
서론
이 장은 ViT를 다양한 Task(Obejct Detection, Segmenation)에 적용한 모델인 Microsoft의 Swin Transformer에 대해 설명한다.
목차
- Dataset
- ViT 한계
- Herarchical Feature Map
- Local window
- Model Architecture
- Swin Transformer Block
- Patch Merging
- Swin Transformer 연구
- Conclusion
Dataset
- Pretrained on ImageNet-22K datasets
- Classification on ImageNet-1k datasets
- Object Detection on COCO2017 datasets
- Sematic Segmentation on ADE20K datasets
- Image Resolution(Default) 224 x 224 x 3 → Window size 7x7
- Image Resolution 384x384 → Window size 12x12
- Use AdamW optimizer
ViT 한계
- 이미지를 고정된 patch로 분할하지만 이미지속 물체는 고정되어 있지 않다.
- CNN에서 receptive field(Kernel)의 다양성이 떨어져 정확도가 낮아지는 것과 동일한 현상이 발생하여 어떤 물체는 잘 잡아 내지만 어떤 크기의 물체는 잘 잡아내지 못하는 문제가 발생
- 이미지의 크기가 증가할 수록 Patch의 갯수도 증가 → computational cost 상승
- 이 갯수가 이미지 크기의 비례해서 선형적으로 증가하지 않고 제곱에 비례해서 증가함
- \(Ω(MSA) = 4hwC2 + 2(hw)^2C\) (\(h\)와 \(w\)는 이미지의 크기)
- 이 갯수가 이미지 크기의 비례해서 선형적으로 증가하지 않고 제곱에 비례해서 증가함
위 1번과 2번의 문제를 해결하기 위해
Herarchical Feature Map
- 각 레이어 마다 patch의 크기를 다르게하여 하여 다양한 receptive field를 만듬 → Patch Merging 사용
Local window
- 기존 ViT는 이미지 전체에 대해서 global self-attention을 수행 → Computing Cost가 비쌈
- 이를 해결하기 위해 이미지의 영역을 나누고 각 영역에 대해서만 self-attention을 locally하게 수행 → Swin Transformer Block 사용
- 이미지 크기에 따른 연산 수가 제곱에 비례해 증가하지 않고 선형적으로 증가하는 효과를 얻음
- \(Ω(W−MSA)=4hwC^2+2M^2hwC\)
- 이미지 크기에 따른 연산 수가 제곱에 비례해 증가하지 않고 선형적으로 증가하는 효과를 얻음
Model Architecture
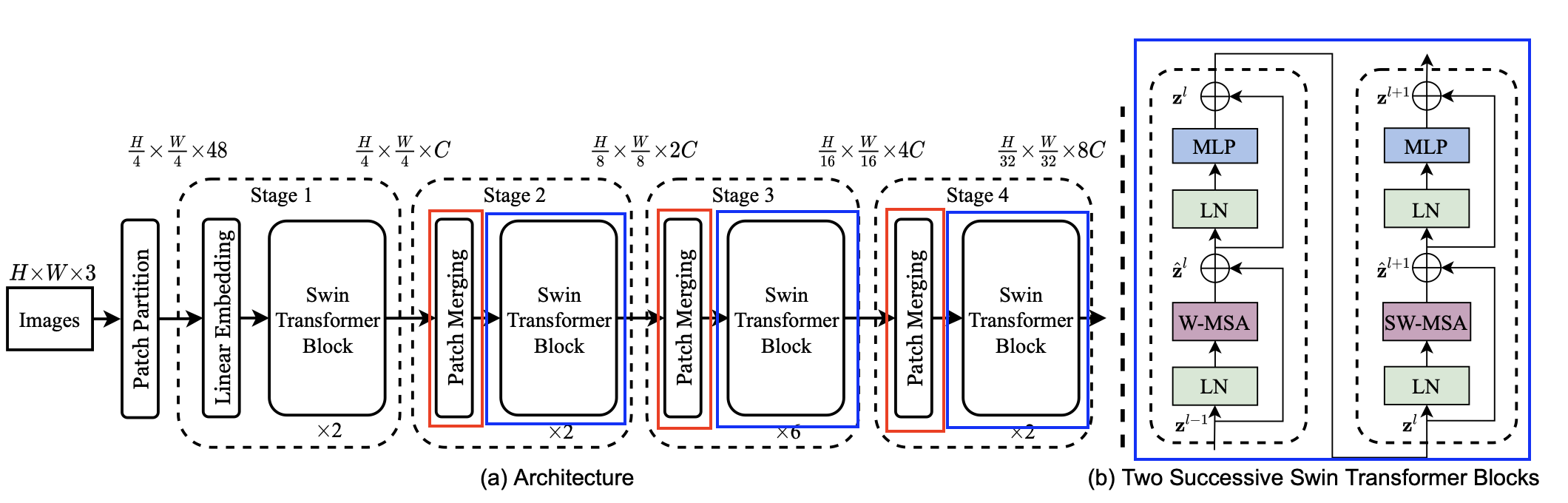
기존 vit와는 달리
고정된 patch size를 사용하는 것이 아니다,
classification에서 기존 [class] token을 사용하지 않고 Token들의 평균값을 사용한다.
