
서론
이 장은 Microsoft사의 Swin Transformer의 코드에 대해 설명한다.
목차
- 전반적인 구조
- Patch Embed
- Dropout
- BasicLayer(nn.ModuleList)
- Swin Transformer Block
- window_partion
- torch.roll
- Patch Merging
전반적인 구조
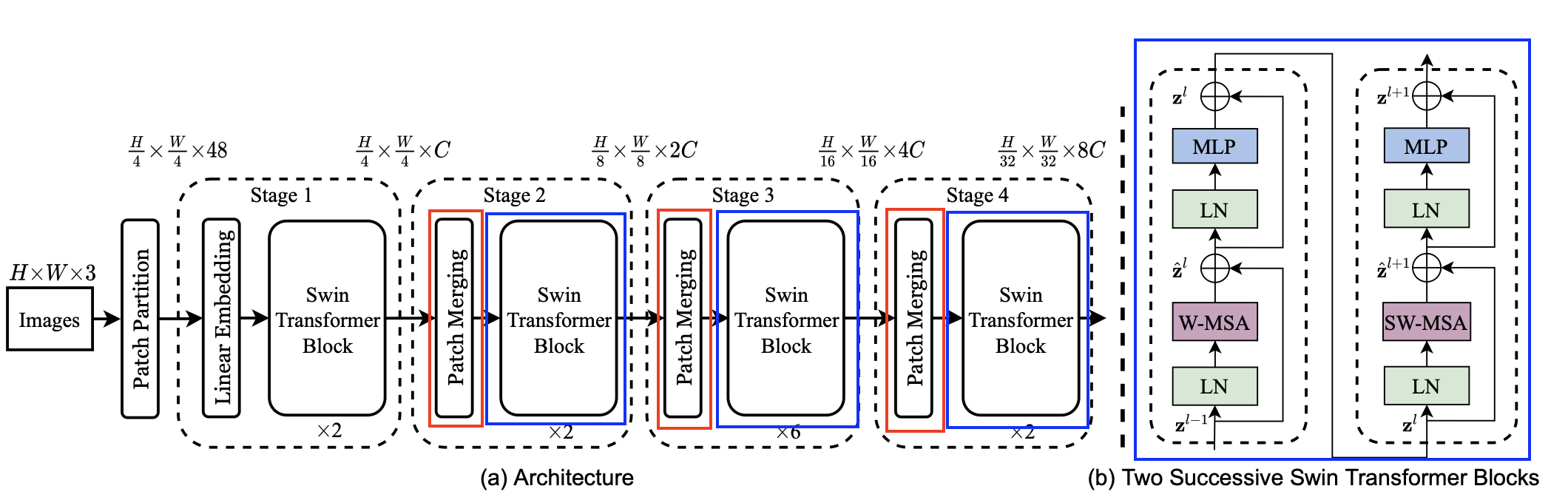
forward 함수 부분의 코드를 보면 다음과 같다.
PatchEmbedding → Dropout → BasicLayer(nn.ModuleList) → Norm & Avgpool & Flatten → nn.Linear
# model/swin_transformer.py 의 코드
class SwinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, fused_window_process=False, **kwargs):
super().__init__()
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
fused_window_process=fused_window_process)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape: # default=False
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return xPatch Embed
Patch Partion과 Linear Embedding Layer를 Conv(self.proj = nn.Conv2d)이 한번에 하고 있다.
nn.Conv2d(3, 96, 4, 4) → \(y = \frac{input_-size+2*padding-(kernel_-size-1)-1}{stride}+1\) 에 의해 55+1 = 56
그 후 flatten(2)를 적용하고 transpose(1, 2)를 한다.
따라서 (B, 3, 224, 224) → (B, 96, 56, 56) → (B, 96, 3136) → (B, 3136, 96) 되고 96차원을 갖는 총 3136개의 Embedding이 생성된다.
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return xDropout
일반화를 위한 Dropout 적용
self.pos_drop = nn.Dropout(p=drop_rate)BasicLayer(nn.ModuleList)
SwinTransformerBlock을 depth개 만드는데, 홀수번째 SwinTransformerBlock은 window_size//2로 설정한다. Downsample(Patch Merging Layer)을 적용한다
class BasicLayer(nn.Module):
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
fused_window_process=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
fused_window_process=fused_window_process)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return xSwin Transformer Block
- Layer Normalization
- forward의 x는 (B, 56, 56, 96) 으로 들어오는데 view를 통해 (B, 56, 56, 96)으로 변환
- windows_partition(여기), output shape (Bx8x8, 7, 7, 96)
- Tensor속 윈도우는 self-attention을 처리하기 위해 이차원 tensor가 되어야 함 → view를 통해 (Bx8x8, 7x7, 96)으로 변환되어 window내에 있는 patch끼리 self-attention이 이루어짐
- window partition 함수에서 다른 이미지의 window지만 Bx8x8로 묶은 이유는 계산 편의성
에 있다.
