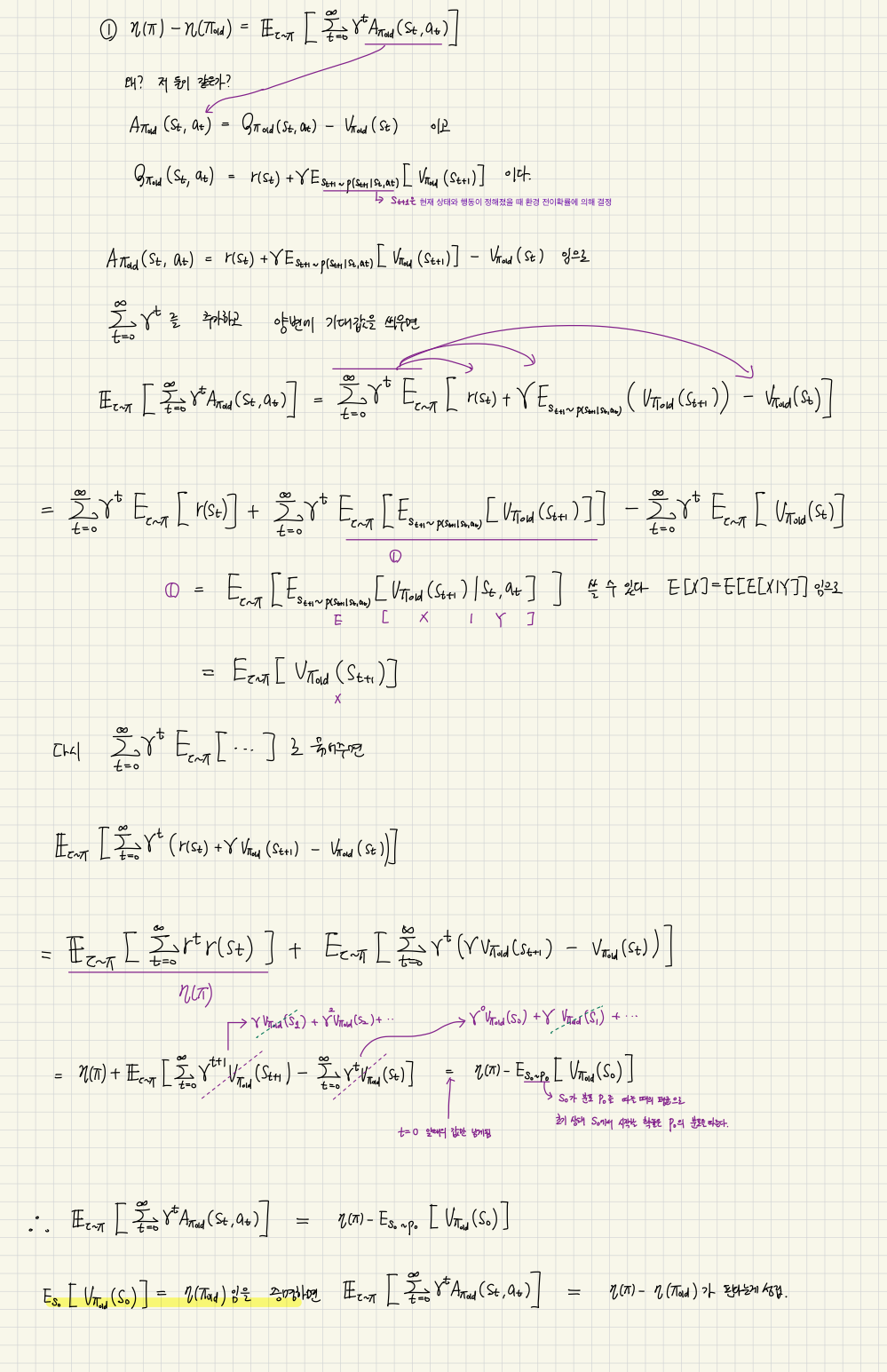


- 그리고 수식(3)번 처럼 변경할 수 있다.
State Visitng Frequency
- \(\rho\)는 각 상태를 얼마나 방문하는지에 대한 방문 빈도이다.
[증명]

Statue Visiting Frequency를 곱하는 이유
- \(G_t\)는 실제 trajectory를 따라가며 얻은 보상의 누적 합이다.
- 따라서 같은 상태를 여러 번 방문하면 그때마다 보상이 return에 반영된다.
- \(V_{\pi}(s),\;Q_{\pi}(s,\;a)\)는 상태 s에 이미 도착한 이후의 평균 return이다.
- 따라서 그 직후 trajectroy의 방문 빈도는 포함하지만, 처음 시작 상태에서 s까지 얼마나 자주 도착하는지는 포함하지 않는다.
- [Example]
- 정책 \(\pi\)가 아래처럼 행동한다고 해보자
- \(s_0\) → A : 99%
- \(s_0\)→ B : 1%
- 이때 B를 거쳐가야만 G에 도달가능하고 G에 도달한 경우 보상을 크게 받는다고 하자.\[V_{\pi}(G) = 100\]
- 만약 각 상태에서 받을 보상의 평균만 계산했다면 방문빈도는 계산되지 않아 마치 A, B 둘다 동일한 가중치로 방문한다고 가정하고 계산하는 것임으로 실제로는 오차가 생길 수 있다.
- 정책 \(\pi\)가 아래처럼 행동한다고 해보자
- [Example]
Objective Function의 의미
- \(\mathbb{E}_{\tau \sim \pi}\left[\sum_{t=0}^{\infty}\gamma^tA_{\pi_{\text{old}}}(s_t,a_t)\right]=\sum_s \rho_\pi(s) \left[ \sum_a \pi(a|s) Q_{\pi_{\text{old}}}(s,a) - V_{\pi_{\text{old}}}(s) \right]\)
- \(\eta(\pi_{\text{old}})\): 상태 s에서 어떤 행동 a를 한 번 시도해보고 그 이후에는 옛 정책(\(\pi_{old}\))를 따랐을 때의 가치
- \(\pi(a|s) Q_{\pi_{\text{old}}}(s,a)\): 상태 s에서 새 정책 \(\pi\)를 따라 한 번 행동을 고르고 그 이후에는 옛 정책(\(\pi_{old}\))를 따라 간다. 이렇게 했을 때 첫 스탭에서 새 정책 \(\pi\)에 의해 결정되는 모든 행동 에 대한 기대값
- Law of Total Expectation 적용
(because \(\mathbb{E}[X]=\mathbb{E}[\mathbb{E}[X|Y]]\))
- 텔레스코핑 합(Telescoping sum)
먼저 첫 항은
이고, 나머지 두 항은
(모든 항이 소거되고 \(t=0\)의 항만 남음)
- 최종 결론
따라서
또한 \(\mathbb{E}_{S_0\sim\rho_0}[V_{\pi_{old}}(S_0)] = \eta(\pi_{old})\) 이므로
Comment