
Cite
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, Xiaolong Wang; arXiv preprint arXiv:2412.04453 [cs.RO]
- https://arxiv.org/pdf/2412.04453
- 출간일: 2024. 12. 06
- 저널: arXiv (Robotics [cs.RO] category)
Abstract
최근의 대규모 시각–언어(Vision–Language) 모델들은 인터넷에서 수집된 방대한 이미지–문장 데이터를 학습함으로써, 언어와 시각 정보를 통합적으로 이해하고 보지 못한 과제도 유연하게 처리하는 일반화(generalization) 능력을 보여왔다.
이 논문에서는 이러한 시각–언어 모델의 일반화 능력을 로봇 제어(Robotic Control) 영역으로 확장하는 방법을 제시한다. 즉, 웹에서 학습한 지식을 실제 로봇의 행동으로 연결하여, 로봇이 스스로 환경을 이해하고 합리적으로 행동할 수 있도록 하는 것이다.
이를 위해 저자들은 언어(Language), 시각(Vision), 행동(Action) 을 하나의 모델 안에서 통합적으로 학습하는 비전–언어–행동(Vision–Language–Action, VLA) 모델 계열을 제안한다.
그중 RT-2 (Robotics Transformer 2) 는 인터넷에 존재하는 방대한 데이터로부터 학습된 시각–언어 데이터와, 실제 로봇이 수행한 조작 궤적 데이터(trajectory data) 를 함께 공동 미세조정(co-fine-tuning) 하여 학습된다. 이를 통해 하나의 end-to-end 모델이 로봇의 카메라 입력(관찰, observation)을 이해하고, 그에 적절한 행동(action)을 결정함과 동시에, 인터넷에서 학습한 일반 상식적 지식(semantic knowledge) 까지도 활용할 수 있도록 설계되었다.
또한, 자연어 응답과 로봇의 행동을 동일한 형식(format) 으로 다루기 위해, 로봇의 행동(Action) 을 텍스트 토큰(text tokens) 형태로 변환하여 자연어 토큰과 동일한 방식으로 모델 학습 데이터에 포함시켰다.
이러한 접근을 통해 RT-2는 새로운 물체(novel objects) 에 대한 일반화 능력이 크게 향상되었으며,로봇 학습 데이터에 존재하지 않았던 명령어(예: 물체를 특정 숫자나 아이콘 위에 올려놓기)를 해석할 수 있는 능력과,
사용자의 명령에 따라 기본적인 추론(rudimentary reasoning) 을 수행하는 능력(예: 가장 작은 물체, 가장 큰 물체, 또는 다른 물체에 가장 가까운 물체를 선택하기)을 보여주었다.
더 나아가, 사고의 연쇄(Chain-of-Thought) 추론 방식을 통합하면 RT-2는 다단계 의미 추론(Multi-Stage Semantic Reasoning) 을 수행할 수 있음을 확인하였다.
예를 들어, 즉석에서 망치로 사용할 수 있는 물체(예: 돌) 를 선택하거나, 피곤한 사람에게 적합한 음료(예: 에너지드링크) 를 고르는 등, 상황적 의미(Contextual Semantic) 기반의 추론 능력을 발휘할 수 있다.
Introduction
대규모 웹 기반 데이터셋(web-scale datasets) 으로 사전학습(pretraining) 된 고용량(high-capacity) 모델들은, 다양한 하위 작업(downstream tasks) 을 수행하기 위한 효율적이고 강력한 플랫폼을 제공한다.
이러한 의미적 추론(semantic reasoning), 문제 해결(problem solving), 그리고 시각적 해석(visual interpretation) 능력은, 실제 환경에서 다양한 작업을 수행해야 하는 범용 로봇(generalist robots) 에게 매우 유용할 것이다.
하지만 이런 모델들은 단어 의미나 분류 라벨, 문장 지시어(prompt) 같은 언어 중심의 추상적인 개념을 다루기 때문에, 로봇이 실제로 움직일 때 필요한 정확한 위치 좌표나 팔을 어떻게 움직일지 같은 구체적인 명령으로 바로 연결하기가 어렵다. 그래서 이런 모델을 로봇 작업에 직접 사용하는 건 쉽지 않다.
최근 많은 연구들(Ahn et al., Driess et al., Vemprala)은 언어 모델(LLM)이나 시각–언어 모델(VLM)을 로봇에 활용하려는 시도를 해왔다.