Swin Transformer Block
Encoder
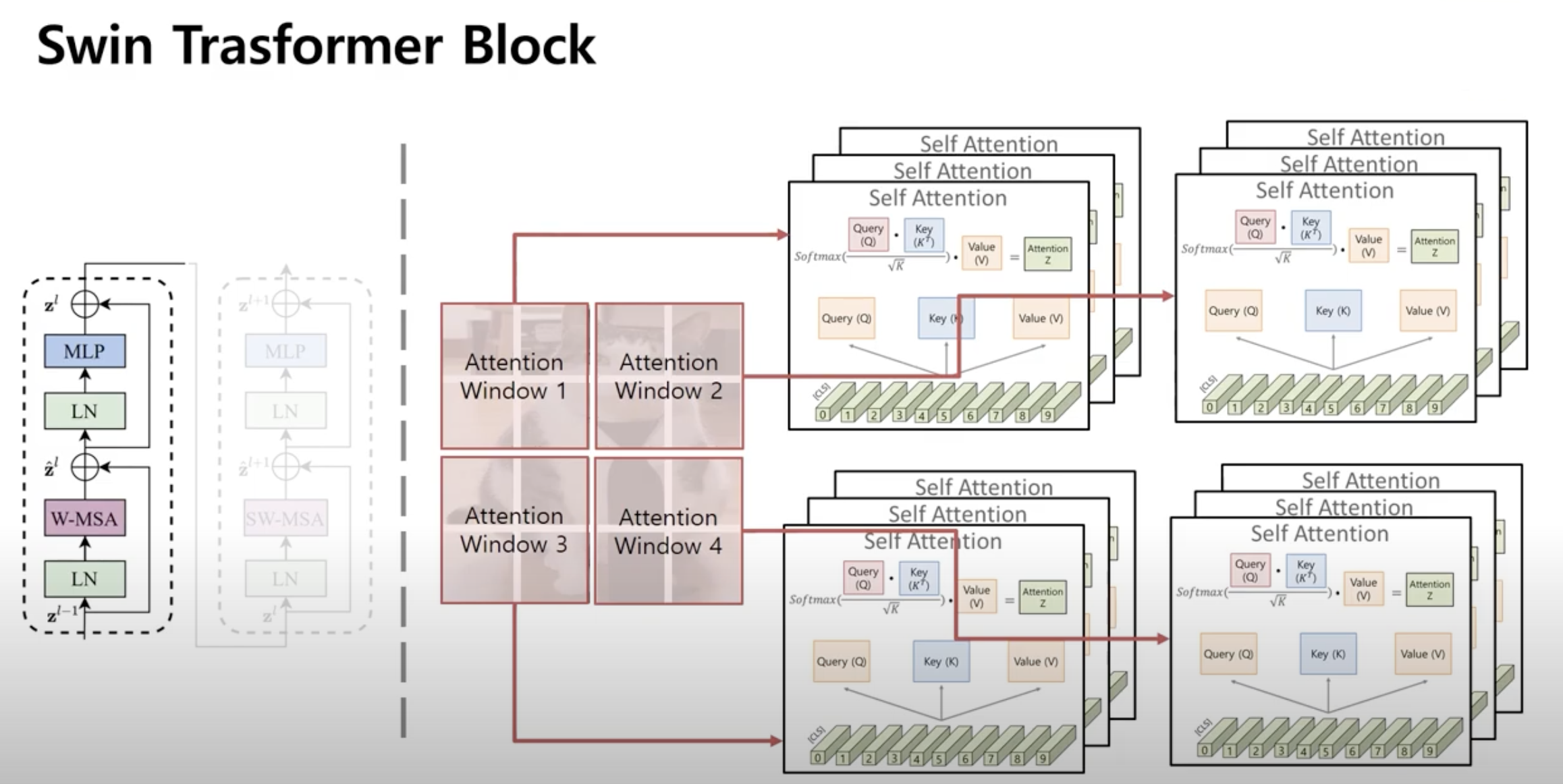
- 이미지 전체에 대해서 Self-Attention을 수행하지 않고 각각의 Window마다 Locally하게(따로따로) Multi-head Self-Attention을 진행 (Window Multi-head Self Attention → W-MSA)
- 이미지의 해상도가 커져도 computational cost가 제곱관계로 증가하지 않는다는 장점
- 하지만 단순 로컬 윈도우 방식은 단점이 있다. 바로 윈도우간의 정보교류가 전혀 이루어지지 못함
- 만약 어떤 물체가 Attention Window와 Attention Window사이의 경계에 있다면 잘 학습되지 못함
Decoder
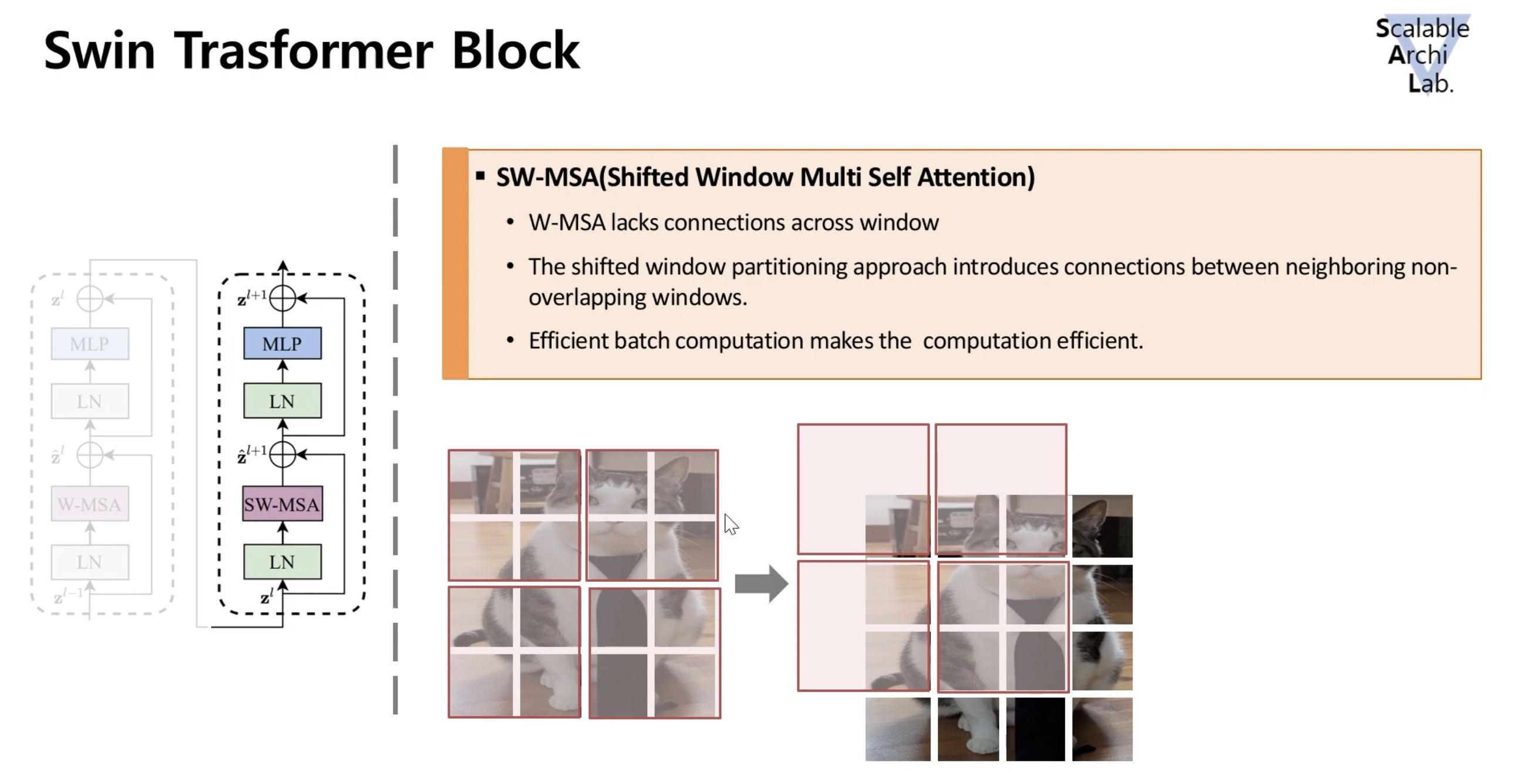
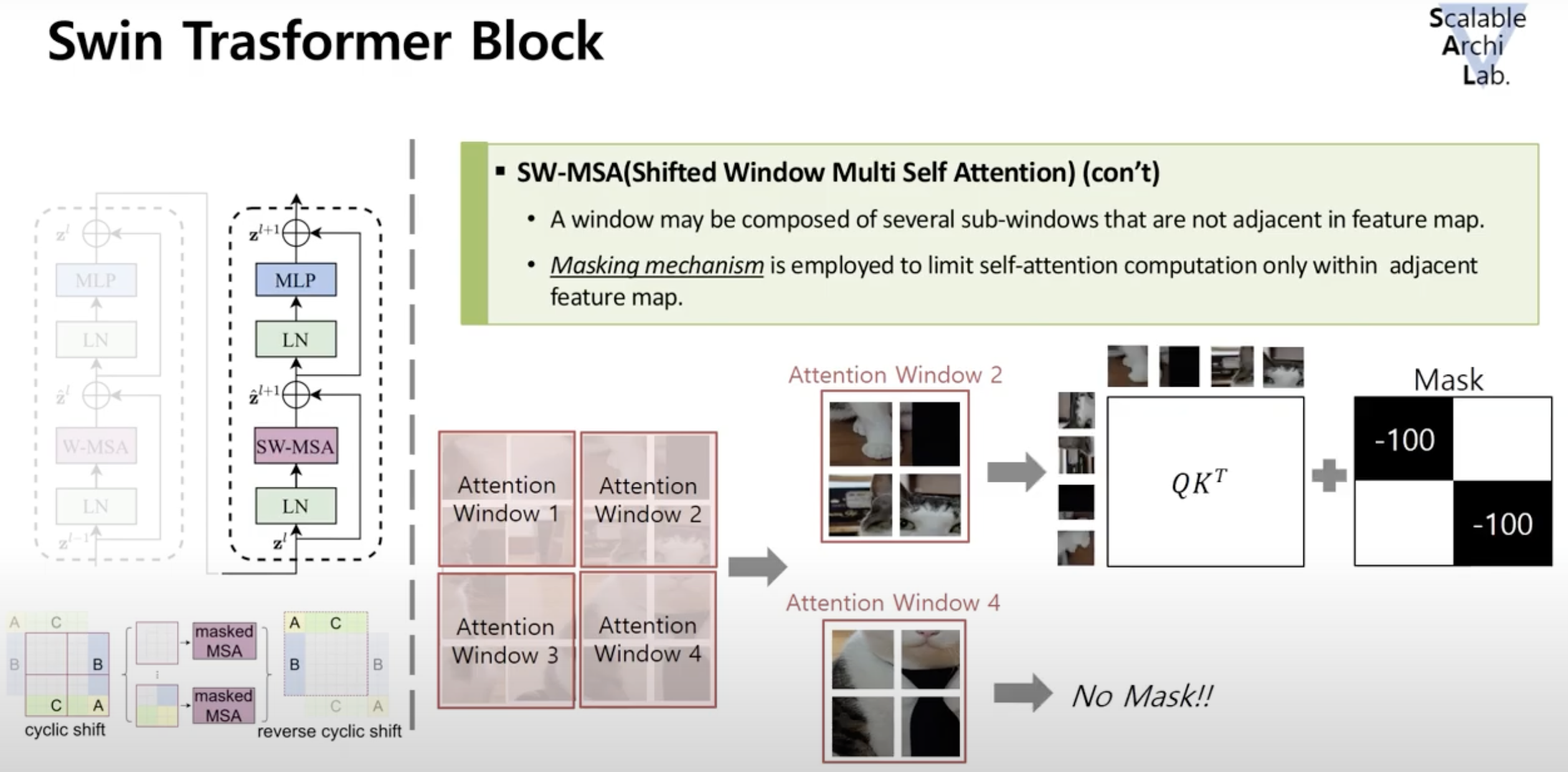
Window간 경계 문제를 해결하기 위해 Shifted Window Multi-head Self-Attention block을 배치
(Shifted Window Multi-head Self Attention → SW-MSA) -
