
Cite
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, Peter Gehler; arXiv preprint arXiv:2106.08265, 2022.
- https://arxiv.org/abs/2106.08265
- 출간일: 2021. 06. 15
Abstract
이상 탐지 분야에서는 비정상 데이터를 구하기 어려운 경우가 많기 때문에, 정상 데이터만을 사용해 학습하는 (cold start) 상황에 적합한 이상 탐지 모델인 PatchCore를 제안합니다.
PatchCore는 ImageNet에서 사전 학습된 정보와 이상 탐지 모델을 결합한 모델입니다.
이를 위해, 이미지를 작은 패치들로 나누어 각 패치의 특징을 메모리 뱅크에 저장하고, 나중에 새로운 이미지가 들어왔을 때 이 메모리 뱅크와 비교하여 이상을 탐지합니다.
이 방법을 사용해 높은 속도와 정확도를 동시에 달성합니다.
Introduction
기존에는 오토인코더나 GAN과 같은 방법으로 정상 이미지 데이터를 사용해 모델을 학습시키는 방식이 주로 사용되었습니다.
최근 연구들에서는 모델을 특정 응용 분야에 맞게 추가 학습없이, 사전 학습된 모델의 표현을 바로 사용하는 접근법이 주목받고 있습니다.

- 위 이미지는 MVTec AD 데이터셋에 PatchCore를 적용했을때의 결과이며 주황색 선이 이상탐지 영역을 표시한 부분입니다.
문제점
High-Resolution Feature
미세한 결함 탐지는 고해상도 특징(high-resolution features)에서 이루어지기 때문에 문제가 없습니다.
이는 고해상도 특징 추출이 저수준 계층에서 이루어지기 때문입니다.
저수준 계층은 딥러닝 모델의 여러 레이어 중 입력 이미지에 가까운 초기 계층을 말하며, 여기서 이미지의 엣지, 코너, 텍스처와 같은 기본적인 패턴들을 감지합니다.
이러한 저수준 계층에서는 fine-tuning이 이루어지지 않더라도 미세한 결함을 감지하는 데 큰 문제가 없습니다.
→ 엣지 코너 텍스처와 같은 특징들은 이미지에 가까운 초기 계층에서 감지된다
High-level abstraction
반면, 이미지 전체에 나타나는 전반적인 결함 탐지에는 훨씬 더 추상적인 수준의 특징들이 사용됩니다.
이러한 특징들은 고수준 계층에서 추출되며, 고수준 계층은 딥러닝 모델의 중간 및 상위 레이어에 위치합니다.
이 계층들은 저수준 계층에서 감지된 기본적인 패턴을 결합하여 더 복잡하고 추상적인 표현을 생성합니다.
이를 통해 이미지의 전체적인 구조나 형태를 인식하고, 큰 결함이나 구조적인 이상을 탐지합니다.
그러나 이러한 추상적인 특징들은 특정 응용 분야에 맞게 fine-tuning이 이루어지지 않으면, ImageNet에서 학습된 추상적인 특징들이 산업 환경에서 요구되는 추상적인 특징들과 차이가 발생하게 됩니다.
따라서 fine-tuning되지 않은 ImageNet의 고수준 계층에서 추출된 특징들은 산업 환경에서 요구되는 추상적인
특징들을 제대로 표현하지 못합니다.
이로 인해, 결함 탐지를 위해 비교할 수 있는 정상적인 패턴이나 맥락이 부족하여, 모델이 결함을 정확하게 탐지하는 데 어려움이 생깁니다.
해결방안 및 제안
본 논문에서는 이러한 문제를 해결하기 위해 다음과 같은 접근법을 제안합니다:
- 결함 탐지의 정확도를 높이기 위해, 사전 학습된 모델에서 추출한 특징에 Average Pooling을 적용하여 정상적인 패턴이나 맥락에 대한 정보를 최대화 합니다.
- 산업 환경에서 다양한 결함을 탐지할 수 있도록, pretrained network에서 mid-level feature를 활용해 ImageNet에서 학습된 클래스에 대한 편향을 줄입니다.
- 실시간으로 빠른 추론을 가능하게 하기 위해, 추론시 비교해야 할 대상들을 coreset sampling 기법으로 선택하여 높은 추론 속도를 유지합니다.
