
서론
이 장은 ShuffleNetV1에 대해서 코드를 리뷰한다.
목차
Parameter
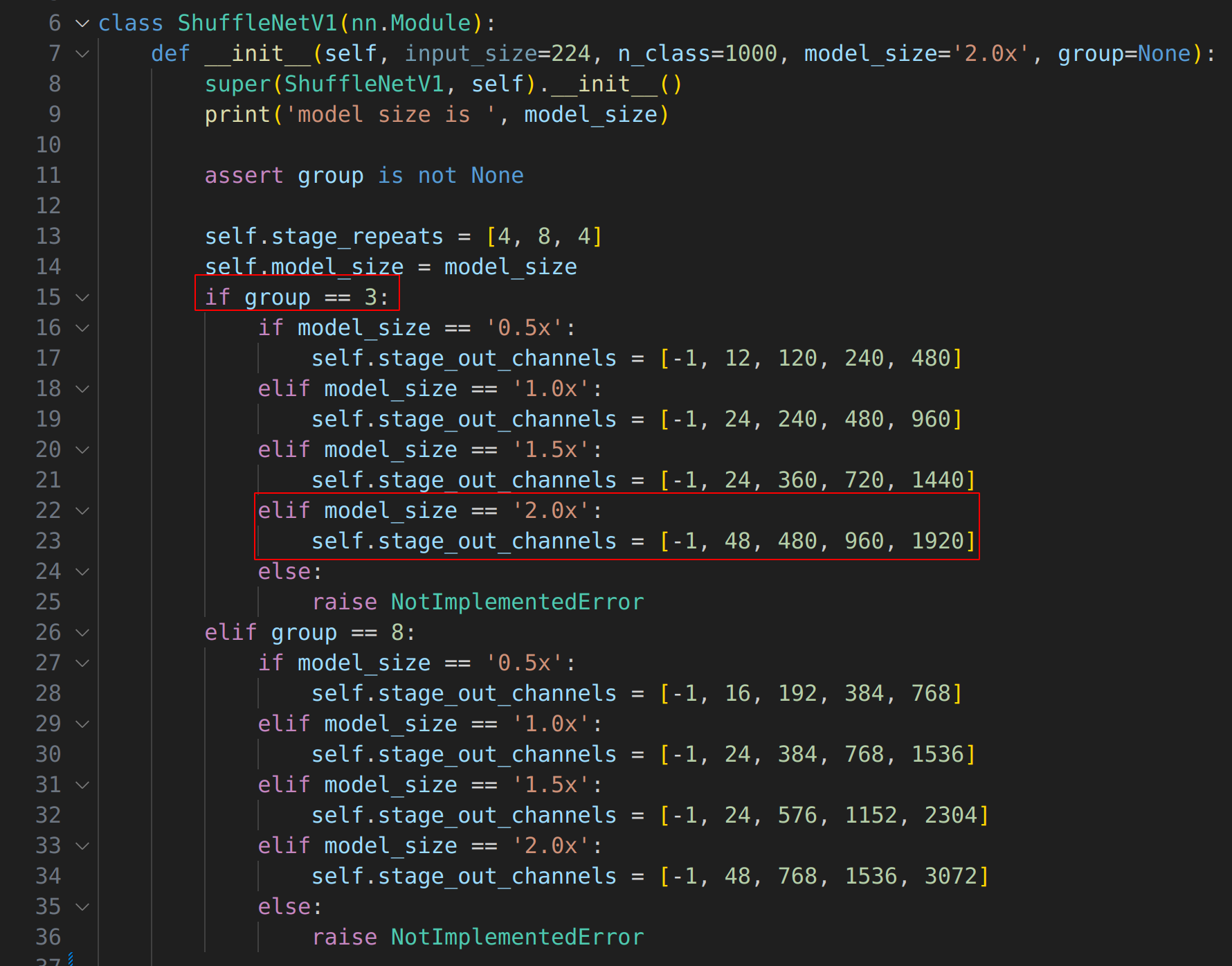
아래는 group과 model_size에 따라 channel 수를 설정한다. group=3, model_size=2.0x로 설정한다.
first_conv
초기 네트워크를 설정한다. ( Conv → Batch → ReLU → MaxPool)
3-channel이 입력으로, out_channels=48, kernel_size=3, stride=2, padding=1이다.
따라서 Input으로 (3, 224, 224) 가 들어와 Conv통해 (48, 112, 112) 되고 MaxPool2d를 통해 (48, 112, 112) → (48, 56, 56) 될 것이다.
❗ kernel_size=3, padding=1인 경우 이미지의 크기는 유지되며 stride=2일 경우 이미지의 크기가 절반으로 줄어든다.

features
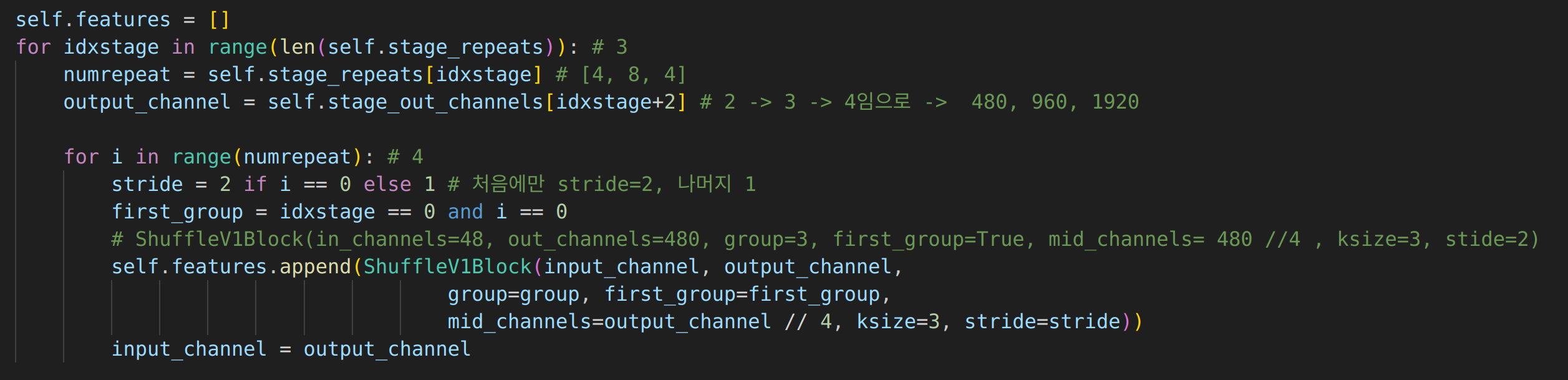
이후 self.features라는 리스트에 ShuffleV1Block을 append해준다.
self.stage_repeats = [4, 8, 4] 의 길이 만큼 반복해주기 때문에 첫번째 for문은 3번을 반복,
그리고 두번째 for문은 stage_repeats의 첫번째 리스트 요소인 4번을 반복한다.
이때 두번째 반문의 i=0일때만 stride=2로 설정하고 나머지는 1로 설정한다.
first_group은 초기만 True를 이후에는 False가 된다.
이후 ShuffleNetV1Block 을 봐보자.
처음에는 ShuffleV1Block(in_channels=48, out_channels=480, group=3, first_group=True, mid_channels= 480 //4 , ksize=3, stide=2) 값으 들어간다.