- 예를들어 아래 이미지 처럼 Window가 구성되어 있다면 이를 대각선 방향으로 한칸 shift시킴→ (Cyclic Shift)
- 이미지를 Shift시키면서 Window밖으로 빠져나온 이미지들을 Window의 빈 공간에 채워 넣음
- 이렇게 채워진 Patch들을 다시 Attention Window로 묶는다
- Multi-head Self-Attention 연산을 수행해 각 Window간 정보 교류가 활발해짐
- 마스크 연산을 한 후에는 다시 원래 값으로 되돌린다. (reverse cyclic shift)
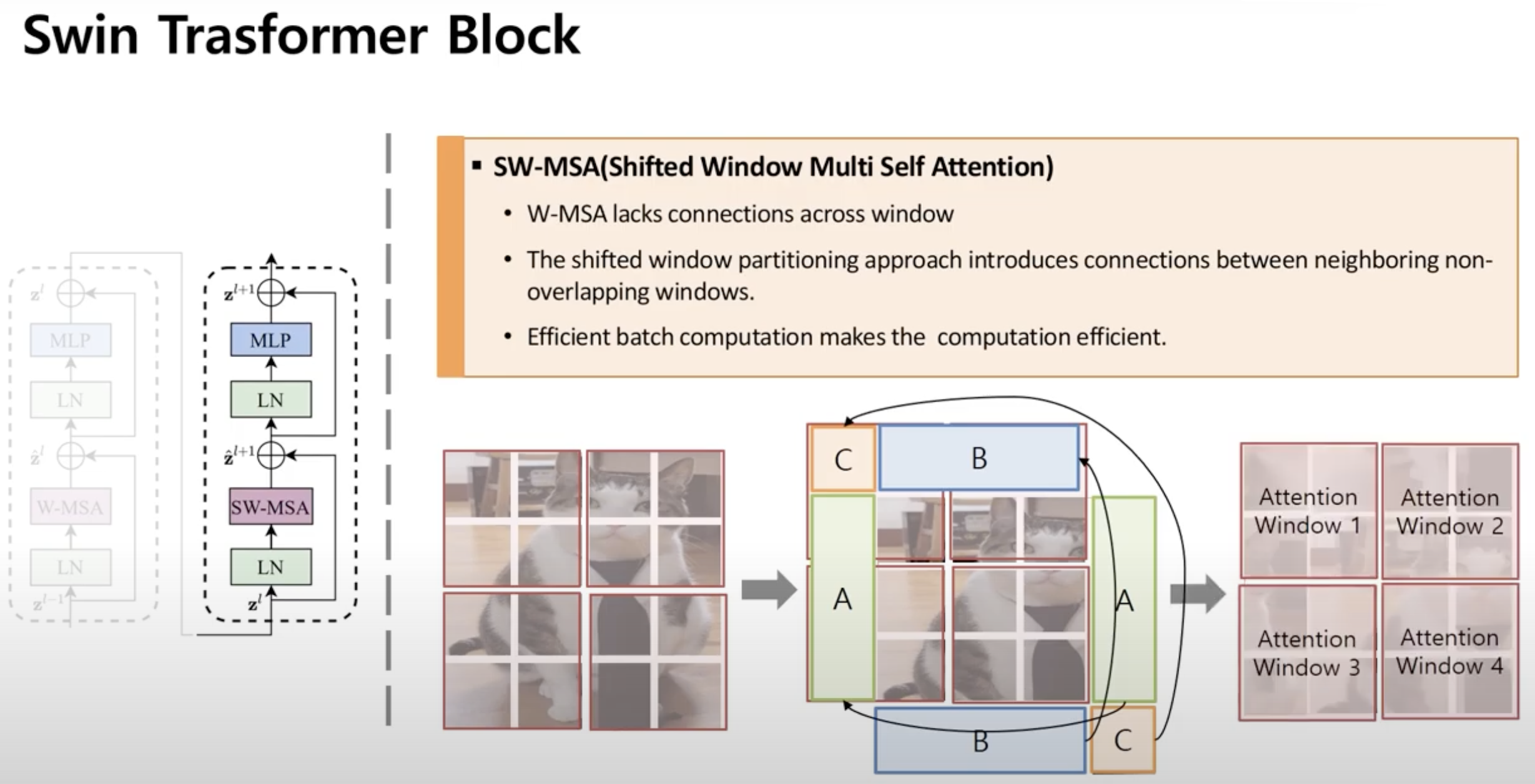
- 하지만 실제로 인접하지 않는 사진끼리 같이 Window로 묶이게 됨
- 예들들어 Attention Window 4는 실제로 인접한 이미지들 끼리 잘 묶인 반면, Attention Window 2와 같은 부분에 대해서는 첫번째행과 두번째 행의 이미지가 인접하지 않음
- 이대로 학습할 경우 모델은 인접하지 않은 이미지가 인접하다고 판단하고 잘못학습
- 이를 해결하기 위해 Masking 방법으로 해결
- Attention Window 4는 Masking을 적용하지 않고 Attention Window 2와 같은 경우에 대해서만 적용