Method
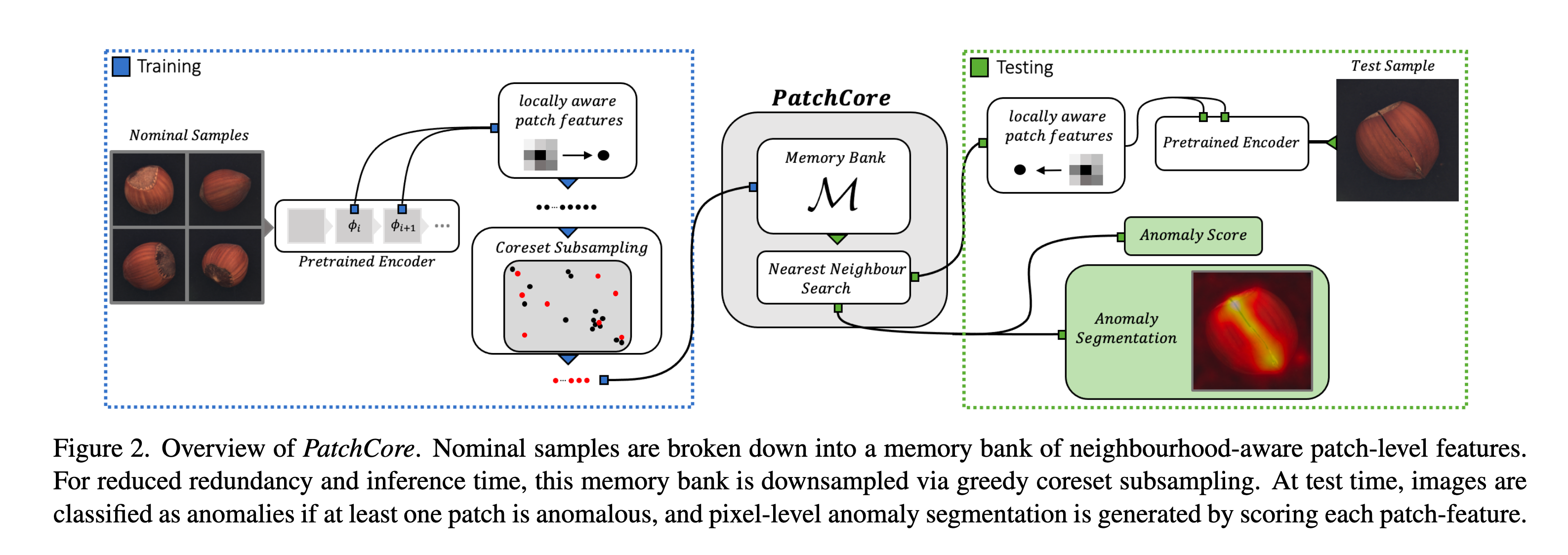
Training 과정:
- 모델은 사전 학습된 네트워크(pretrained network)를 사용하여 이미지에서 특징(feature)을 추출합니다.
- 이 특징들은 주변의 다른 패치들과의 관계를 고려한(locally aware하게)패치 특징으로 변환됩니다.
- 그런 다음, coreset 샘플링 기법을 사용하여 메모리에 저장할 중요한 패치 특징들을 선별합니다.
- 이는 사용하는 메모리 용량을 줄이며 추론 속도를 빠르게 합니다.
- 선택된 패치 특징들은 모두 메모리에 저장되며, 이후 테스트 단계에서 이상(anomaly)을 탐지하는 데 사용됩니다.
Test 과정:
- 학습 과정과 마찬가지로 사전 학습된 네트워크를 사용해 특징을 추출합니다.
- 이 특징들을 주변의 다른 패치들과의 관계를 고려하여(locally aware하게) 변환합니다.
- 그렇게 생성된 테스트 패치 특징은 메모리에 저장된 패치 특징들과 비교되어 이상 점수(anomaly score)를 측정합니다.
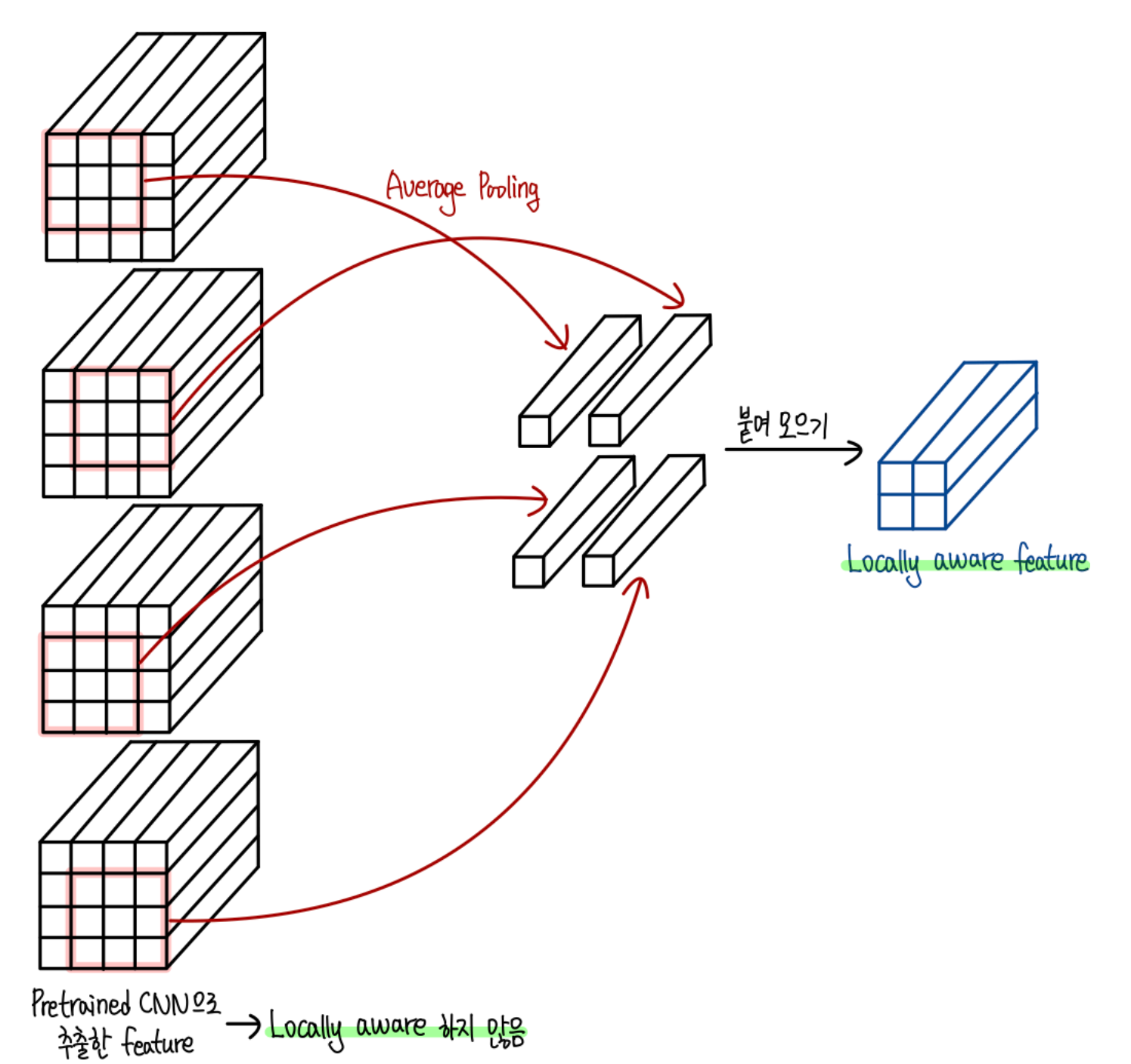
Locally aware patch feature
주변의 다른 패치들과의 관계를 고려하도록 패치 특징을 만들기 위해 average pooling을 사용합니다.
