
Cite
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, et al.; arXiv preprint arXiv:2212.06817 [cs.RO]
- https://arxiv.org/pdf/2212.06817
- 출간일: 2022. 12. 13
- 저널: arXiv (Robotics [cs.RO] category)
Abstract
현대 머신러닝 모델들은 큰 규모의 다양하고 범용적인(task-agnostic) 데이터셋으로 사전학습됨으로써, zero-shot 또는 few-shot만으로도 downstream 과제를 잘 수행할 수 있다.
이러한 일반화 능력은 컴퓨터 비전, 자연어 처리, 음성 인식 등 분야에서는 입증되었지만, 로봇 제어 분야에서는 데이터 수집의 어려움 때문에 동일한 패러다임이 잘 적용되지 않았다.
이 논문은 일반 로봇 제어 모델을 만드는 데 핵심이 되는 두 요소로 (1) 태스크에 구애되지 않는 개방형(task-agnostic)학습 과 (2) 대용량(high-capacity) 아키텍처 을 제시한다.
task-agnostic: 특정 작업에 종속되지 않고 여러 종류의 작업을 포괄적으로 다룰 수 있는
제안된 모델 계열인 Robotics Transformer (이 논문에서는 RT-1 등)는 대규모 로봇 데이터를 흡수할 수 있는 스케일 특성을 보인다.
모델 크기나 데이터 양을 키웠을 때, 단순히 오버피팅되지 않고 성능이 꾸준히 향상되는 모델을 “scalable하다”고 말한다.
Introduction
두 가지 주요한 도전 과제는 올바른 데이터셋을 구성하는 것과 올바른 모델을 설계하는 데 있다.
데이터셋 구성:
- 로봇 데이터셋은 대개 특정 로봇에 맞춰져 있으며 수작업으로 수집되기 때문에 좋은 일반화 성능을 얻기 위한 대규모 데이터 셋을 얻기란 굉장히 어렵다.
- 그래서 우리는 13대의 로봇을 이용해 17개월 동안 수집한 데이터셋(약 13만 개의 에피소드와 700개 이상의 작업)을 활용하였다.
모델 설계:
- 효과적인 로봇 다중 작업 학습(multi-task learning)을 위해서는 높은 용량(capacity)을 가진 모델이 필요하다 그리고 로봇 제어기는 실시간으로 작동할 만큼 충분히 효율적이어야 한다.
- Transformer(Vaswani et al., 2017) 모델은 이 점에서 뛰어난 성능을 보인다.
- 앞서 말했듯이 로봇 제어는 실시간성을 요구하므로, Transformer처럼 거대한 모델은 연산 비용 때문에 곧바로 적용하기 어렵다.
- 우리는 RT-1(Robotics Transformer 1)이라 부르는 새로운 아키텍처를 제안한다.
- 이 모델은 카메라 이미지, 지시(instructions), 모터 명령 등과 같은 고차원 입력과 출력을 Transformer가 사용할 수 있는 압축된 토큰 표현(compact token representations)으로 인코딩함으로써, 실행 시 효율적인 추론을 가능하게 하여 실시간 제어(real-time control)가 가능하도록 한다.
양질의 데이터셋과 효율적인 모델 덕분에 RT-1이 기존 기법들에 비해 일반화 성능과 강건성(robustness)이 크게 향상될 수 있음을 보여줄 뿐만 아니라 700개 이상의 훈련 지시(instruction)를 97%의 성공률로 수행할 수 있음을 보여준다.