- Masking 방식은 Attention Window 2의 첫번째행과 두번째행에 대한 Query와 Key를 내적할 때 Attention을 수행하는 부분에서 아주 큰 음수 값을 더해줌
- 그렇게 되면 인접하지 않은 부분에 대한 내적은 0에 가깝거나 음수를 갖게됨
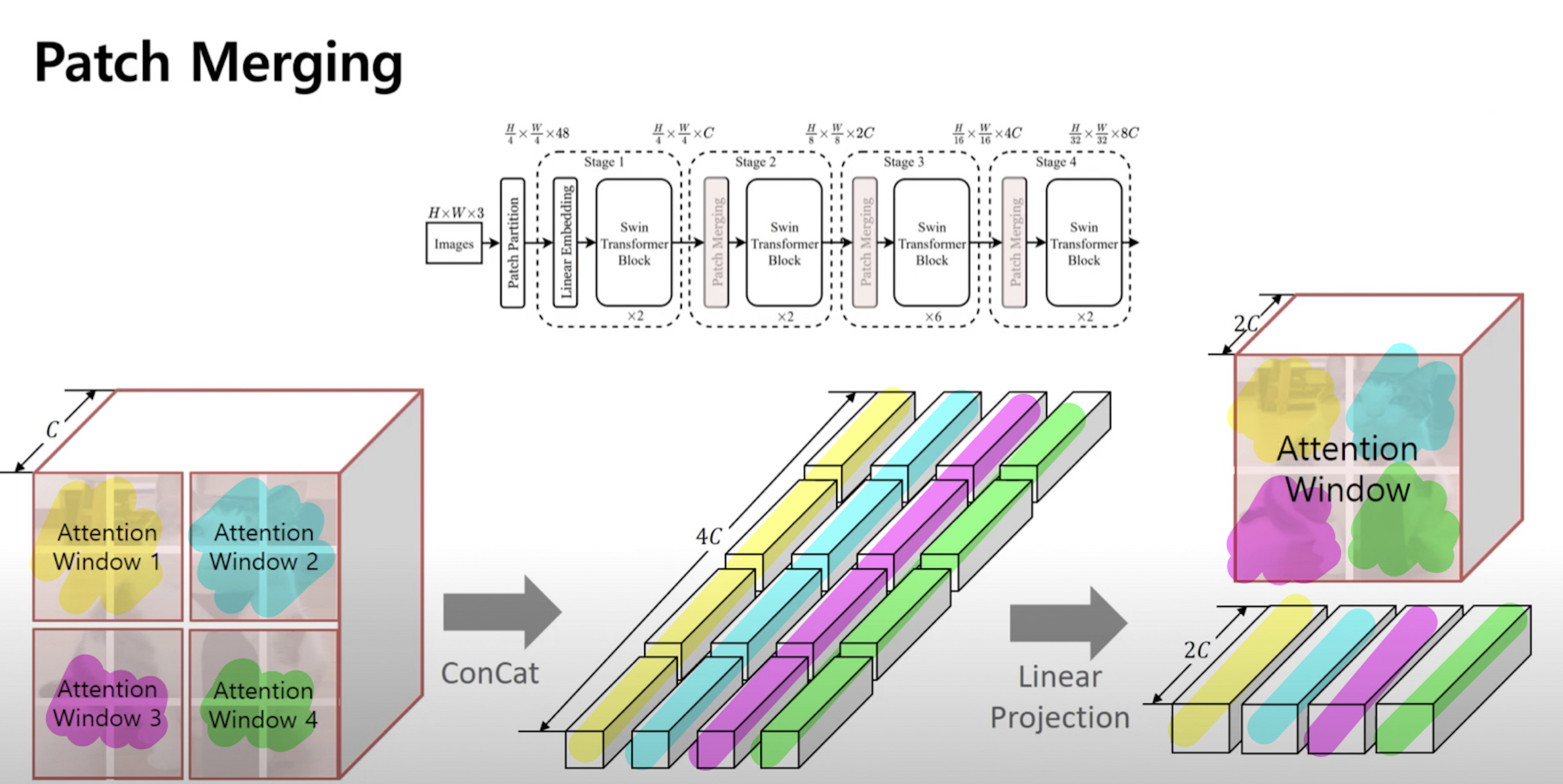
Patch Merging
Stage1을 제외한 모든 Stage에서 사용
- Stage1에서 하나의 이미지를 크기가 작은 16개의 patch로 나누고 4개씩 묶어 Attention을 Locally수행했다 가정(아래 그림 중 가장 오른쪽에 해당)
- Stage1에서의 출력(Patch Merging의 이전 Layer) → Patch Merging의 input으로 들어감
- 같은 Attention에 속해있는 4개의 patch가 Concat을 통해 4C의 Dimension을 갖는 하나의 긴 벡터로 나열
- Attention Window 1(노란색으로 칠해진)의 각 C를 Dim으로 가지는 4개의 Patch가 concat으로 첫번째 1열의 벡터(노란색)로 나열됨
- Attention Window 1(파란색으로 칠해진)의 각 C를 Dim으로 가지는 4개의 Patch가 concat으로 두번째 2열의 벡터(파란색)로 나열됨