Mid-level feature
mid-level feature는 ImageNet 클래스 편향을 줄이고, 다양한 맥락을 고려하여 이상 탐지에 더 적합한 특징을 제공합니다
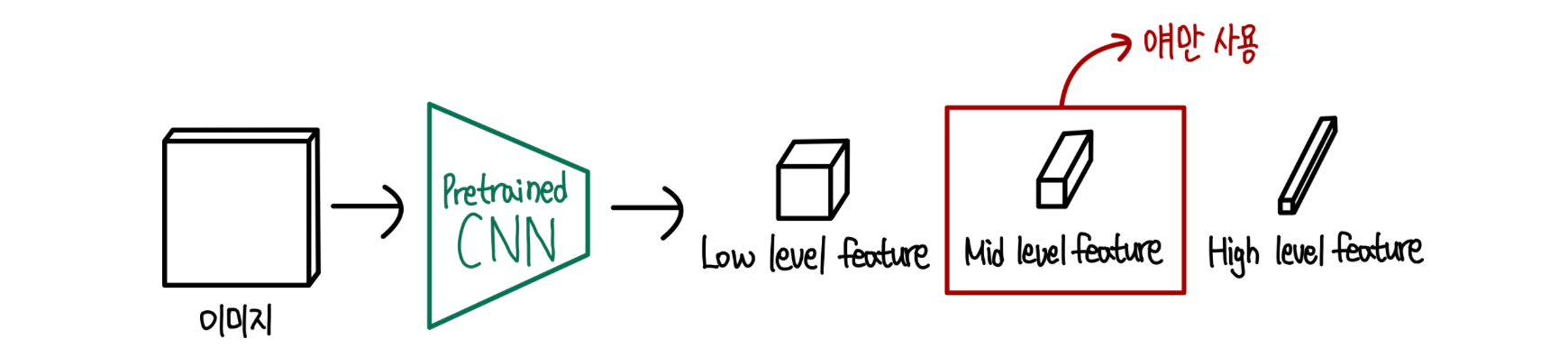
고수준 특징은 ImageNet과 같은 데이터셋에서 학습된 클래스에 지나치게 특화되어 있습니다.(편향되어 있음)
- 이는 산업 환경에서 요구되는 다양한 비정상 상태를 탐지하는 데 문제가 될 수 있습니다.
- 중간 수준의 특징은 이러한 편향을 줄여, 더 일반적인 특징들을 활용할 수 있게 합니다.
저수준의 특징은 이미지의 가장 기본적인 시각적 패턴(예: 엣지, 코너, 텍스처 등)을 포착합니다.(맥락이해 부족)
- 이러한 특징들은 매우 세부적인 정보에 집중되어 있어, 전체적인 맥락이나 구조를 이해하는 데는 한계가 있습니다.
- 중간 수준의 특징은 패치의 지역적 맥락과 전반적인 이미지 맥락을 모두 고려할 수 있습니다.
Coreset sampling
PatchCore에서는 메모리 뱅크를 만들 때 모든 패치 특징을 다 저장하지 않고, 일부만 선택해서 저장하는 coreset sampling 기법을 사용합니다.
이상 탐지를 위해 Nearest Neighbor 방법을 사용합니다. 이 방법은 테스트할 패치가 있을 때, 메모리에 저장된 모든 패치들과 하나씩 비교하여 가장 가까운(즉, 가장 유사한) 패치를 찾는 방식입니다.
따라서 메모리에 저장된 패치가 많을수록 비교해야 할 대상이 많아지기 때문에, 계산 시간이 그만큼 길어지게 됩니다.
따라서 계산 시간을 줄이기 위해 Coreset sampling방법을 사용하여 중요한 패치들만 선택해 메모리에 저장합니다.