- window 내부 패치들끼리만 이루어지는 계산이기 때문에 다른 이미지 window와 독립적이다.
- self-attention을 통해 나온 output은 self-attention 특성상 input과 동일한 shape 을 갖게 된다. 그리고나서 window_reverse 함수를 통해 기존 shape (B, 56x56, 96)으로 복구 가 된다.
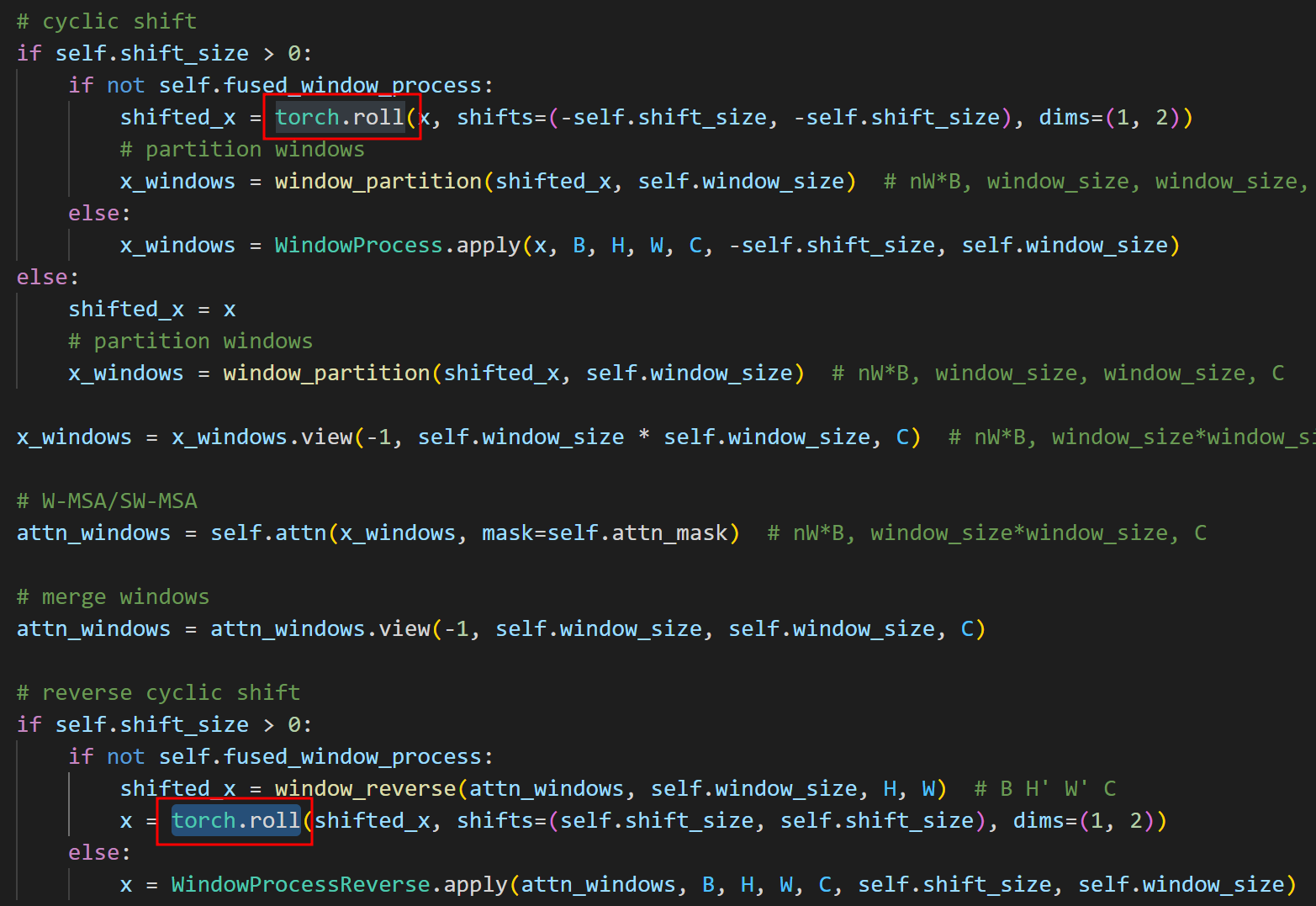
- torch.roll → window partition → (Bx8x8, 7, 7, 96) → (Bx8x8, 7x7, 96) → self-attention → widnow_reverse → (Bx8x8, 7x7, 96) → torch.roll
- window partition & window reverse를 진행할 때 shift된 window의 빈 공간을 채워주고 채워준 이미지 부분을 다시 복구 시켜야한다. → torch.roll을 사용(여기)
- shortcut connection이나 drop_path 등 여러 기법이 적용
class SwinTransformerBlock(nn.Module):
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
fused_window_process=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
self.fused_window_process = fused_window_process
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
else:
x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
# reverse cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)
else:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return xwindow_partion
x.shape (B, 56, 56, 96), window_size=7 → (B, 8, 7, 8, 7, 96) —permute—> (B, 8, 8, 7, 7, 96) —view—>
(Bx8x8, 7, 7, 96)