- Linear Projection을 통해 4C dim → 2C dim으로 줄여줌
- 2C Dim으로 줄여진 벡터를 다시 Attention Window로 묶음
결과적으로 4개의 작은 Patch로 구성되었던 Attention Window가 Patch Merging을 통해 1개의 좀 더 큰Patch로 구성된 Attention Window가 되었음 → 다양한 크기의 Patch를 가지고 Multi-head Attention수행
Relative Position bias
bias를 통해 이미지 픽셀에 대한 상대적인 위치 정보를 줌으로써 지역 정보에 대한 inductive bias부여
ViT의 absolute position에 비해 성능 향상
아래 수식처럼 softmax를 취하기 전 B값을 더해줌
- Relative Position 범위 [-M+1, M-1]
- if M=3 → [-2, 2]
- Bias Index Matrix\((\hat{B})\)\(\in \mathbb{R}^{(2M-1)\times(2M-1)}\)
- \(B = \hat{B}\)
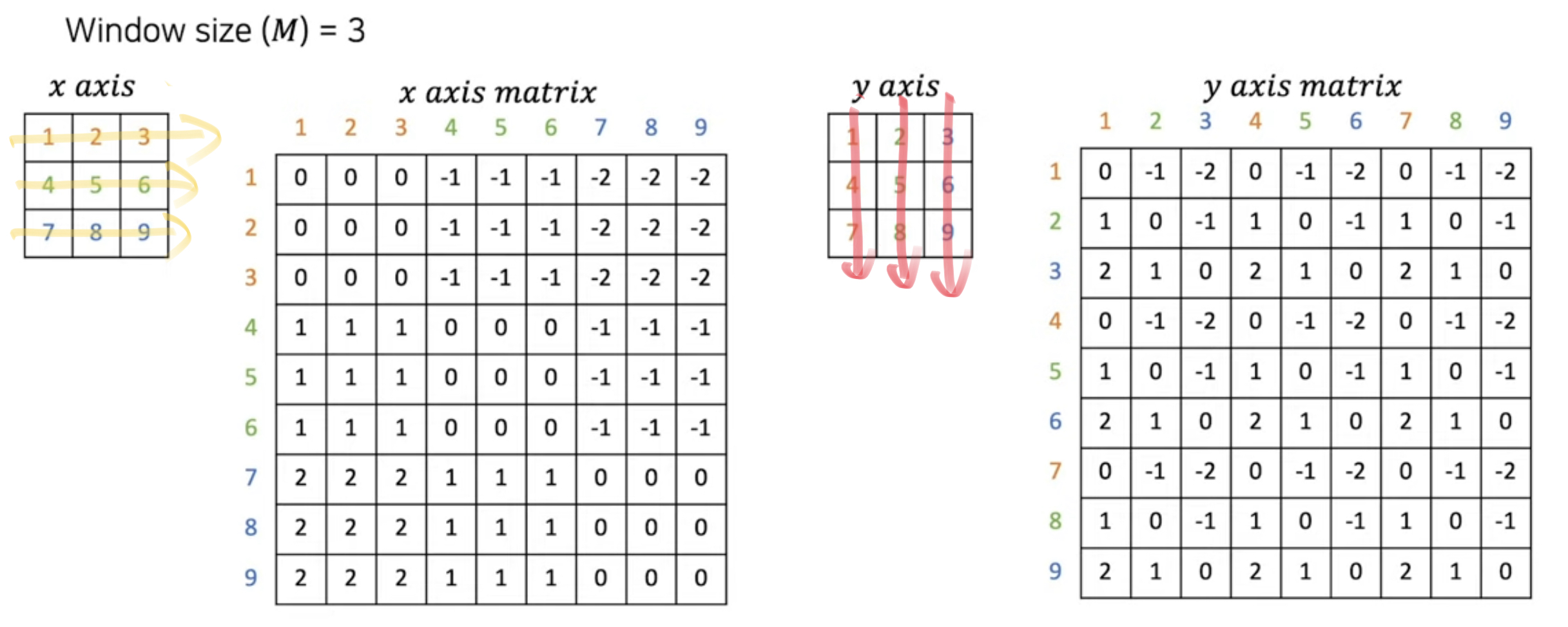
아래 그림은 Axis=0, 1에 대한 Bias index Matrix
노란색으로 칠해진 부분에 대한 상대적인 거리를 Matrix로 표현한다.