하지만 이런 접근 방식은 대부분 로봇에게 “무엇을 해야 할지”를 정해주는 데만 집중돼 있었다.
예를 들어, “컵을 집어서 테이블 위에 올려”라는 명령을 받으면, 이걸 ‘집기 → 옮기기 → 놓기’ 같은 작은 행동들(primitive)로 쪼개주는 기계처럼 동작한다.
이후 실제로 로봇이 움직이는 건 저수준 제어기(low-level controller)가 맡는다.
예를 들어, 로봇 팔이 몇 도 회전하고, 손가락이 어느 정도 힘으로 집을지 같은 부분이다. 하지만 이 저수준 제어기는 언어 모델이 가진 방대한 지식(예: 컵은 쉽게 깨진다, 물건을 부드럽게 다뤄야 한다 등)을 직접적으로 활용하지 못한다.
이를 해결하기 위해 위해 대규모 사전학습된 시각–언어 모델(VLMs) 을 로봇의 저수준 제어(low-level control) 에 직접 통합하여, 일반화 능력(generalization) 을 향상시키고 새로운 의미적 추론(emergent semantic reasoning)을 가능하게 만드는 것을 제안한다.
- 제안된 방식:
- 기존의 잘 훈련된 VLM을 재활용
- 새로운 파라미터 없이, 로봇 동작을 텍스트처럼 학습
- → 단순하면서도, 실제 로봇에게 명령을 이해하고 행동하게 하는 데 효과적
RT-1 → RT-2
RT-1: 로봇시연 데이터만으로 학습시킴
1. EfficientNet-B3 → 이미지 피처맵 추출
• 입력: 300×300 해상도의 이미지 6장
• 출력: 9×9×512 형태의 시각 피처맵 (공간 9×9, 채널 512)
2. USE → 문장 임베딩(512-D) 추출
• 입력: 명령문 (예: “pick up the red apple”)
• 출력: 512-차원 문장 벡터
3. FiLM(Feature-wise Linear Modulation) 적용
• USE에서 나온 512-D 문장 임베딩을 통해
채널별 스케일링 γ와 쉬프트 β를 계산 → 이미지 피처맵에 적용
• 여기서 γ, β는 각각 512차원의 벡터 → 512개 채널에 대응
• 결과적으로, 명령문의 의미(“빨간 사과”)에 따라
관련 채널이 강조되고 비관련 채널은 약화됨
4. Flatten → Transformer 입력
• 9×9 공간 위치를 평탄화 → 81개의 시각 토큰 (각각 512-D)
• 이 토큰들이 Transformer의 입력으로 사용됨RT-2: 인터넷에서 대규모로 학습된 (Vision–Language Model, VLM)을 활용한다.
동작원리
VLM(Vision-Language Model)이 폐루프(closed-loop) 로봇 제어를 직접 수행할 수 있도록 훈련하기 위한 모델 계열과 설계 선택사항을 제시한다.
closed-loop: 로봇이 주변을 관찰(카메라 입력)하고 VLM이 그 입력을 보고 행동을 결정한다. 로봇이 행동하고 그 결과를 다시 카메라로 관찰하여 상황이 바뀌었으면 다음 행동을 다시 판단하는 것을 의미한다. 즉, 관찰 - 행동 - 관찰 - 행동 .. 이 반복되는 것이 closed-loop 구조이다.
본 연구에서는 기존에 제안된 두 가지 VLM(PaLI-X와 PaLM-E)을 사용하여 VLA 모델로 확장했다.
각 모델이 적용된 VLA을 각각 RT-2-PaLI-X 및 RT-2-PaLM-E라 부른다.