동작원리
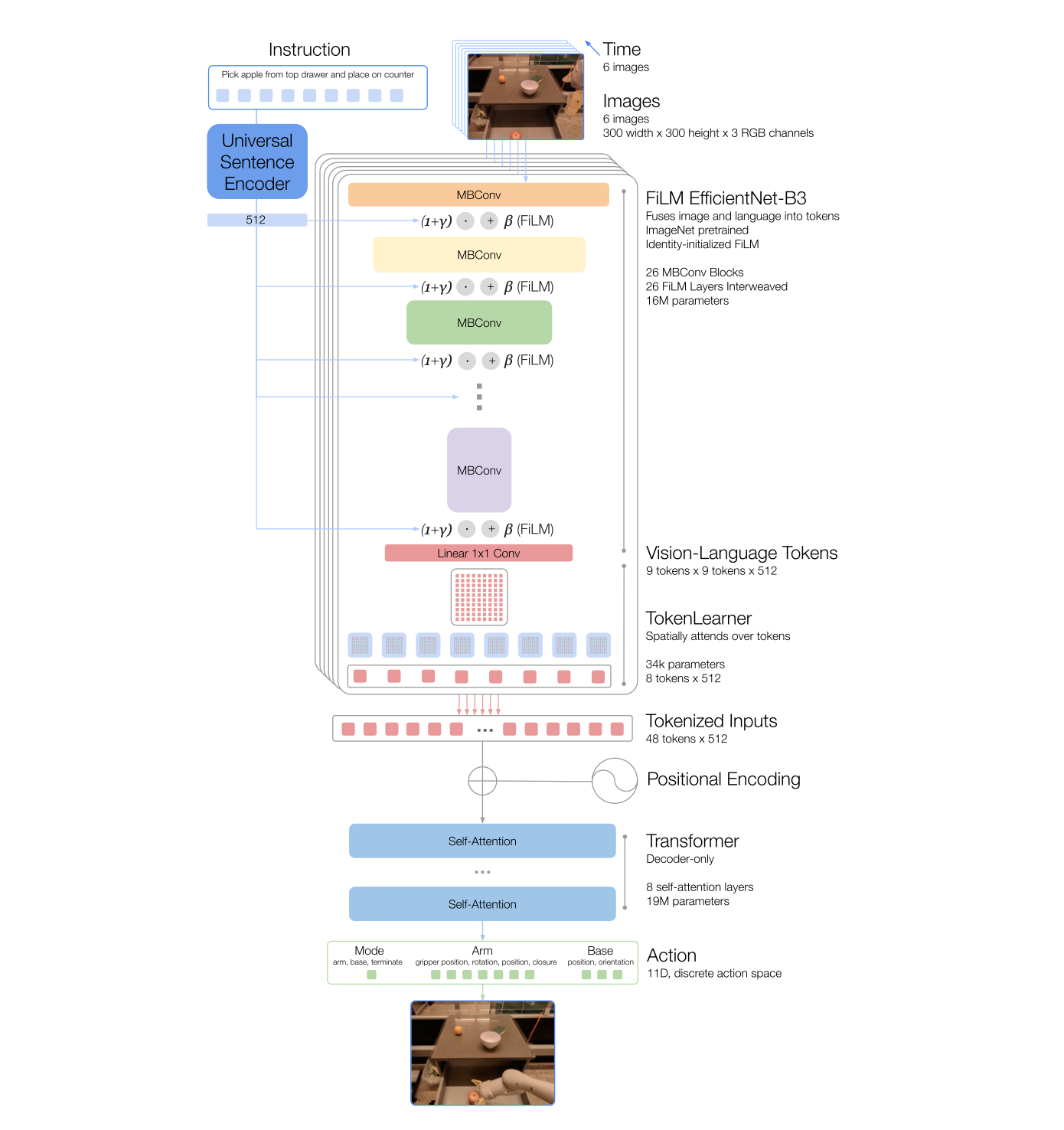
- 비전입력(Image Tokenization)
모델의 입력은 일련의 이미지(history of images)와 작업 설명(task description)을 입력으로 받아 토큰화된 행동(tokenized actions)을 출력한다.
예를들어 아래 바나나가 놓여져있는 이미지가 있다면 그에 연관된 명령문인 “pick up the banana” 가 함께 들어가게 된다.
RT-1은 ImageNet으로 사전학습된 EfficientNet-B3(Tan & Le, 2019) 모델을 통해 6장의 이미지 히스토리를 입력받아 토큰화한다.
이 모델은 해상도 300×300의 6장 이미지를 입력받고, 최종 합성곱(convolutional) 레이어에서 9×9×512 형태의 공간적 특성맵(spatial feature map)을 출력한다.
EfficientNet의 출력 특성맵을 평탄화(channel-wise)하여 81(9x9)개의 시각 토큰으로 변환하고(1개의 토큰은 512 차원 벡터),
- 언어 입력(Instruction Tokenization)
텍스트(명령어)는 Universal Sentence Encoder라는 모델을 거쳐 문장을 벡터화하게되는데 이때 각 문장에 대해 512차원 문장 임베딩 벡터로 변환한다.
- FiLM 모듈을 통한 Vision–Language 결합
FiLM(Feature-wise Linear Modulation) Layer라는 것을 통해 언어와 이미지를 결합하여 이미지 특징을 조절하는데 사용된다.