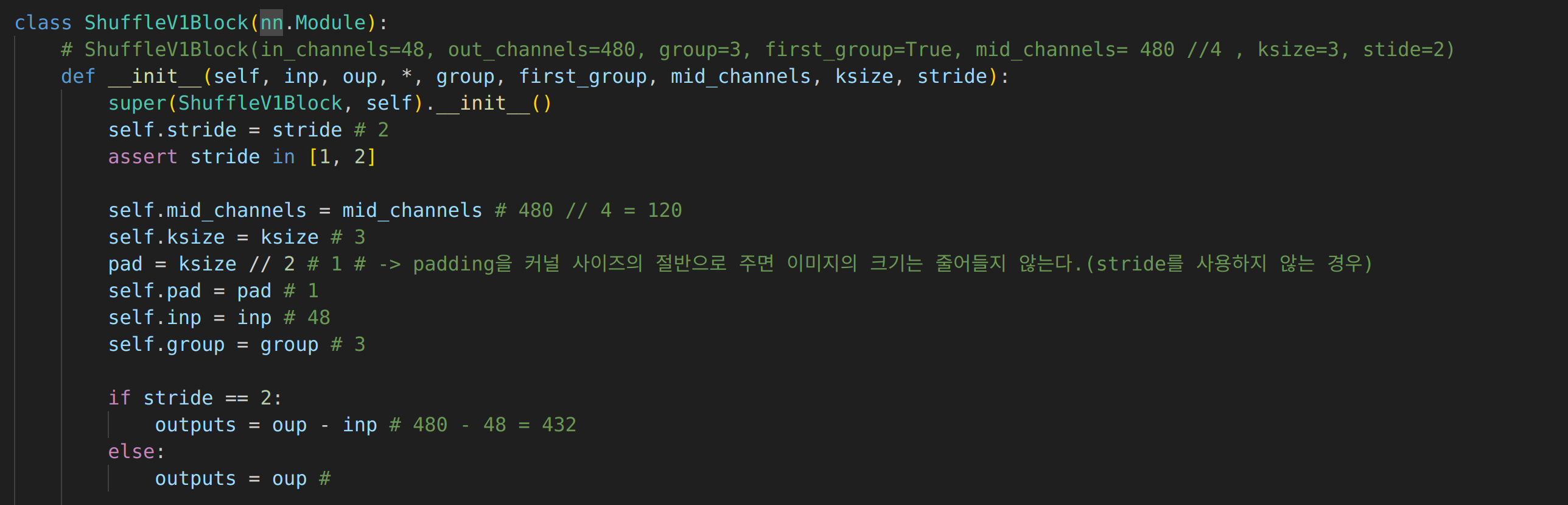
ShuffleV1Block
mid_channel은 output channel // 4self.ksize는 kernel size를 의미self.pad는 kernel size //2 를 통해 커널에 따른 이미지의 크기 줄어들지 않는 만큼의 패딩을 부여한다.self.group은 3으로 변하지 않는다.stride=2인 경우 output_channels은 input channel을 subtract 한다.- 이렇게 하는 이유는 Residual connection때 차원을 input channel을
torch.cat해주기 때문이다.
- 이렇게 하는 이유는 Residual connection때 차원을 input channel을
branch_main_1
Pointwise Convolution- 처음에만 first_group=True임으로 groups=1로 설정되어 일반
pointwise convolution이 된다. - 이때 output_channels의 1/4를 입력과 출력 채널로 사용한다.
- BatchNorm2d → Relu
- 처음에만 first_group=True임으로 groups=1로 설정되어 일반
Depthwise Convolution- 첫 반복에는 stride=2를 가지는 depthwise convolution이 만들어져 이미지의 크기가 절반으로 작아진다.
- BatchNorm2d

branch_main_2
Pointwise linear ConvolutionRelu를 적용하지 않은pointwise convolution를 사용한다.- out_channels는 mid_channels의 4배가 되서 나온다.

stride가 2인 경우 최종 출력의 이미 크기가 절반으로 줄어들어 residual connection에서도 절반으로 줄어들게 하기 위해 Pooling을 적용한다.

forward
group이 1보다 큰 우에 대해서는 channel을 shuffle하고 그렇ㅣ 않는 경우는 shuffle하지 않는다.
초기에만 first_group=True임으로 처음에만 셔플링하지 않는다.
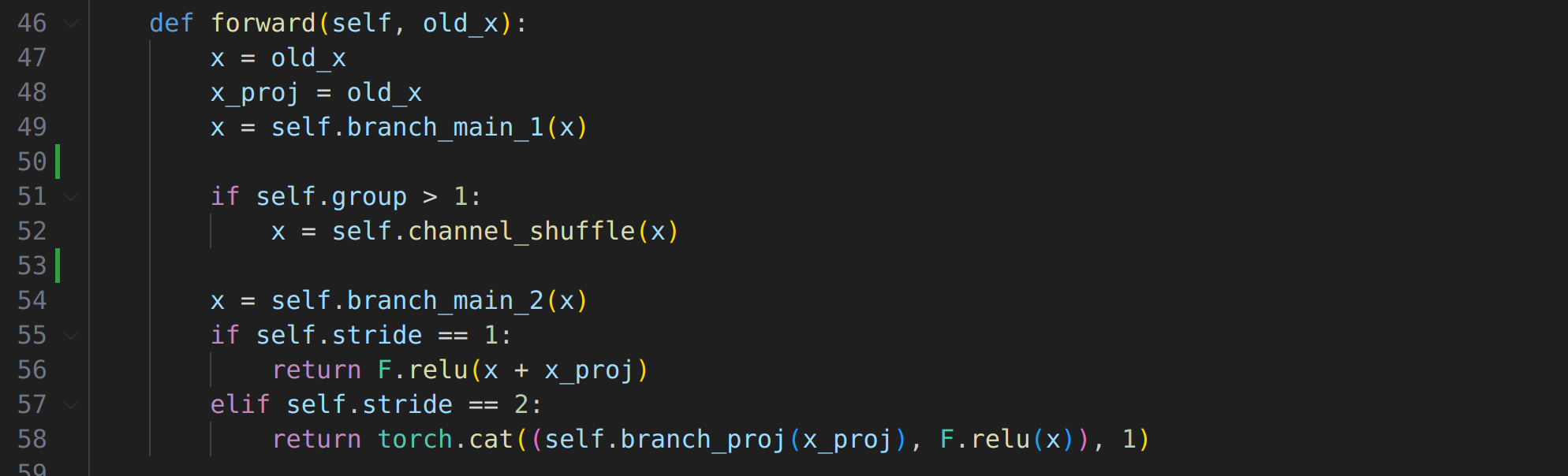
아래 그림은 위 코드에 대한 flow이다.
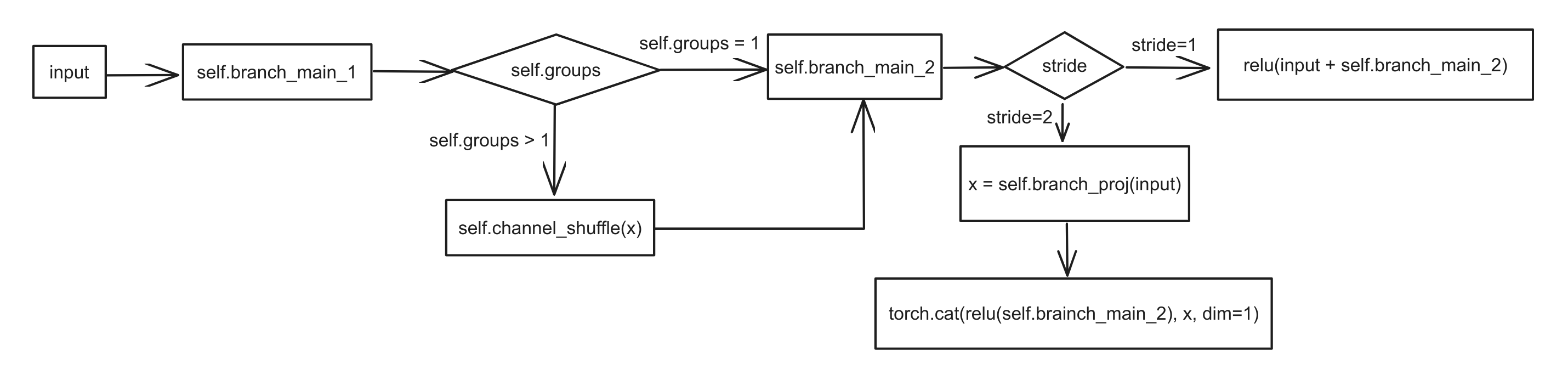
old_x,x_proj: Input값을 저장한다.x = self.branch_main_1(x): branch_main_1인 sequential layer를 통과하고 x에 저장x = self.channel_shuffle(x): 채널 dimension을 shuffle한다.x = self.branch_main_2(x): branch_main_2인 sequential layer를 통과하고 x에 저장F.relu(x+xproj): stride=1인 경우 입력과 출력의 크기가 같음으로 residual connection 이후 relu 을 적용 relu(x_proj+x)torch.cat((self.branch_proj(x_proj), F.relu(x)), 1: stride=2인 경우x_proj의(h, w)를 절반으 줄인다. 이후x값에만relu를 취하고concat한다.