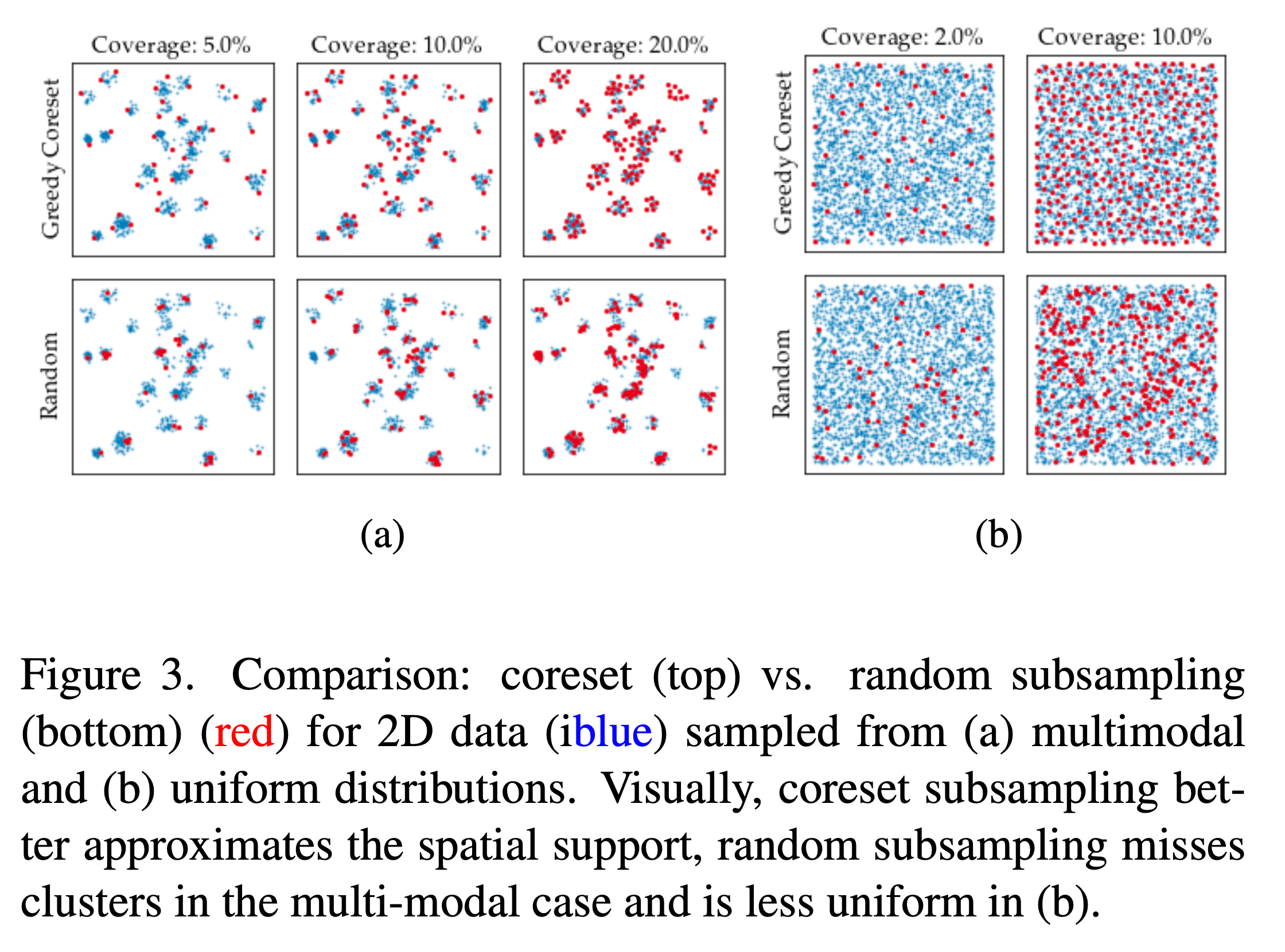
첫 번째행은 coreset sampling으로 샘플(빨강)들이 데이터 공간(파란) 전반에 걸쳐 고르게 퍼져있는 반면 두번째 행은 random sampling으로 데이터 공간에 전반적으로 뭉처진 결과를 볼 수 있습니다.
(a)는 Multimodal 분포, (b)는 uniform 분포에서 샘플링된 데이터(파랑)를 나타냅니다.
coreset sampling이 random sampling에 비해 데이터 분포를 더 고르게 잘 대표할 수 있음을 보여줍니다.
특히, 넓게 퍼져 있는 데이터 분포에서는 coreset sampling이 더 효과적으로 샘플을 선택하여 메모리 사용을 최적화하고, 결함 탐지의 정확성을 높일 수 있습니다. (다양한 특징들을 선택하기 때문)
Anomaly Score
최대 거리 스코어(Maximum Distance Score) 계산
추론시 이미지에서 추출한 각 패치의 특징을 메모리 뱅크에 저장된 정상 패치들의 특징과 비교합니다.
예를들어 추론 이미지의 왼쪽 상단에 있는 패치의 특징을 메모리 뱅크에 있는 모든 패치들과 비교하여 가장 유사한(가까운) 정상 패치를 찾습니다.
각 패치마다 메모리 뱅크에서 가장 유사한 정상 패치와의 거리를 계산하는데, 유사한 패치와의 거리가 가장 큰 것이 anomaly score를 계산하는데 사용됩니다.
이 점수가 높을 수록 비정상일 가능성이 높아집니다.
이웃 패치 간 거리의 가중치 부여
그러나 단순히 테스트(추론) 패치와 가장 가까운 정상 패치와의 거리만을 사용하는 것이 아니라, 가까운 여러 정상 패치들과의 거리를 모두 고려하여 anomaly score를 더 정교하게 계산합니다.
이 과정에서, 테스트 패치와 이웃 정상 패치들 간의 거리에 가중치를 부여하는 방식이 사용됩니다.