먼저 이미지의 어디를 중요하게 봐야 할지를 계산하기 위해 문장 임베딩을 통해 감마와 베타를 계산하고, 이를 피처맵(9x9x512)의 각각 채널에 적용한다.
각 채널별로 감마와 베타를 적용하면 문장에서 말하고자하는 명령어가 어는부분을 중요하게 봐야할지가 이미지에 반영되게 된다.
예를들어 “빨간 사과를 들어서 옮겨라”라고 한다면 이미지의 주변 배경은 흐릿하게 되고 빨간사과과 강조되는 것이다.
즉, FiLM은 채널별로 문맥에 따라 강조/약화시키는 역할을 합니다.이때는 아직 공간구조(9×9)가 살아 있으므로, 이미지 전체의 semantic weighting semantic을 수행한다.
weighting(시맨틱 가중화)는 RT-1 같은 모델에서 의미(semantic)정보를 반영해 어떤 특징(feature)을 더 중요하게, 어떤 것은 덜 중요하게 만드는 과정을 말한다.
이후 특성맵을 채널 기준으로 평탄화(channel-wise)하여 81(9x9)개의 시각 토큰으로 변환한다.(1개의 토큰은 512 차원 벡터)
그러면 총 81(9x9)개가 있음으로 (81x512)의 비전 토큰 시퀀스가 생성된다.
- TokenLearner
EfficientNet-B3을 통해 얻어진 비전 토큰 시퀀스 (81 x 512)는 여전히 토큰 수가 많아, Transformer가 모든 토큰을 처리하기에는 연산량이 매우 크다.
Token Learner 모듈을 통해 시각 정보를 압축(compaction)하고, 로봇 제어에 중요한 정보만 선별하여 전달한다.
이렇게 압ㅊ비전토큰 시퀀스를 트렌스포머에 넣어서 로봇의 액션값이 나오도록하는 것이 목표이다.(x축으로 얼마 y축으로 얼마 …)
로스값은 실제 그 이미지를 보고 움직이도록 나와야하는 좌표값이 된다.
예를들면 입력으로 빨간사과 이미지와 빨간사과를 집어서 옮겨라. 라는 문장이 같이 입력으로 들어간다면
트렌스포머의 출력으로는 (x=0.5, y=0.9, z=2.2)가 나오고 정답좌표가 따로 있어(x=0.6, y=0.9, z=2.3) 이것과 크로스엔트로피 계산을 하게된다.
그러나 학습된 행동 좌표(x, y, z)는 그 로봇의 팔 길이, workspace, calibration 기준에 종속되어 있다. 따라서 동일한 명령어라도 다른 로봇에서 동작 거리와 각도가 달라진다.
Kuka 로봇을 가지고 bin-picking(물체를 집는 동작)하는 데이터만으로 RT-1을 학습시키고, 이 학습된 모델을 EDR 로봇에 적용했을 때 얼마나 잘 작동하는지 실험한 결과 성능이 0%로 나타났다.
그러나 Kuka 로봇(산업용 로봇팔)을 사용하여 bin-picking(상자 속 물체 집기) 작업을 실제로 수행한 데이터가 있고 EDR 로봇(Everyday Robots, Kuka와 구조가 전혀 다른 서비스 로봇)을 사용하여bin-picking 작업을 수행한 데이터는 없었음.
- Kuka로봇을 가지고 만든 데이터에는 bin-picking 시연이 포함되어 있다. 그러나 EDR로봇을 가지고 만든 데이터에는 bin-picking 작업은 없고, 다른 다양한 작업(컵 집기, 문 닫기 등)만 있다.
- 위 데이터를 RT-1에 학습시 했더니 RT-1은 EDR 로봇이 bin-picking을 해본 적이 없는데도, Kuka의 bin-picking 경험 데이터를 참고하여 EDR의 팔 구조에 맞는 bin-picking 행동을 스스로 유추 할 수 있었다
즉, EDR 데이터(without bin-picking) + Kuka의 경험(with bin-picking)을 바탕으로 새로운 로봇(EDR)이 학습하지 못한 행동(bin-picking)을 수행하게 한 것이 핵심이다.
RT-1은 다른 로봇이 수행한 행동 데이터를 통해 새로운 기술을 익힐 수 있으며, 앞으로 더 많은 로봇들의 데이터를 결합하면 로봇의 능력을 한층 강화할 수 있을 것이다.
로봇의 능력을 더욱 향상시킬 수 있는 흥미로운 연구 방향을 제시한다.
Comment