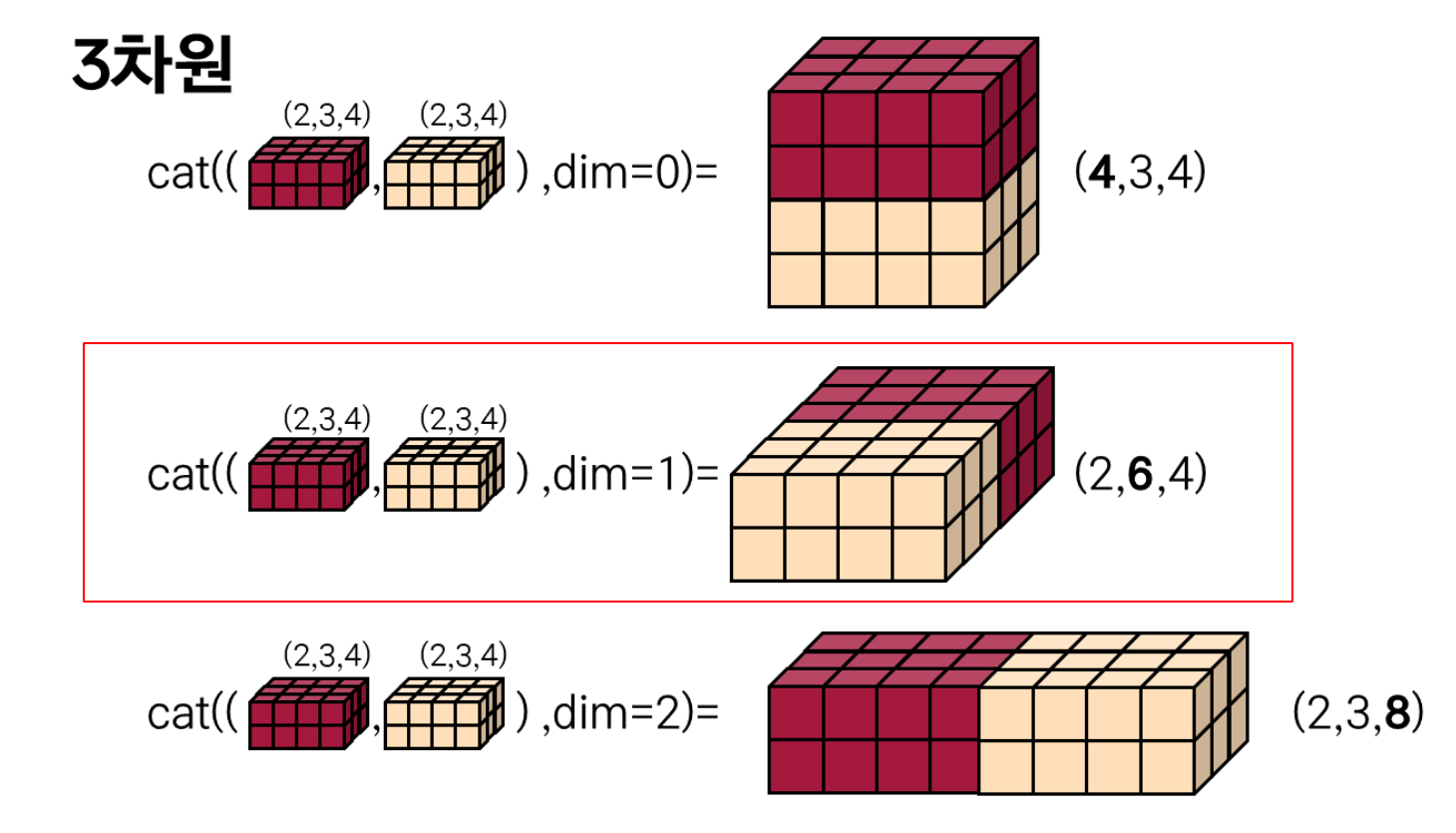
torch.cat
눈 여겨 볼 점은 dim=1인 부분인데 텐서의 shape은 (batch_size, channel, h, w)로 되어있을 것임으로 channel 뒤에 이어 붙어진다.
예를들어 in_channels=48 이고 out_channels=480이라면 최종 output channel은 out_channels - in_channels 임으로 480-48=432값을 갖는다.
이후 432channel을 갖는 최종 결과에 Residual connecton을 적용할 때 stride=2인 경우 in_channels와 output channel을 torch.cat하여 432+48=480으로 복원된다. 이 이유 때문에 위에서 outputs = oup - inp if stride==2 조건을 넣은 것이다.

Channel Shuffle
아래 channel shuffle을 적용하는 경우 어떻게 작동되는지 알아본다.
x는 (batch_size, c, h, w)인 4차원의 dimension으로 이뤄져 있다. 이해를 쉽게 하기 위해 batch를 고려하지 않고 설명한다.
예를들어 (48, 112, 112) 로 구성되어 있다면 channel을 groups의 약수로 쪼개는 것이다.
groups=3이라 해보자.
- num_channels을 groups=3으로 나눈다 → 16
- x = x.reshape(groups_channels, self.group, h, w) → 4dim을 갖는 (16, 3, 112, 112) 의 꼴로 변경
- x = x.permute(1, 0, 2, 3) → (3, 16, 112, 112) 형태로 groups_channel과 groups를 맞바꾼다.
- x = x.reshape(num_channels, h, w) → (3*16, 112, 112) 로 변경한다.
그럼 왜 저렇게 하면 차원이 shuffle되는지 궁금할 수 있다. 따라서 아래 직접 sample을 만들어 실험을 해보았다.
shape (h, w, c)
아래 코드를 통해 (h, w, c)형태의 (5, 7, 6)의 Image를 만든다고 가정한다.
import numpy as np
import torch
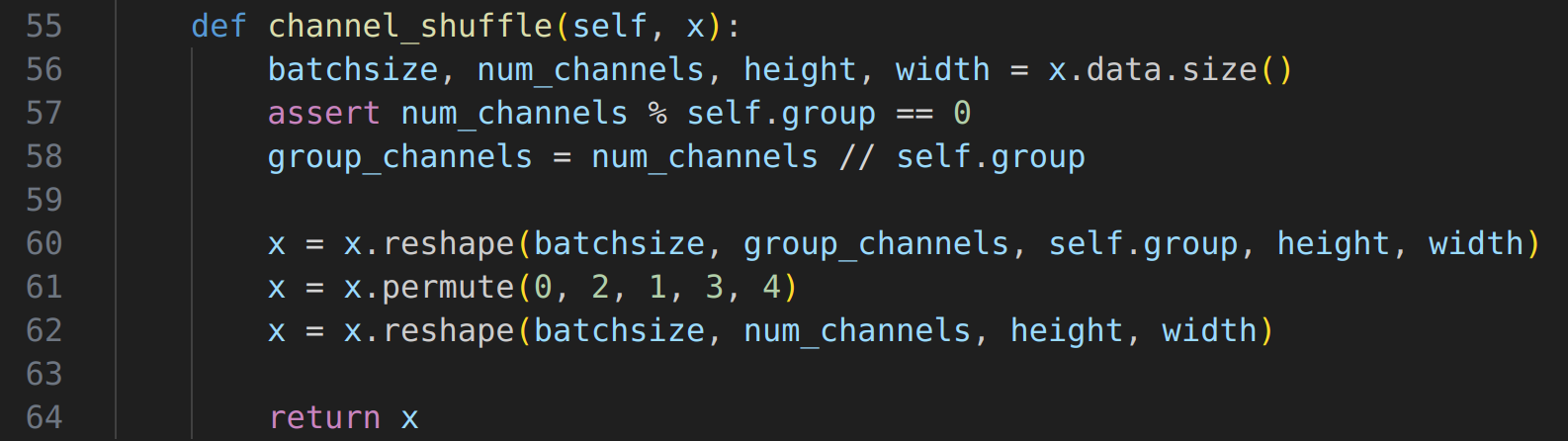
torch.manual_seed(42)
arr = np.random.randint(0, 10, size=(5, 7, 6)) # (h, w, c)
arr = torch.tensor(torch.tensor(arr))
print(f"(h, w, c)_image:{arr.shape}")
print(arr)결과:
(h, w, c)_image:torch.Size([5, 7, 6])
tensor([[[0, 6, 1, 1, 5, 9],
[4, 2, 5, 1, 6, 8],
[3, 4, 1, 1, 1, 5],
[6, 0, 7, 3, 8, 6],
[8, 2, 0, 5, 0, 8],
[7, 1, 3, 5, 6, 2],
[8, 9, 9, 8, 4, 3]],
[[1, 7, 9, 4, 9, 8],
[9, 0, 3, 8, 9, 7],
[4, 5, 6, 7, 0, 0],
[1, 9, 3, 8, 8, 5],