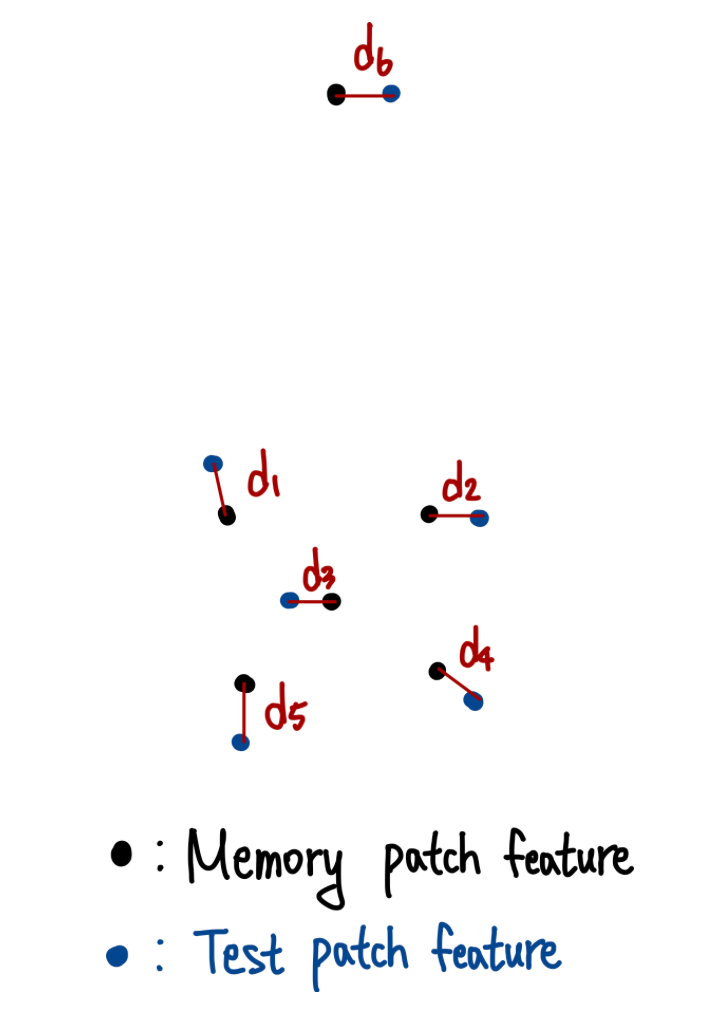
위 이미지를 보면 d1 ~ d5는 서로 이웃해 있는 반면에 d6는 멀리 떨어져 있는 것을 볼 수 있습니다.
이 의미는 비정상적으로 분포하는 정상 sample이라고 볼 수 있습니다.
이런 경우 그냥 측정한 거리보다 더 높게 가중치를 계산해줍니다.
위 이미지를 보면 d1 ~ d5 까지의 샘플들은 서로 가까이 모여 있는 반면, d6의 거리가 비록 작지만서도 해당 샘플은 다른 이들과 멀리 떨어져 있습니다.
d6처럼 정상 샘플이지만 다른 정상 샘플들과는 거리가 먼 경우, 이는 비정상적으로 분포된 정상 샘플로 볼 수 있습니다.
이런 경우, 단순히 거리를 계산하는 것만으로는 충분하지 않기 때문에, 이 거리에 더 높은 가중치를 부여합니다.
즉 메모리상의 다른 patch feature들과 멀리 떨어져 있다면, 더 큰 가중치를 주겠다는 의도입니다.
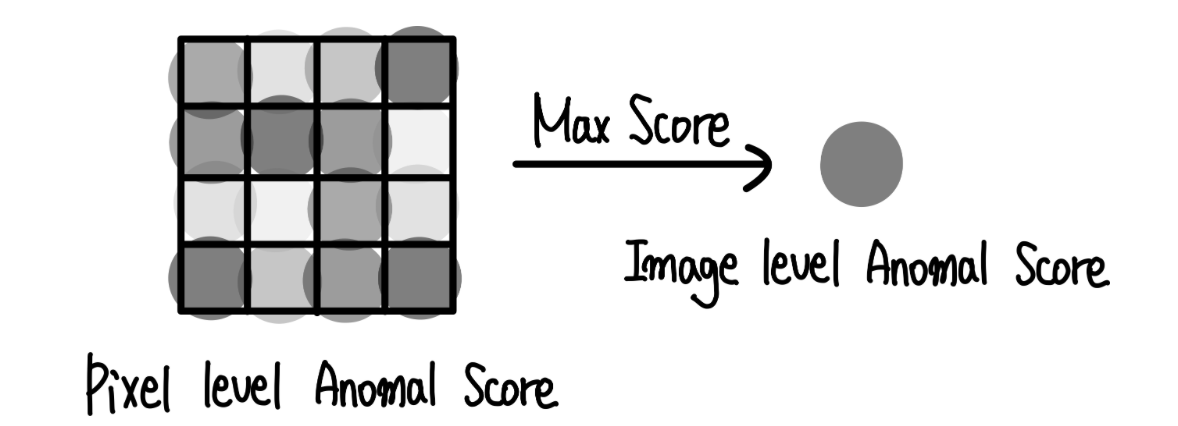
이렇게 계산된 픽셀레벨에서의 Anomaly score중 가장 큰 값이 해당 이미지의 anomaly score가 됩니다.
Experiments
아래 표는 MVTec AD 데이터셋을 가지고 실험한 결과 입니다.
25%, 10%, 1%는 coreset subsampling 과정에서 메모리 뱅크에 저장할 패치들의 비율을 나타냅니다.
예를들어 25%인 경우, 전체 패치 중에서 25%만 선택하여 메모리 뱅크에 저장합니다.
즉, 전체 정상 패치의 4분의 1만을 사용하여 anomaly score를 계산합니다.