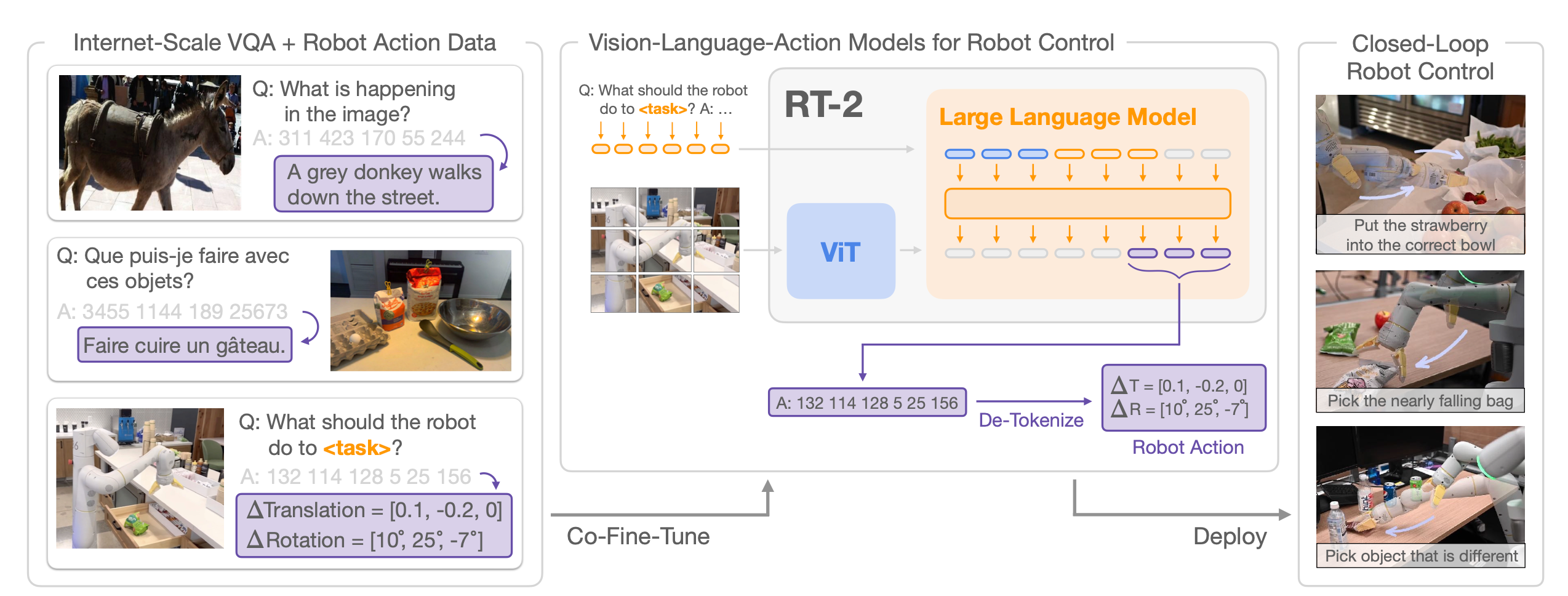
비전–언어 모델이 로봇을 제어할 수 있도록 하려면, 이 모델이 행동(action)을 출력하도록 훈련되어야 한다.
따라서 로봇의 동작(action)을 모델 출력의 토큰(token)으로 표현한다. 이 action token은 RT-1의 방식을 사용한다.
- 원래 로봇의 동작(action)은 (x, y, z, roll, pitch, yaw, gripper 상태 등) 같은 연속적인 실수값이다.
- 그런데 Vision-Language Model (예: PaLM, BERT 등)은 텍스트 토큰을 처리한다.
- → 예: “apple” → 3212, “pick” → 9134 이런 식의 정수 토큰
- 연속적인 로봇의 행동 값을 256개의 구간(bin) 각 행동 요소를 0~255 사이의 정수(token)로 표현한다.
- -1m ~ 1 m구간을 전체범위라고 해보자. 그럼 각 구간의 값은 아래와 같다.
\[\frac{(+1.0 - (-1.0))}{256} = \frac{2.0}{256} = 0.0078125 \text{ m}\] - 만약 로봇이 0.3m를 가야한다면 -1.0m로 부터 얼마나 떨어져 있는지 계산해본다.
- 0.3 - (-1.0) = 1.3m
- 그 다음 1.3m가 구간 몇개 만큼 떨어져 있는지 보면된다.
- 1.3 / 0.0078125 = 166.4
- 토큰은 정수임으로 [166.4] = 166
- 따라서 토큰 166은 대략적으로 0.3m인 실수값을 의미한다.
- 따라서 VLA 모델의 출력이 0.3m가 나오면 이를 양자화하여 166인 정수토큰으로 표현하는 것이다.
그리고 이러한 256개의 액션 토큰들을 VLM의 tokenization에 추가하였다.
- 왜냐하면 기존 VLM Vocab에는 “apple”, “robot”, “pick”, “grasp” 같은 단어는 잘 다루나,
- “x=0.3 → 토큰 166” 이라고 해도 모델은 그걸 어떤 의미 있는 토큰으로 인식하지 못한다.