[8, 3, 1, 7, 2, 8],
[3, 8, 3, 3, 8, 4],
[2, 6, 6, 7, 4, 8]],
[[9, 0, 9, 8, 7, 9],
[1, 3, 0, 0, 6, 7],
[2, 3, 4, 9, 3, 7],
[3, 5, 1, 6, 1, 0],
[9, 4, 1, 7, 4, 4],
[6, 0, 5, 8, 2, 9],
[5, 2, 0, 4, 5, 0]],
[[3, 2, 9, 1, 5, 4],
[9, 5, 4, 7, 1, 1],
[3, 2, 2, 5, 1, 9],
[4, 0, 8, 4, 4, 1],
[5, 5, 1, 4, 7, 1],
[3, 8, 3, 4, 4, 0],
[8, 7, 0, 7, 4, 9]],
[[0, 6, 1, 8, 2, 0],
[5, 0, 4, 3, 6, 7],
[0, 5, 7, 3, 6, 9],
[9, 0, 5, 0, 3, 7],
[0, 3, 0, 9, 8, 4],
[0, 8, 1, 3, 3, 0],
[0, 8, 4, 8, 6, 8]]])왜 위와 같은 형태로 나오는지 궁금하다면 페이지를 봐보자. 3D Array
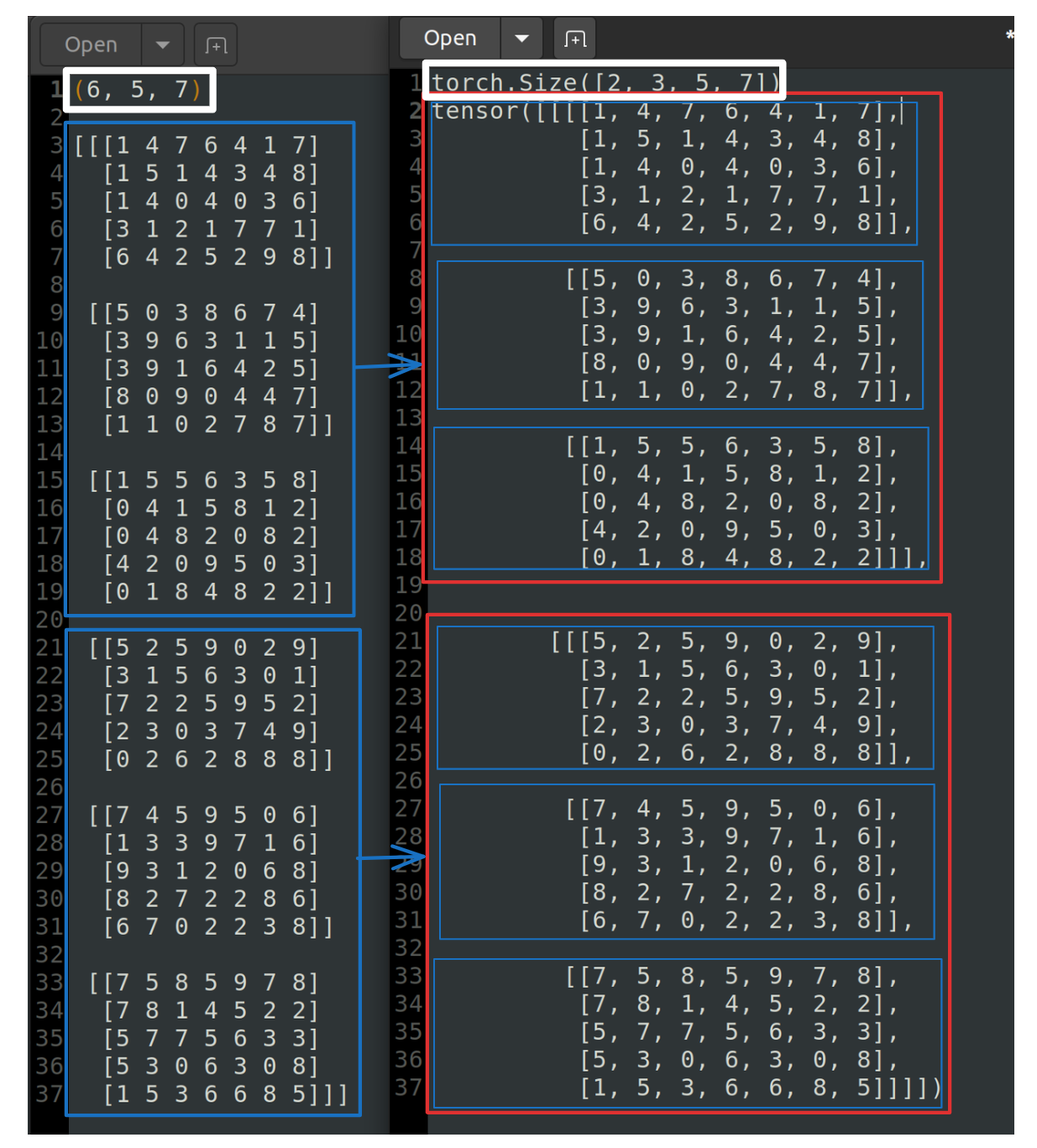
(h, w, c) → (c, h, w)
이후 transpose를 적용해 (c, h, w) 형태로 shape을 변경한다.
transpose_arr = np.transpose(arr,(2, 0, 1)) # (6, 2, 4)
print(f"(c, h, w)_image:{transpose_arr.shape}")
print(transpose_arr)결과:
(c, h, w)_image:torch.Size([6, 5, 7])
tensor([[[0, 4, 3, 6, 8, 7, 8],
[1, 9, 4, 1, 8, 3, 2],
[9, 1, 2, 3, 9, 6, 5],
[3, 9, 3, 4, 5, 3, 8],
[0, 5, 0, 9, 0, 0, 0]],
[[6, 2, 4, 0, 2, 1, 9],
[7, 0, 5, 9, 3, 8, 6],
[0, 3, 3, 5, 4, 0, 2],
[2, 5, 2, 0, 5, 8, 7],
[6, 0, 5, 0, 3, 8, 8]],
[[1, 5, 1, 7, 0, 3, 9],
[9, 3, 6, 3, 1, 3, 6],
[9, 0, 4, 1, 1, 5, 0],
[9, 4, 2, 8, 1, 3, 0],
[1, 4, 7, 5, 0, 1, 4]],
[[1, 1, 1, 3, 5, 5, 8],
[4, 8, 7, 8, 7, 3, 7],
[8, 0, 9, 6, 7, 8, 4],
[1, 7, 5, 4, 4, 4, 7],
[8, 3, 3, 0, 9, 3, 8]],
[[5, 6, 1, 8, 0, 6, 4],
[9, 9, 0, 8, 2, 8, 4],
[7, 6, 3, 1, 4, 2, 5],
[5, 1, 1, 4, 7, 4, 4],
[2, 6, 6, 3, 8, 3, 6]],
[[9, 8, 5, 6, 8, 2, 3],
[8, 7, 0, 5, 8, 4, 8],
[9, 7, 7, 0, 4, 9, 0],
[4, 1, 9, 1, 1, 0, 9],
[0, 7, 9, 7, 4, 0, 8]]])아래 그림과 같이 하나의 열이 채널을 의미하는데(6채널이기 때문에 6열) 이 열이 하나의 Matrix로 형성되는 것을 볼 수 있다.