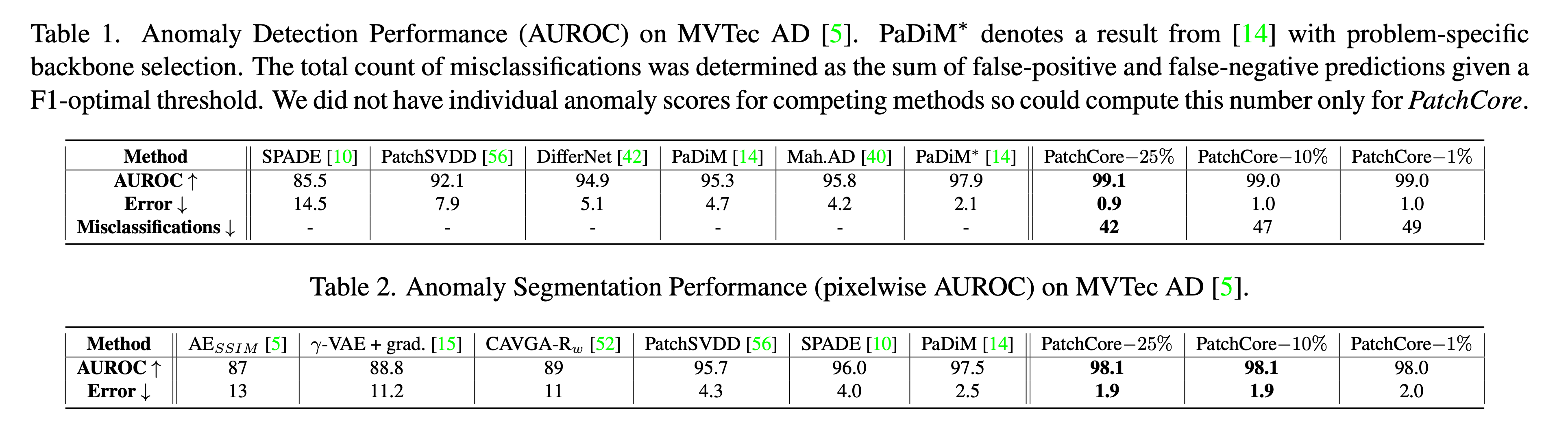
PatchCore - 25%: 1725개의 이미지들중 42개만이 잘못 분류(미탐 + 오탐)했고 전체 클래스의 1/3은 100% 맞추었습니다.
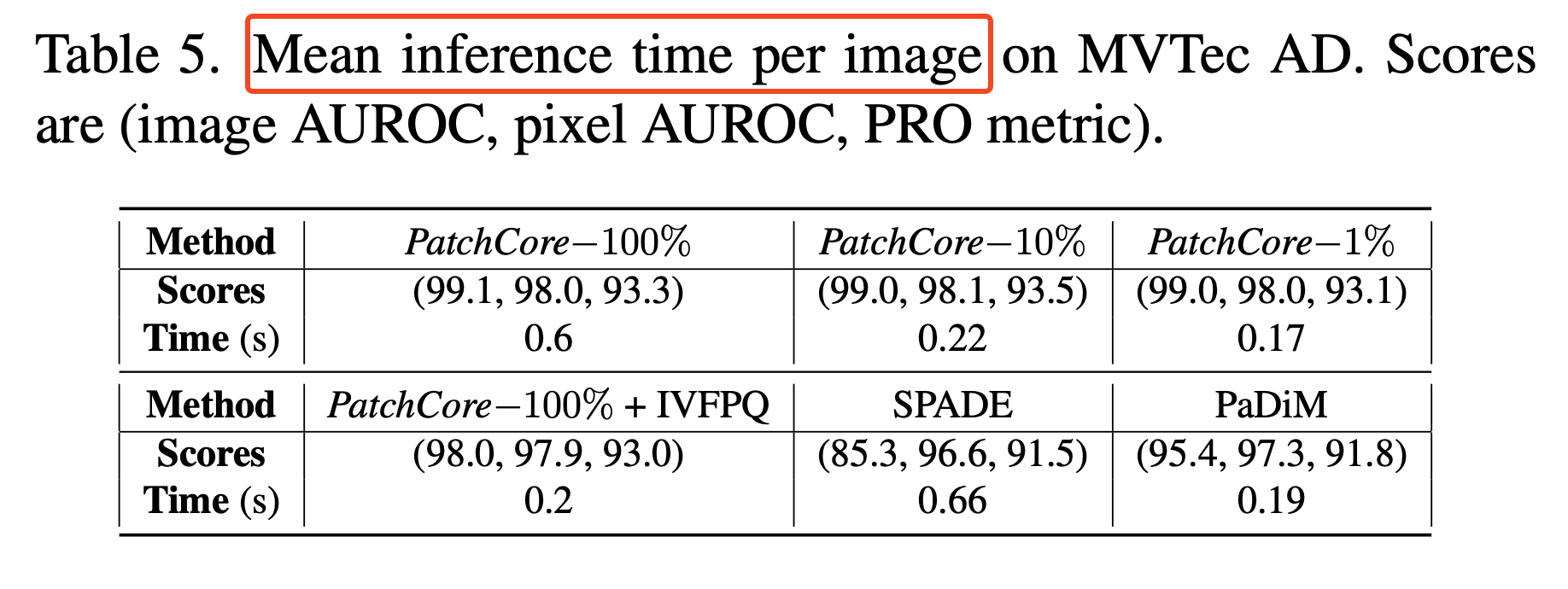
아래 이미지는 추론 속도에 대한 실험 입니다.
평가 지표는 이미지 한 장당 평균 추론 시간(s)와 Image AUROC, pixel AUROC, PRO metric을 사용합니다.
Without subsampling
- PatchCore−100%의 성능: 모든 데이터를 사용하여 추론하는 경우로, subsampling(샘플링)을 하지 않은 경우입니다.
With subsampling
- PatchCore - 10%, 1%는 coreset subsampling을 적용하여 추론 시간을 측정한 결과 입니다.
- subsampling을 통해 일부 데이터만 사용하면서도 PaDiM보다 더 빠르고, 여전히 최고 수준의 이미지 이상 탐지 및 분할(segmentation) 성능을 유지할 수 있습니다.