- 따라서 이 액션 토큰의 의미를 연결시켜주는 것이 필요하다.
PaLI-X의 경우, 정수를 나타내는 1000개의 고유한 토큰을 가지고 있기 때문에 해당 토큰을 액션토큰으로 매칭한다.
그러나 PaLM-E의 경우는 숫자 표현 방식 토큰을 제공하지 않기 때문에, 가장 적게 사용되는 256개의 토큰을 덮어써 행동 어휘(action vocabulary)를 표현하도록 설정한다.
모델 입/출력
- 카메라의 이미지와 task에 대한 설명을 VQA형태로 넣어주고 출력은 action token이 되도록 하였다.
Co-Fine-Tuning
- 로봇 데이터와 웹에서 수집한 데이터를 함께 학습시켰다.
- 웹 규모 데이터에서 얻은 추상적 데이터와 저수준 로봇데이터를 함꼐 학습하여 더 일반화 가능한 정책(generalizable policy)을 학습하게 된다.
Output Constraint
- RT-2와 기존의 VLM의 가장 큰 차이점은 action token을 출력한다는 것이다.
- 따라서 모델 자체는 모든 자연어를 출력할 수 있지만 de-tokenize를 진행할 때 강제로 action token만 출력할 수 있도록 제한한다.
Real-time Inference
- 최근 VLM은 수십억에서 수백억 개의 파라미터를 가질 정도로 매우 크다.
- 본 연구에서 훈련된 가장 큰 모델은 550억(55B) 개의 파라미터를 사용한다.
- 이러한 대형 모델은 일반 데스크탑 컴퓨터나 로봇 내 GPU에서는 실시간 제어(real-time control)용으로 직접 실행하기 어려워 다중 TPU 기반 클라우드 서비스(multi-TPU cloud service)에 배포하고, 로봇이 네트워크를 통해 해당 서비스를 질의(query)하는 프로토콜을 개발했다.
- 이 프로토콜을 사용해 가장 큰 모델RT-2-PaLI-X-55B는 1~3 Hz의 주기로 동작하며 그보다 작은 5B 파라미터 모델은 약 5 Hz로 동작한다.
- 5Hz는 1초에 5개의 액션을 취할 수 있다.
chain of thought(CoT): 어떤 결론에 도달하기까지 머릿속에서 일어나는 논리적인 단계들을 차례대로 설명하거나 나열하는 것을 말한다. 즉, AI가 답을 내기 전에 스스로 추론 단계를 말하게 하는 기술
Experiments
학습에 사용된 데이터로는 기존의 web scale 데이터셋과 13대의 로봇으로 17개월에 걸친 주방 환경에서의 데이터를 수집하여 사용하였다. Baseline으로는 RT-1, VC-1, R3M 등의 모델을 사용하였다.
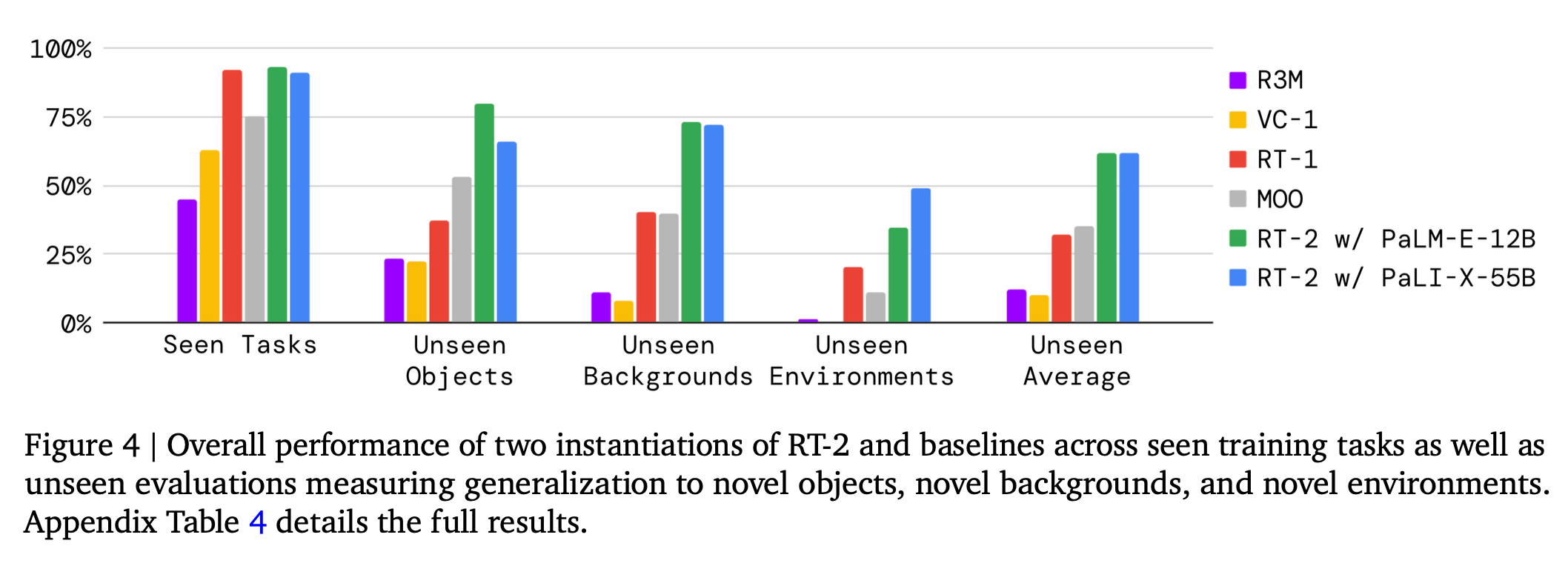