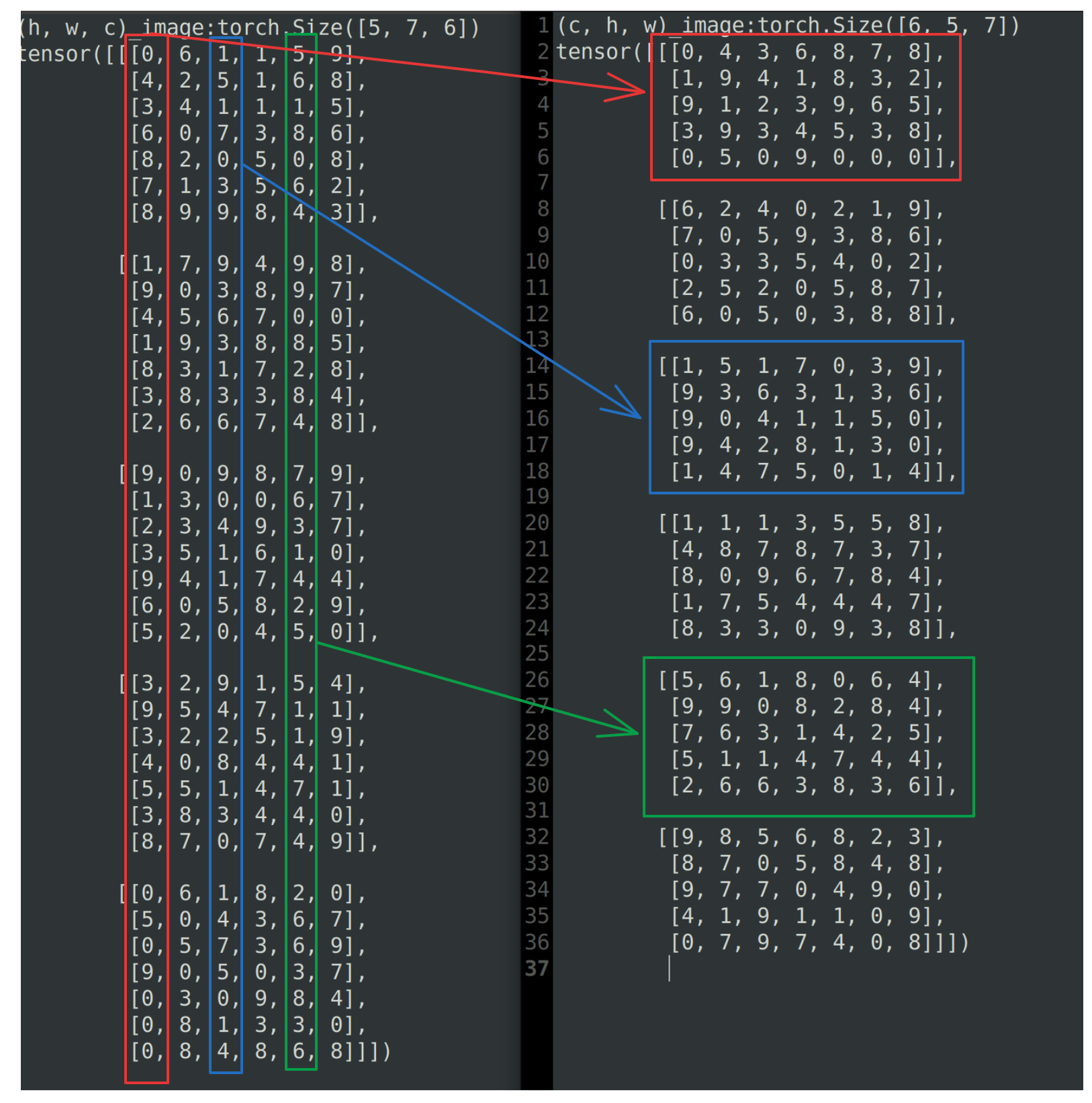
(c, h, w) → (group_channels, group, h, w)
group=3으로 설정하고 group_channel = c // group을 진행한다.
c=6이였음으로 group_channel=2가 되어 (2, 3, 5, 7) 형태의 shape이 만들어진다.
group = 3
group_channels = 6 // group
dst_transpose_arr = transpose_arr.reshape(group_channels, group, 5, 7) # (2, 3, 5, 7)
print(f"(group_channel, group, h, w)_image:{dst_transpose_arr.shape}")
print(dst_transpose_arr)결과:
(group_channel, group, h, w)_image:torch.Size([2, 3, 5, 7])
tensor([[[[0, 4, 3, 6, 8, 7, 8],
[1, 9, 4, 1, 8, 3, 2],
[9, 1, 2, 3, 9, 6, 5],
[3, 9, 3, 4, 5, 3, 8],
[0, 5, 0, 9, 0, 0, 0]],
[[6, 2, 4, 0, 2, 1, 9],
[7, 0, 5, 9, 3, 8, 6],
[0, 3, 3, 5, 4, 0, 2],
[2, 5, 2, 0, 5, 8, 7],
[6, 0, 5, 0, 3, 8, 8]],
[[1, 5, 1, 7, 0, 3, 9],
[9, 3, 6, 3, 1, 3, 6],
[9, 0, 4, 1, 1, 5, 0],
[9, 4, 2, 8, 1, 3, 0],
[1, 4, 7, 5, 0, 1, 4]]],
[[[1, 1, 1, 3, 5, 5, 8],
[4, 8, 7, 8, 7, 3, 7],
[8, 0, 9, 6, 7, 8, 4],
[1, 7, 5, 4, 4, 4, 7],
[8, 3, 3, 0, 9, 3, 8]],
[[5, 6, 1, 8, 0, 6, 4],
[9, 9, 0, 8, 2, 8, 4],
[7, 6, 3, 1, 4, 2, 5],
[5, 1, 1, 4, 7, 4, 4],
[2, 6, 6, 3, 8, 3, 6]],
[[9, 8, 5, 6, 8, 2, 3],
[8, 7, 0, 5, 8, 4, 8],
[9, 7, 7, 0, 4, 9, 0],
[4, 1, 9, 1, 1, 0, 9],
[0, 7, 9, 7, 4, 0, 8]]]])기존 (6, 5, 7) → (2, 3, 5, 7) 로 reshape한 경우의 모습이다
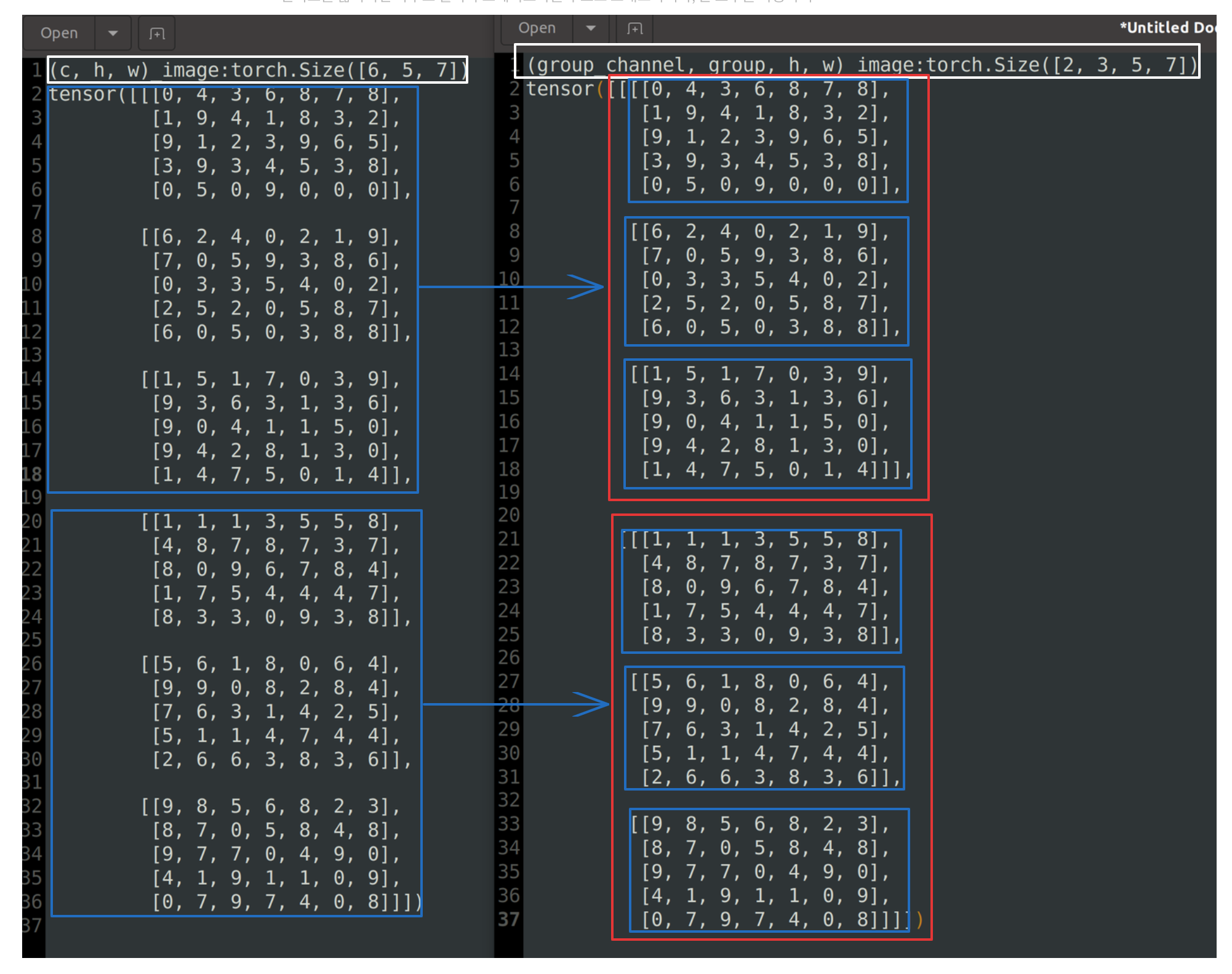
(group_channels, group, h, w) → (group, group_channels, h, w)
permute 함수를 사용해 (2, 3, 5, 7) → (3, 2, 5, 7) 의 형태로 만들준다.