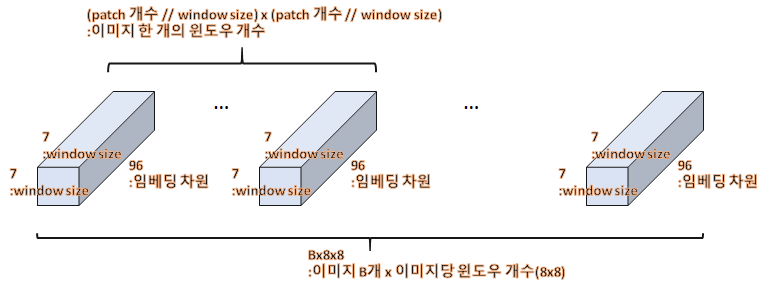
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windowstorch.roll
torch.roll sample
import torch
x = torch.tensor(
[
[1, 2, 3, 4],
[5, 6, 7, 8]
]
)
x = torch.roll(x, 2)
print(x)#output
tensor([[7, 8, 1, 2],
[3, 4, 5, 6]])Patch Merging
Hierarchical 한 특성을 위해 하나의 이미지에 존재하는 Patch의 개수를 점점 줄이며 학습한다.
이를 통해 이미지의 작은 물체부터 큰 물체까지 모든 정보가 학습에 사용하게 된다.
- input x에 대해서 한 칸씩 띄어 새로운 이미지 (x0, x1, x2, x3)를 만든다.
- Embedding 차원을 기준으로 Concat
- Normalizatoin
- Reduction을 통해 차원을 조정
- (B, 56x56, 96)가 들어옴 — view—>(B, 56, 56, 96) -> (B, 56/2, 56/2, 96x4) —reduction—> (B, 56/2, 56/2, 96x2)
- patch merging(downsample)이 완료된 tensor은 다음 BasicLayer의 input 사용된다.
- 모든 BasicLayer(여기)를 거친 tensor은 norm/avgpool/flatten/nn.Linear을 통해 class 개수에 맞춘 tensor가 되어 loss가 계산된다.
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x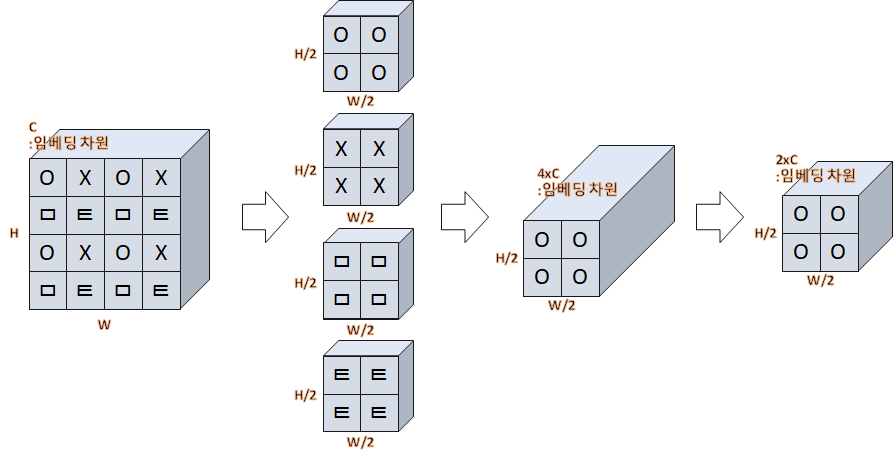
[참조]
https://visionhong.tistory.com/31
https://byeongjo-kim.tistory.com/36
https://github.com/microsoft/Swin-Transformer/tree/2622619f70760b60a42b996f5fcbe7c9d2e7ca57
https://github.com/microsoft/Swin-Transformer/blob/main/get_started.md
Comment