그림을 보면 Seen task에 대해서는 대부분의 모델이 성능이 좋지만, Unseen task에서의 generalization 성능은 RT-2 모델이 더 높다. 이는 기존 모델들에 비해 몇배는 더 높은 성공률이다.
RT-2만의 새로운 능력을 관찰 할 수 있는가?
- 모델이 사람처럼 언어를 “이해”하고 반응하는지 확인
Symbol Understanding “사과를 숫자 3 위에 놓아라” 숫자, 하트 아이콘, 심볼 등을 인식하고 행동 Reasoning “같은 색 컵 옆에 사과를 놓아라” 색상 매칭, 수학 추론, 시각적 추론 Human Recognition “안경 쓴 사람에게 콜라를 가져다줘” 사람 인식 및 시맨틱 관계 이해 - Ablation (b)
- Figure 6. RT-1과 VC-1 그리고 두가지 VLM 모델을 이용한 버전을 비교하였다.

RT-2로 VLM과 같은 Chain-of-thought Reasoning이 가능하였다.

Limitation
비전-언어 모델(VLM)을 통해 웹에서 대규모로 학습을 시키면, 로봇이 단어나 문장의 의미를 훨씬 잘 이해한다는 것이 증명되었다. 예를 들어 “테이블 위의 파란 컵을 들어 올려라”라고 하면, ‘테이블’, ‘위’, ‘파란 컵’ 같은 단어가 무엇을 의미하는지, 그리고 어떤 물체를 가리키는지를 더 정확하게 파악할 수 있다.
기존 동작으로 응용은 가능하나 새로운 동작은 불가능
- 그리고 RT-2는 기존 ‘집기’ 동작을 공간적으로 다르게 응용할 수는 있지만 완전히 새로운 ‘밀어내기’와 같은 동작을 하지는 못한다. 예를들어 학습데이터에 없는 “병뚜껑을 돌려서 열어라” 같은 경우 이건 손목을 회전시키는 복합 동작(회전 + 압력 조절)이 필요한다 로봇은 학습한 적이 없기 때문에 수행 불가하다.
- VLM 사전학습 덕분에 “병뚜껑을 열어라”라는 문장의 의미는 이해하지만, “손목을 돌리고 힘을 조절해야 한다”는 물리적 행동 방식은 모르기 때문에 실제로 수행은 못한다는 것이다.
Real-time-inference
- 대규모 VLA(Vision-Language-Action) 모델을 실시간(real time)으로 실행할 수 있음을 보여주었지만, 이들 모델의 연산 비용(computation cost)은 매우 높아 고주파 제어(high-frequency control)가 요구되는 환경에 적용될 경우, 실시간 추론(real-time inference)이 주요 병목(bottleneck)이 될 수 있다.
- 향후 연구에서 흥미로운 방향은, 이러한 모델이 더 빠른 속도 또는 저비용 하드웨어에서 동작할 수 있도록 하는 quantization 및 distillation 기법을 탐구하는 것이다.
[reference]
Comment