dst_transpose_arr2 = dst_transpose_arr.permute(1, 0, 2, 3) # (3, 2, 5, 7)
print(f"(group, group_channel, h, w)_image:{dst_transpose_arr2.shape}")
print(dst_transpose_arr2)결과:
(group_channel, group, h, w)_image:torch.Size([2, 3, 5, 7])
tensor([[[[0, 4, 3, 6, 8, 7, 8],
[1, 9, 4, 1, 8, 3, 2],
[9, 1, 2, 3, 9, 6, 5],
[3, 9, 3, 4, 5, 3, 8],
[0, 5, 0, 9, 0, 0, 0]],
[[6, 2, 4, 0, 2, 1, 9],
[7, 0, 5, 9, 3, 8, 6],
[0, 3, 3, 5, 4, 0, 2],
[2, 5, 2, 0, 5, 8, 7],
[6, 0, 5, 0, 3, 8, 8]],
[[1, 5, 1, 7, 0, 3, 9],
[9, 3, 6, 3, 1, 3, 6],
[9, 0, 4, 1, 1, 5, 0],
[9, 4, 2, 8, 1, 3, 0],
[1, 4, 7, 5, 0, 1, 4]]],
[[[1, 1, 1, 3, 5, 5, 8],
[4, 8, 7, 8, 7, 3, 7],
[8, 0, 9, 6, 7, 8, 4],
[1, 7, 5, 4, 4, 4, 7],
[8, 3, 3, 0, 9, 3, 8]],
[[5, 6, 1, 8, 0, 6, 4],
[9, 9, 0, 8, 2, 8, 4],
[7, 6, 3, 1, 4, 2, 5],
[5, 1, 1, 4, 7, 4, 4],
[2, 6, 6, 3, 8, 3, 6]],
[[9, 8, 5, 6, 8, 2, 3],
[8, 7, 0, 5, 8, 4, 8],
[9, 7, 7, 0, 4, 9, 0],
[4, 1, 9, 1, 1, 0, 9],
[0, 7, 9, 7, 4, 0, 8]]]])(3, 2, 5, 7) 의 변환된 결과는 아래와 같다.
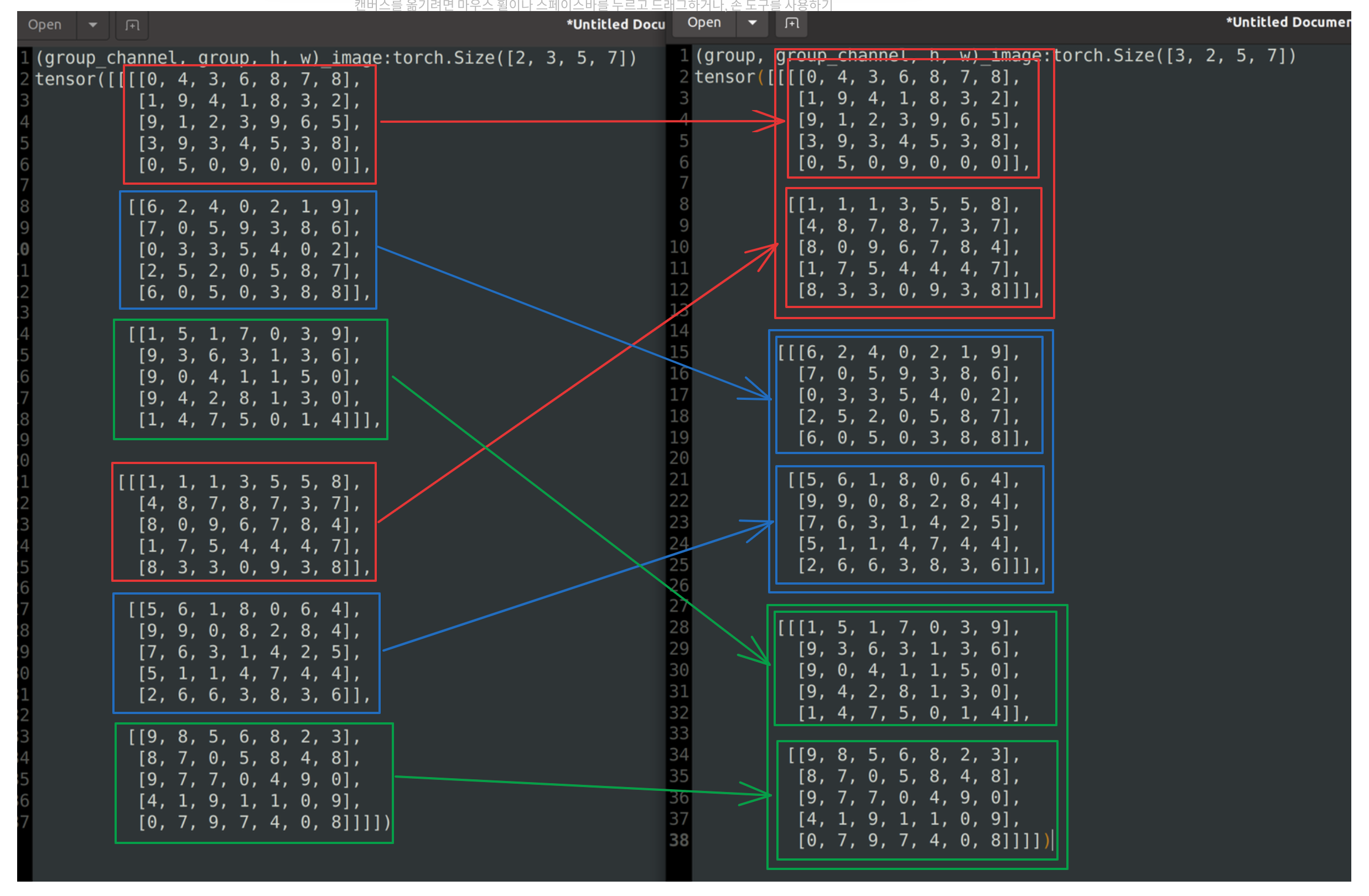
(group, group_channels, h, w) → (c, h, w)
(3, 2, 5, 7)로 된 상태에서 다시 (6, 5, 7)로 변경해준다.
dst_transpose_arr3 = dst_transpose_arr2.reshape(group_channels*group, 5, 7)
print(f"(group*group_channel, h, w)_image:{dst_transpose_arr3.shape}")
print(dst_transpose_arr3)아래는 변경한 결과이다.