근사 최근접 이웃 검색 (approximate nearest neighbour search) 사용
- IVFPQ는 메모리 뱅크의 모든 패치들과 비교하지 않고 근사 최근접 이웃 방식을 사용한 결과 입니다.
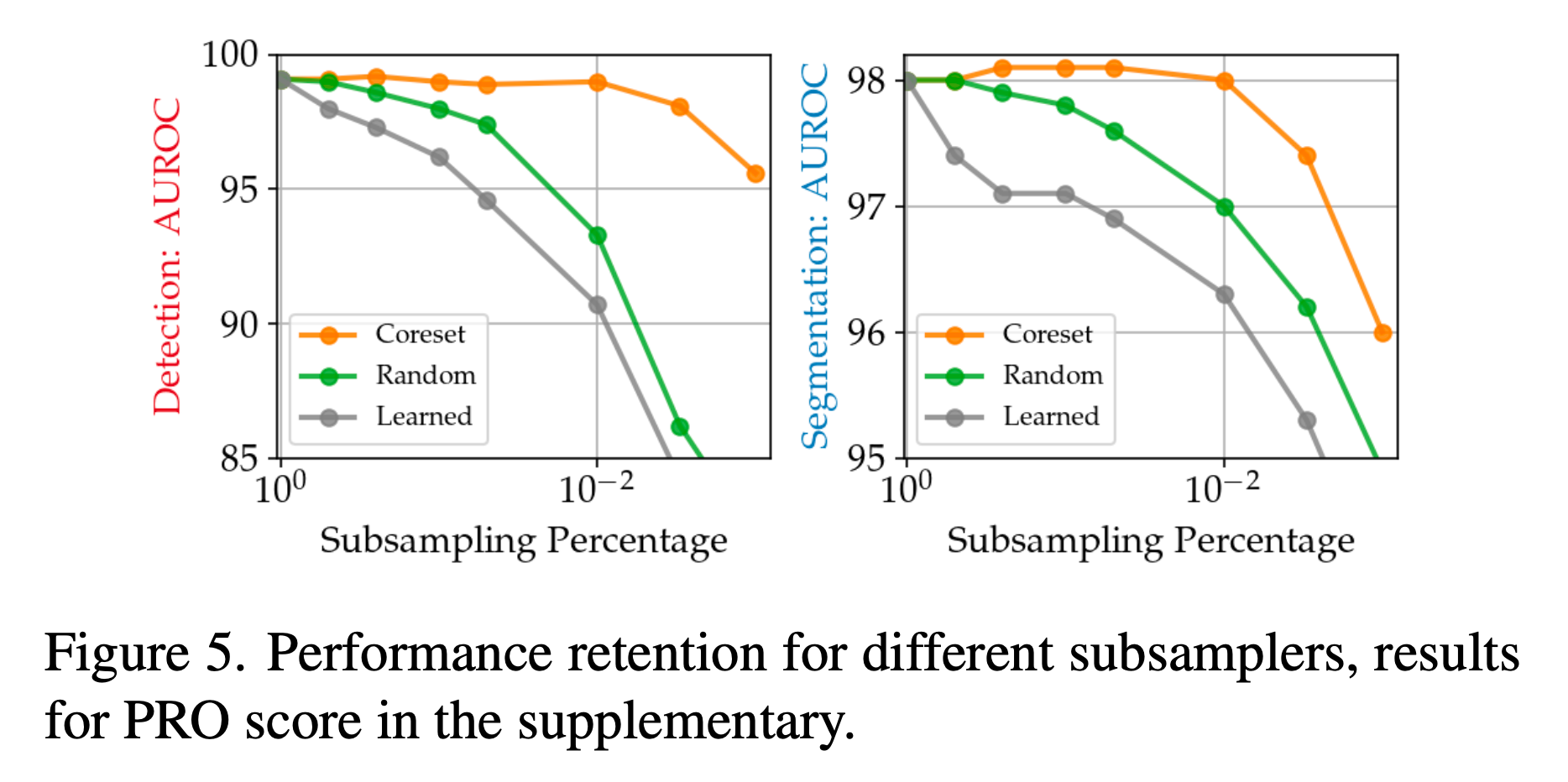
Importance of Coreset subsampling
- Coreset selection
- Random subsampling
- learning of a set of basis proxies
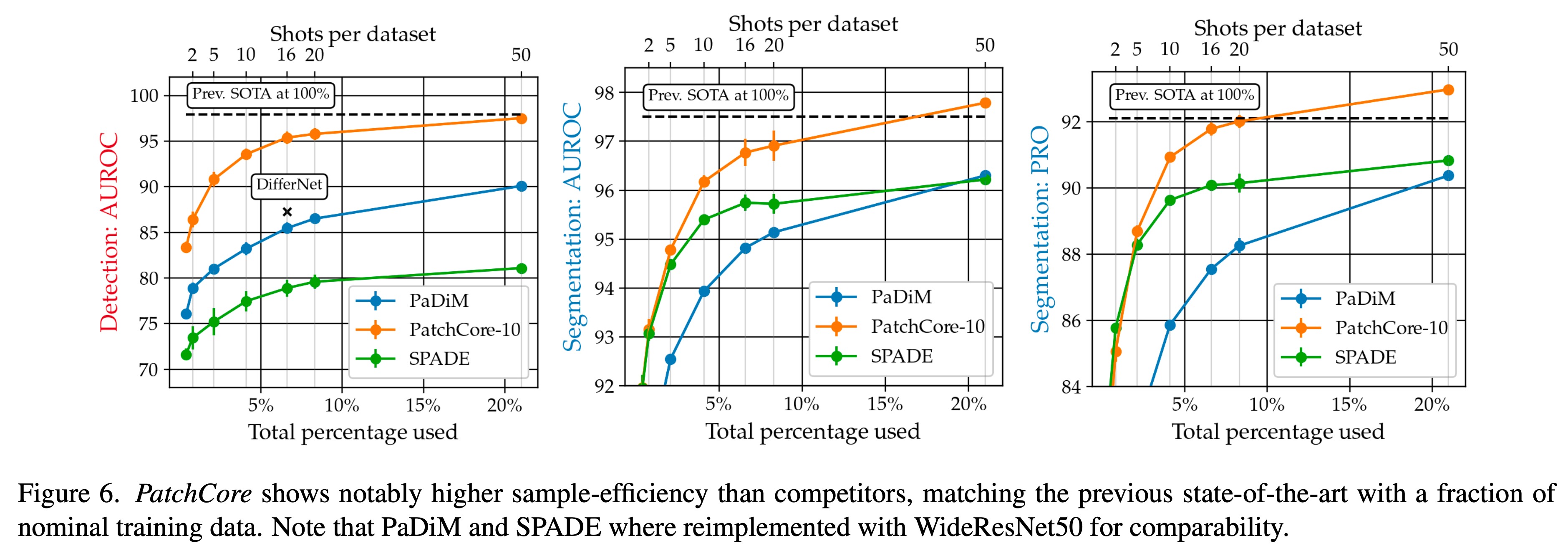
Low-shot Anomaly Detection
MVTec AD 데이터셋을 활용하여 정상 데이터의 양을 줄여가며 성능을 평가한 내용입니다.
- x축은 전체 데이터셋 중(약 240개)에서 사용한 비율을 의미합니다.
- 20%인 경우는 (약 50/240 \(\approx\) 0.208)로 총 50개 정도의 데이터셋만을 사용한 실험 결과 입니다.