좌측에 세로로 나열된 숫자가 이미지 픽셀의 기준이 된다.
e.g.) Window size(M) = 3 인 경우에 대한 Bias index Matrix를 봐보자
- x axis 예시(위에는 +1, 아래는 -1)
- 1을 기준으로 2는 같은 x축위에 있음으로 0
- 1을 기준으로 4는 한 칸 밑에 있음으로 -1
- 4를 기준으로 8은 한 칸 밑에 있음으로 -1
- 8을 기준으로 5는 한 칸 위에 있음으로 +1
- 9를 기준으로 1은 두 칸 위에 있음으로 +2
- y axis 예시(오른쪽 -1, 왼쪽 +1)
- 2를 기준으로 1은 한 칸 왼쪽에 있음으로 +1
- 2를 기준으로 5는 같은 y축에 있음으로 0
- 9를 기준으로 7은 두 칸 왼쪽에 있음으로 +2
- 7을 기준으로 6은 두 칸 오른쪽에 있음으로 -2
그리고 아래 코드로 최종 Matrix가 결정된다. (if M = 3) 그리고 최종 이러한 값들이 더해진다.
# step 1
x_axis_matrix = x_axis_matrix + window_size - 1
y_axis_matrix = y_axis_matrix + window_size - 1
# step 2
x_axis_matrix = x_axis_matrix*(2*window_size - 1)
relative_position_M = x_axis_matrix + y_axis_matrix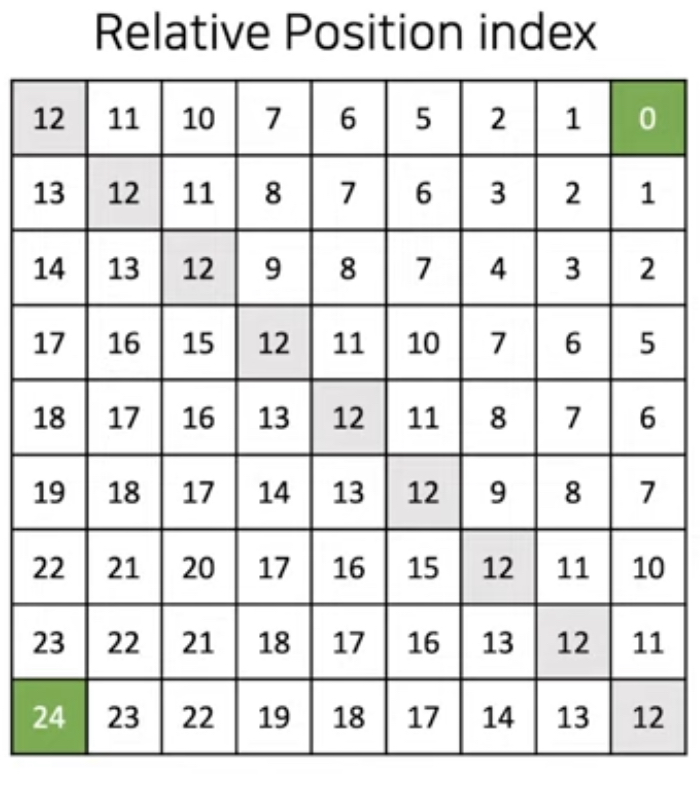
Inductive bias
- 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용되는 추가적인 가정
- 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정
- ViT의 경우 많은 양의 데이터로, DeiT의 경우 Knowledge distillation(TS)로 해결
Swin Transformer 연구
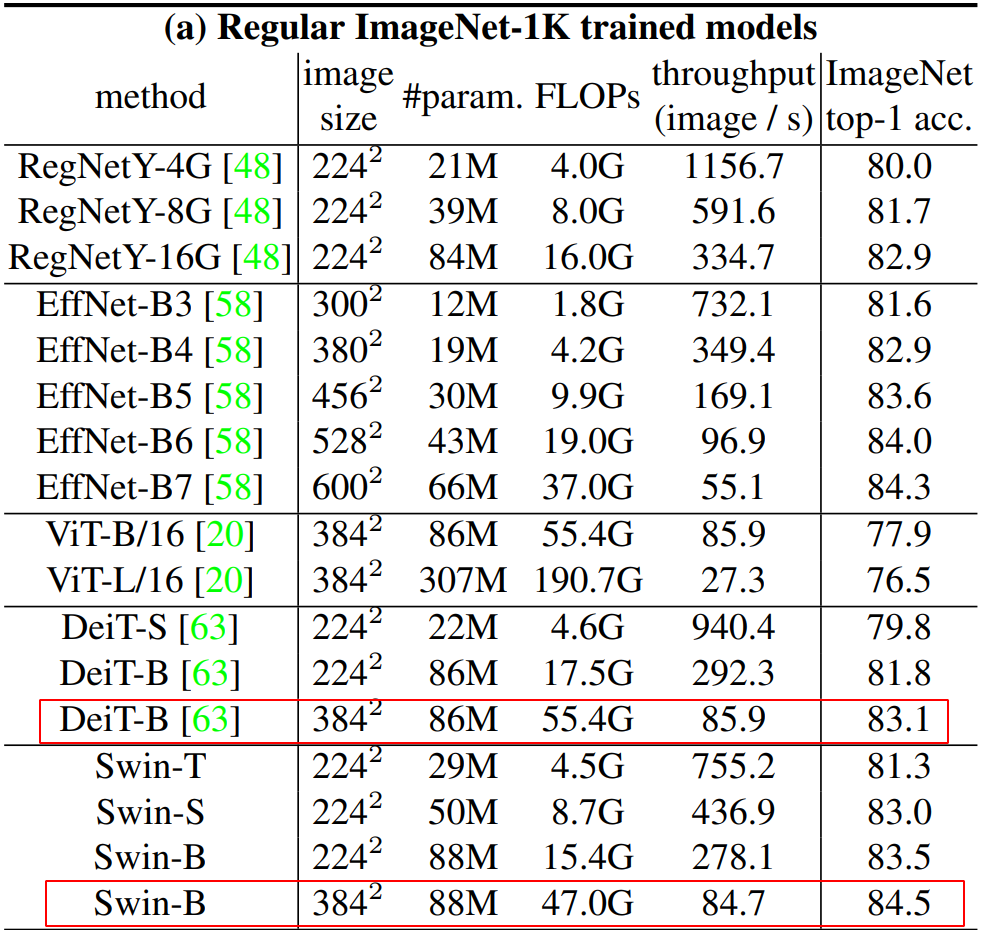
Image Classification
- Compare to DeiT, Swin →정확도, 속도 모두 압도
Swin Transformers noticeably surpass the counterpart DeiT architectures with similar complexities
- 완벽히 CNN의 SOTA 을 압도하지 못했지만 성능과 학습속도의 Trade-off가 더 작다
Compared with the state-of-the-art ConvNets, i.e. RegNet [48] and EfficientNet [58], the Swin Transformer achieves a slightly better speed-accuracy trade-off.