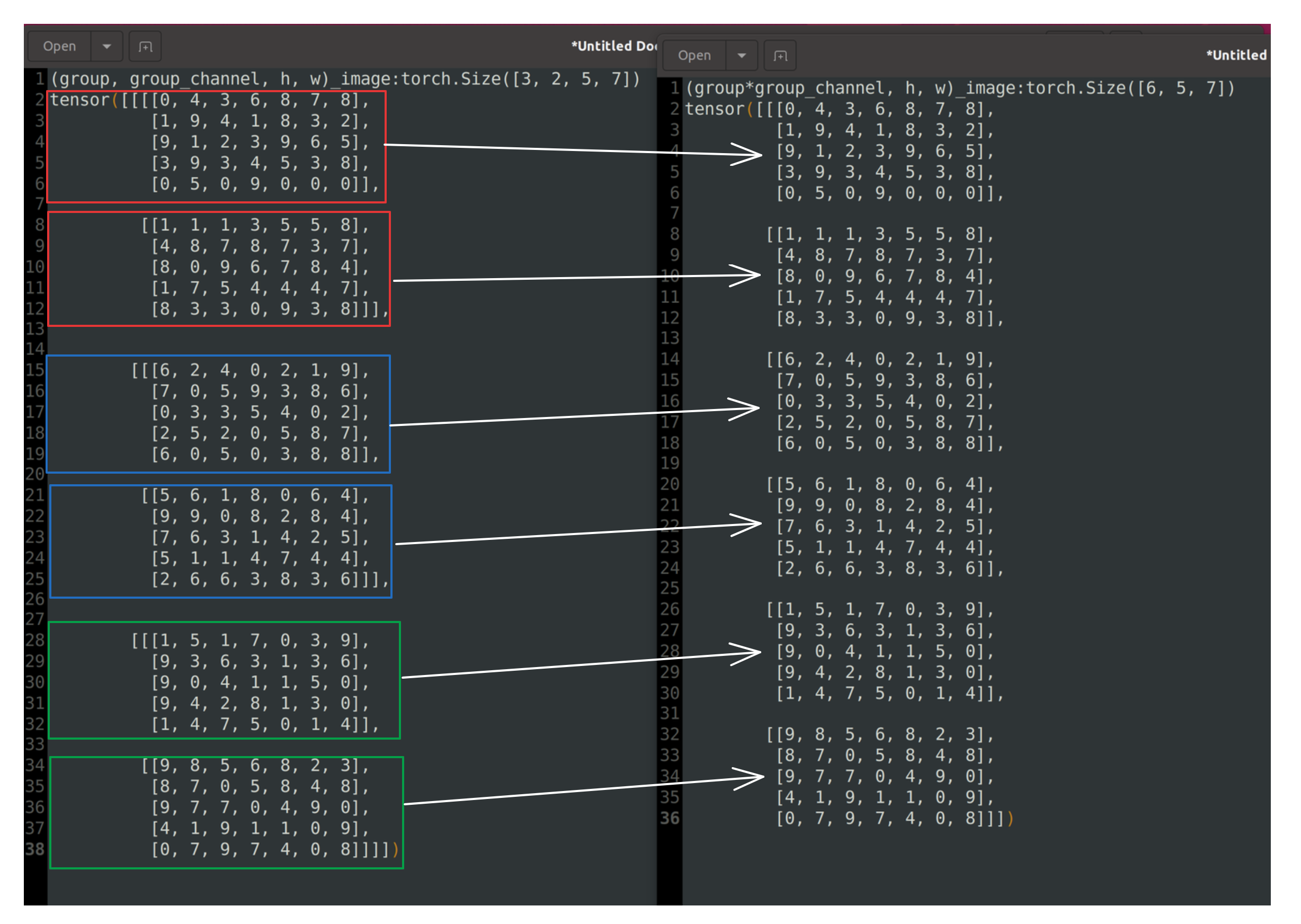
Summery
6개의 채널을 가진 5x7 크기의 입력 텐서를 가지고 있다 하자.
이 텐서의 각 채널을 C1, C2, C3, C4, C5, C6라고 하자
- 원래 채널: [C1, C2, C3, C4, C5, C6]
- 그룹화: [[C1, C2, C3], [C4, C5, C6]]
- 채널 셔플: [[C1, C4], [C2, C5], [C3, C6]]
- 결과: [C1, C4, C2, C5, C3, C6]
Flow: [C1, C2, C3, C4, C5, C6] → [C1, C2, C3], [C4, C5, C6] → [C1, C4], [C2, C5], [C3, C6] → [C1, C4, C2, C5, C3, C6]
[C1, C2, C3], [C4, C5, C6] → [C1, C4], [C2, C5], [C3, C6] → [C1, C4, C2, C5, C3, C6]
(2, 3, 5, 7) → (3, 2, 5, 7) → (6, 5, 7)
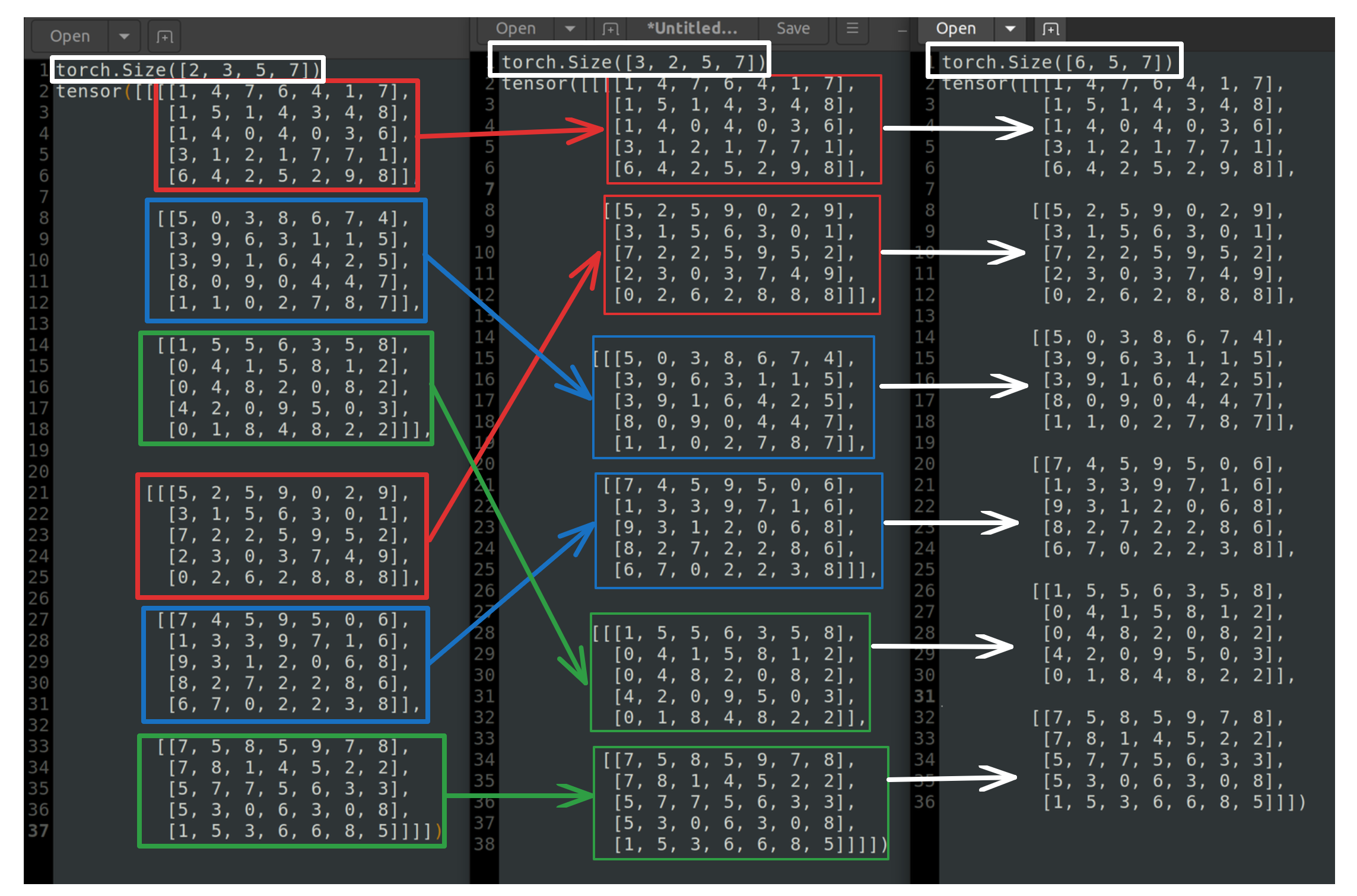
위 최종 결과를 보면 처음과 비교했을 때 채널의 순서가 바뀜을 볼 수 있다.