- y축은 IMAGE AUROC, Seg AUROC, Seg PRO 에 대한 평가 지표를 사용합니다.
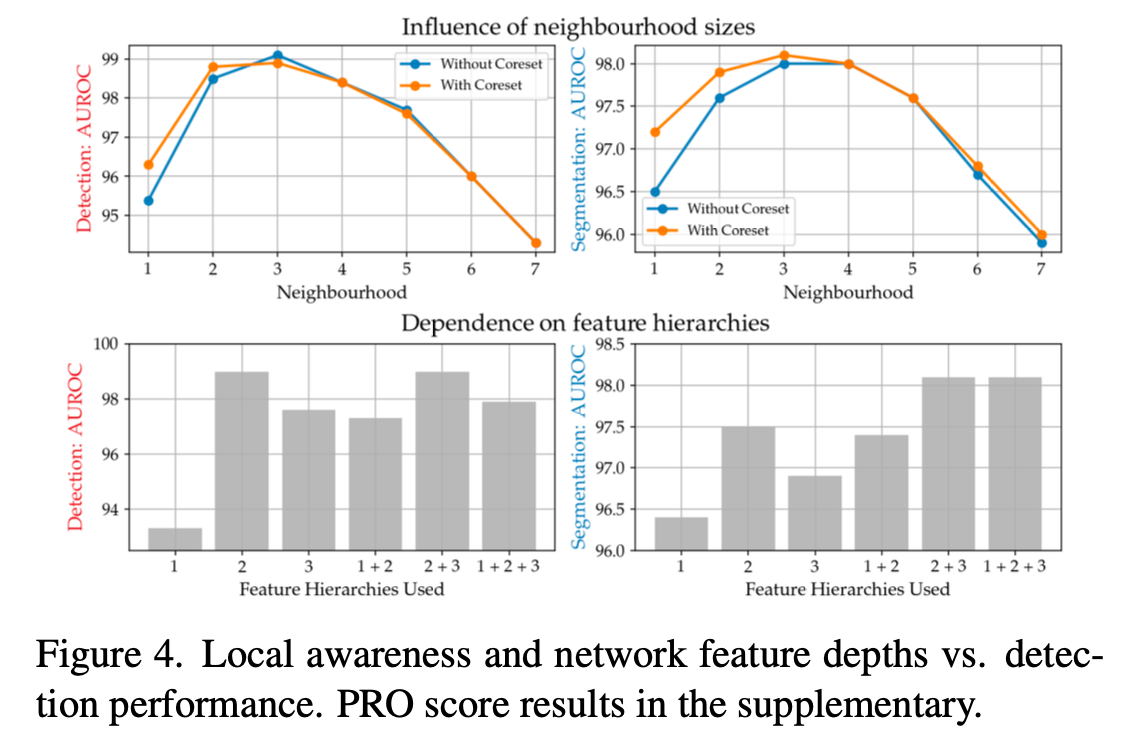
Locally aware patch-features and hierarchies
Neighbourhood Size
- “이웃 패치 간 거리의 가중치 부여” 실험에서는 몇 개의 이웃 패치(p)를 비교할 것인지에 대한 결과를 다루고 있습니다.
- p=3일 때 가장 좋은 성능을 보였습니다.
Feature Hierarchies의 중요성
- WideResNet50을 백본으로 사용할 때, 블록 2와 3(2+3)을 사용하는 것이 가장 우수한 성능을 나타냈습니다.
- 이는 mid-level feature(중간 수준의 특징)를 사용하는 것이 가장 효과적이라는 저자의 주장을 뒷받침합니다.
Reference
https://ffighting.net/deep-learning-paper-review/anomaly-detection/patchcore/
Comment