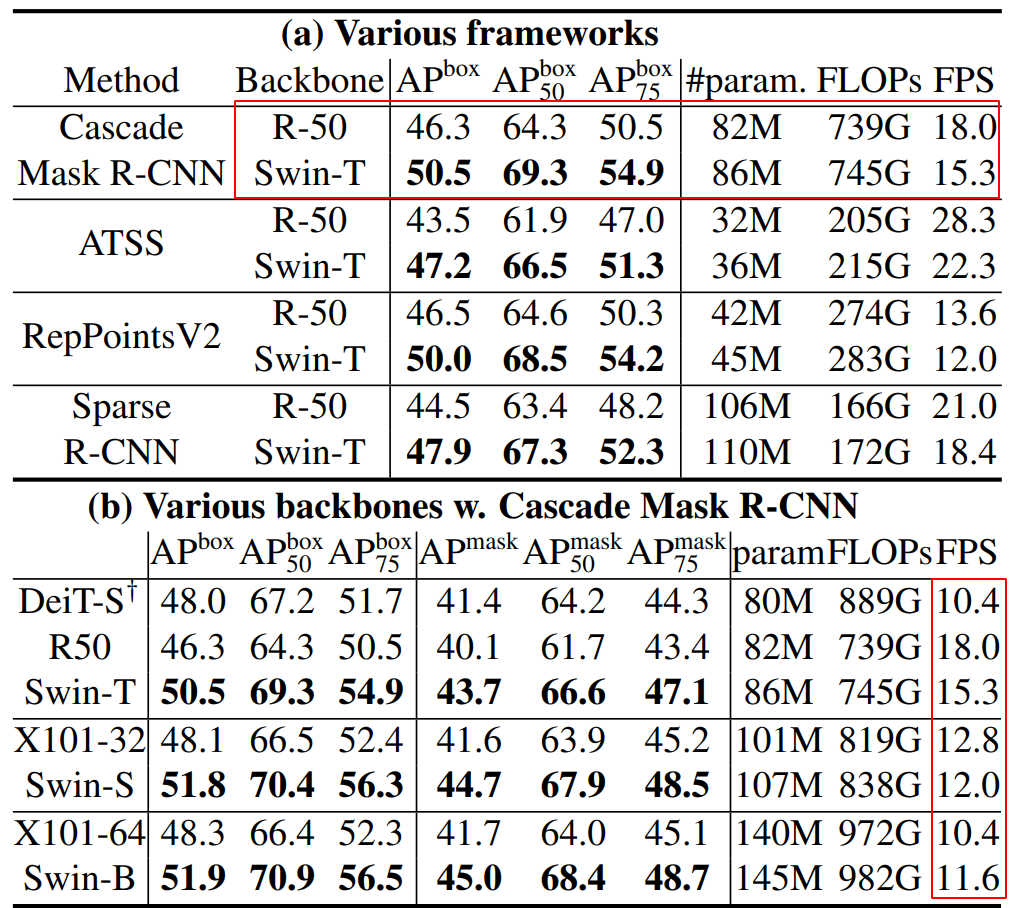
Object Detection
- Compare to ResNe(X)t - BackBone(Mask RCNN)
Swin-T architecture brings consistent +3.4∼4.2 box AP gains over ResNe(X)t-50
- Compare to DeiT
The results of Swin-T are +2.5 box AP and +2.3 mask AP higher than DeiT-S with similar model size (86M vs. 80M) and significantly higher inference speed
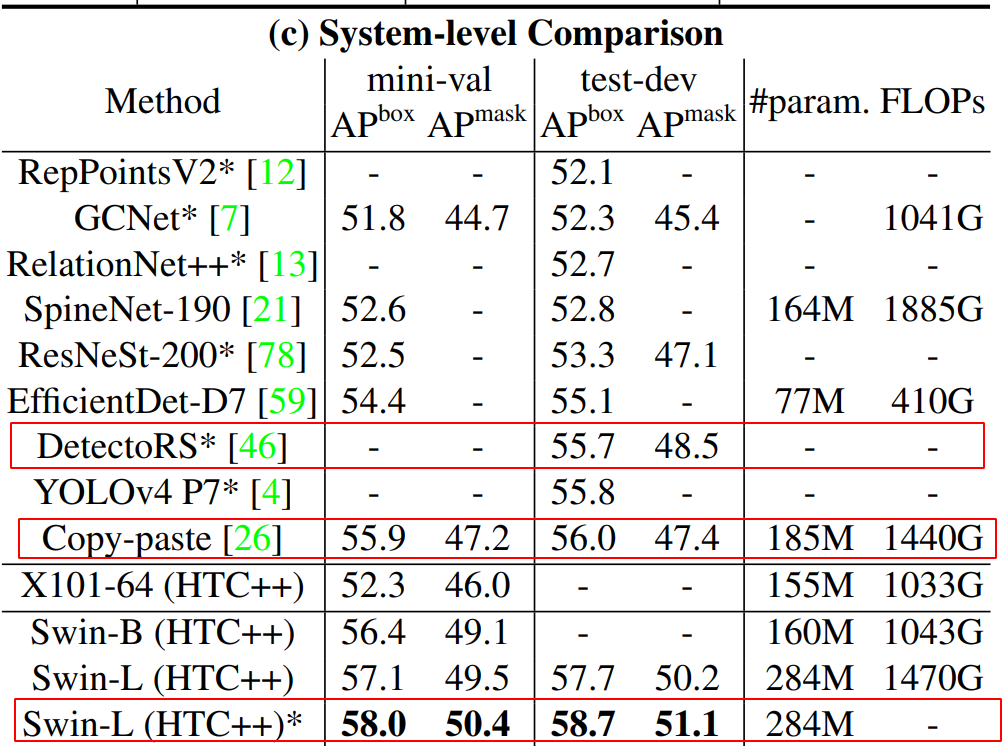
- Detectron RS, Copy-paste
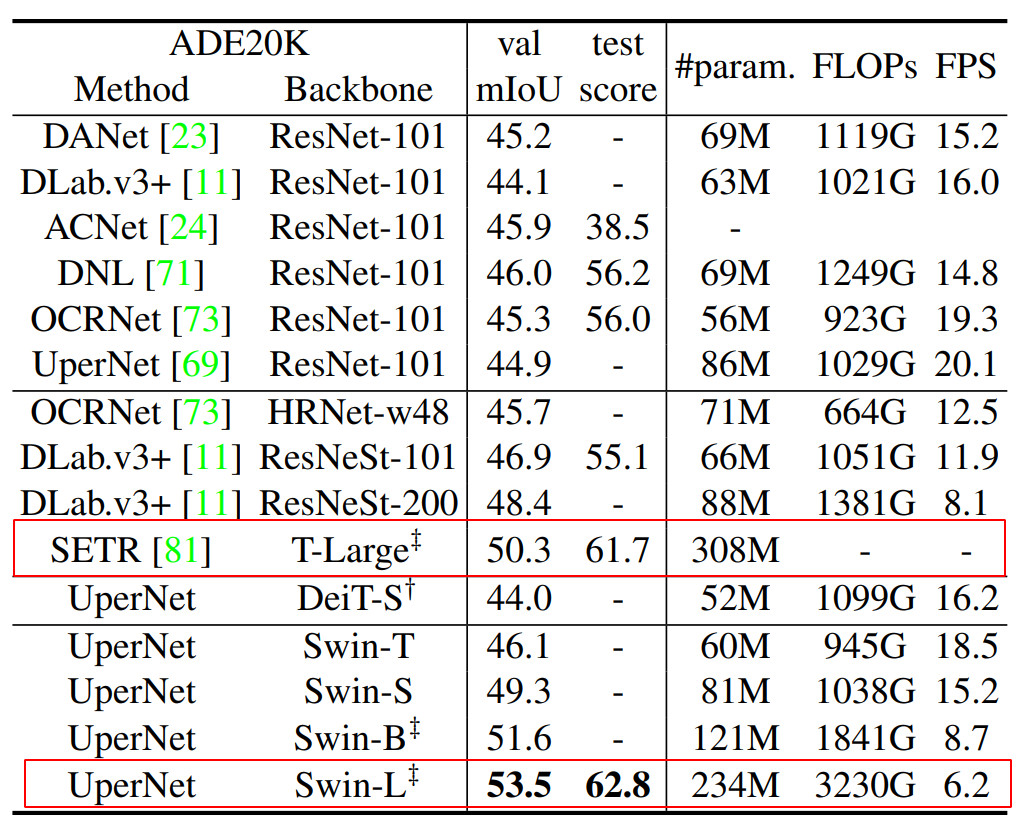
Semantic Segmentation