예시 전체 코드
import numpy as np
import torch
torch.manual_seed(42)
arr = np.random.randint(0, 10, size=(5, 7, 6)) # (h, w, c)
arr = torch.tensor(torch.tensor(arr))
print(f"(h, w, c)_image:{arr.shape}")
print(arr)
print('='*50)
transpose_arr = np.transpose(arr,(2, 0, 1)) # (6, 2, 4)
print(f"(c, h, w)_image:{transpose_arr.shape}")
print(transpose_arr)
print('='*50)
group = 3
group_channels = 6 // group
dst_transpose_arr = transpose_arr.reshape(group_channels, group, 5, 7) # (2, 3, 5, 7)
print(f"(group_channel, group, h, w)_image:{dst_transpose_arr.shape}")
print(dst_transpose_arr)
print('='*50)
dst_transpose_arr2 = dst_transpose_arr.permute(1, 0, 2, 3) # (3, 2, 5, 7)
print(f"(group, group_channel, h, w)_image:{dst_transpose_arr2.shape}")
print(dst_transpose_arr2)
print('='*50)
dst_transpose_arr3 = dst_transpose_arr2.reshape(group_channels*group, 5, 7)
print(f"(group*group_channel, h, w)_image:{dst_transpose_arr3.shape}")
print(dst_transpose_arr3)forward
x = (1, 3, 224, 224)
x = self.first_conv(x) 를 적용해 처음에 input_size를 절반으로 줄인다. → (1, 48, 112, 112)
x = self.maxpool(x): stride=2를 적용해 한번 더 input_size를 절반으로 줄인다. → (1, 48, 56, 56)
x = self.features(x): 4block → 8block→ 4block 을 지나게되면 → (1, 1920, 7, 7)
x = self.globalpool(x) : 7x7kernel을 적용해 (1, 1920, 1, 1)로 줄인다.
x = x.contiguous().view(-1, self.stage_out_channels[-1]: (1, 1920)
x = self.classifier(x) : 1920개의 노드가 input으로, output feature가 1000개가 나오도록 한다.

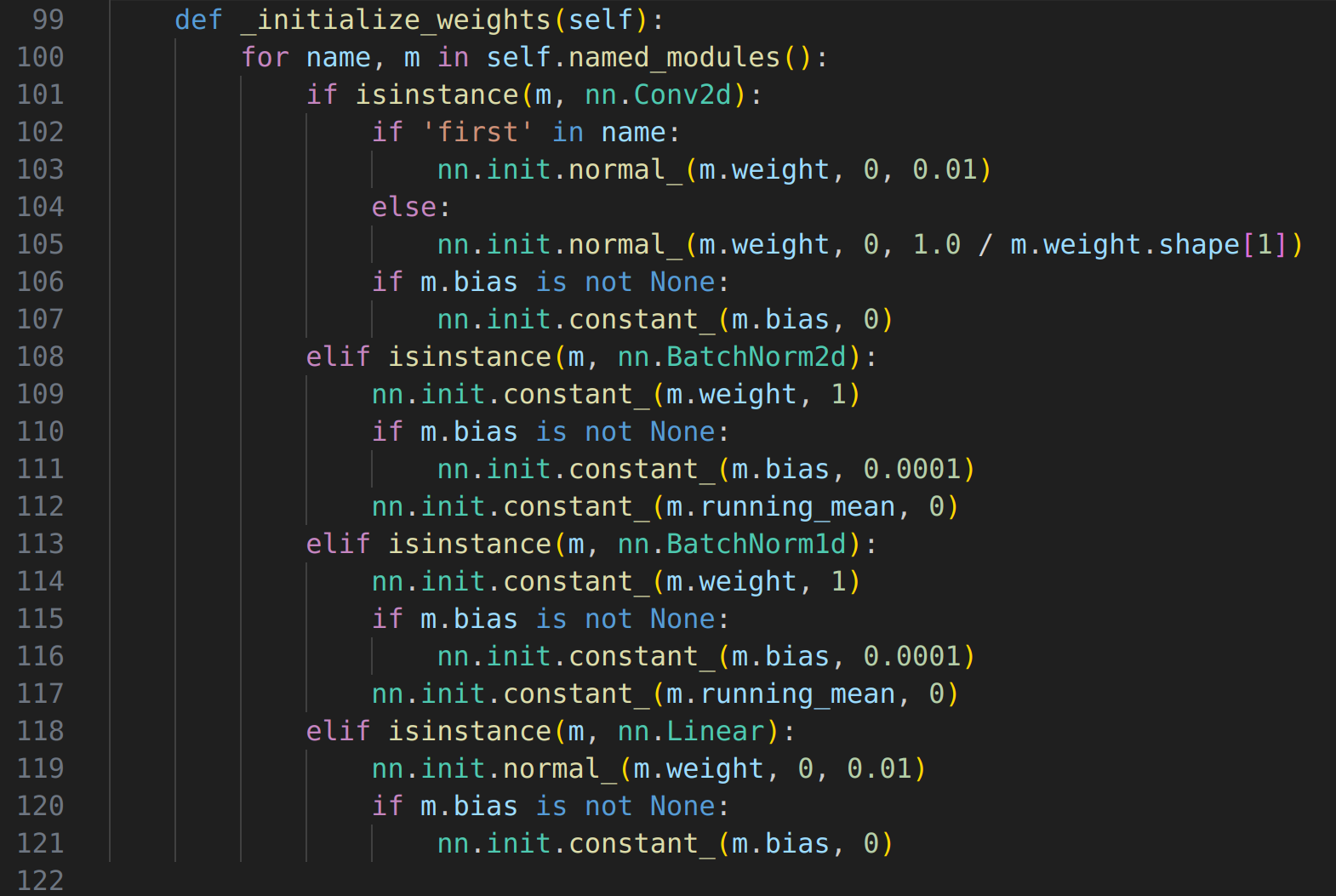
weight initialize
name: 모듈의 이름으로 전체 모델에서 고유해야하며 layer의 이름을 나타낸다.m: 모듈의 객체로 이 객체를 통해 해당 모듈의 메소드와 속성에 접근할 수 있다. 예를 들어, 가중치를 초기화하거나 모듈의 출력을 계산하는 등의 작업을 수행할 수 있다.
name은 layer 이름을 의미하고 m은 해당 layer의 가중치를 의미한다.
nn.init.normal_(m.weight, 0, 0.01): layer의 가중치를 평균이 0 표준편차가 0.01인 정규분포로 초기화한다.
nn.init.normal_(m.weight, 0, 0.01/ m.weight.shape[1]): 표준편차를 채널 dimension으로 나눈다.
nn.init.constant(m.bias, 0): m.bias의 값을 상수 0의 값으로 초기화한다.
아래 몇가지 혼동 요소에 대해서 설명한다.
Permute 와 reshape 차이
permute는 차원 간의 순서를 바꿀 때 사용하고, reshape는 텐서의 형상 자체를 바꿀 때 사용한다.
view, reshape의 차이점 보러가기 View, Reshape 차이
Conclusion
위 에서 설명했던 channel shuffle에서 group을 3으로 주어 아래와 같은 식으로 채널을 섞는다.
[C1, C2, C3, C4, C5, C6] → [C1, C2, C3], [C4, C5, C6] → [C1, C4], [C2, C5], [C3, C6] → [C1, C4, C2, C5, C3, C6]
근데 group=3이라는 의미는 3개의 그륩으로 나누고 각 그륩에는 2개의 채널이 솎한다는 뜻이다.
따라서 [C1, C2, C3, C4, C5, C6] → [C1, C2], [C3, C4], [C5, C6]로 나눠져야 한다 생각한다.
이후 [C1, C3, C5], [C2, C4, C6] → [C1, C3, C5, C2, C4, C6] 되야 좀더 convolution의 group의 의미와 비슷하지 않을까 싶다.
group의 의미를 좀 더 갖는 flow로 하고싶다면 group과 group_channels의 위치만 바꿔주면 된다.
변경 전 : x = x.reshape(batchsize, group_channels, self.group, height, width)
변경 후 : x = x.reshape(batchsize, self.group, group_channels, height, width)
전체 코드
[reference]
https://github.com/megvii-model/ShuffleNet-Series/tree/master/ShuffleNetV1
Comment