- Compare to SERT
Relative Position Bias & Shifted Window 여부
- Detection과 Segmentation 성능향상에 도움
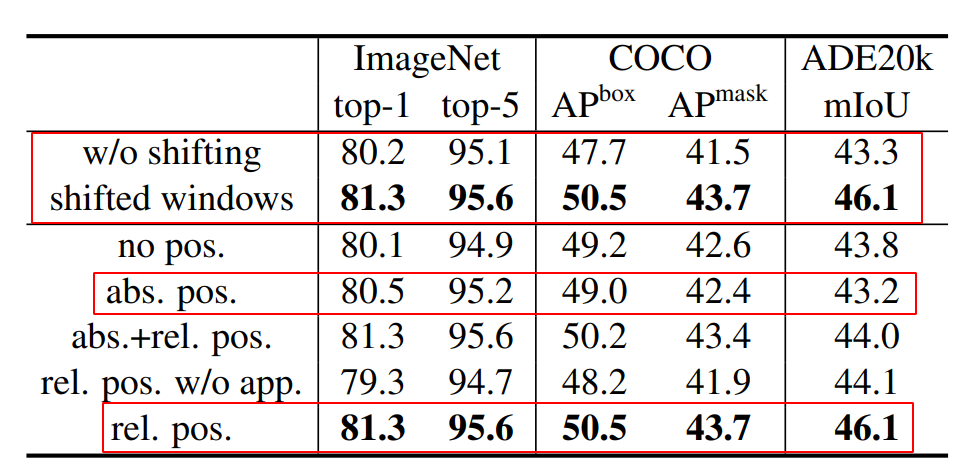
Conclusion
- Swin Transformer achieves the state-of-the-art performance on COCO object detection and ADE20K semantic segmentation
- The potential of Transformer-based models as various vision task backbones.
[참조]
https://www.youtube.com/watch?v=gFEQz8qJ6zY
https://www.youtube.com/watch?v=L3sH9tjkvKI
https://www.youtube.com/watch?v=2lZvuU_IIMA
Comment