
서론
Quantization 이란
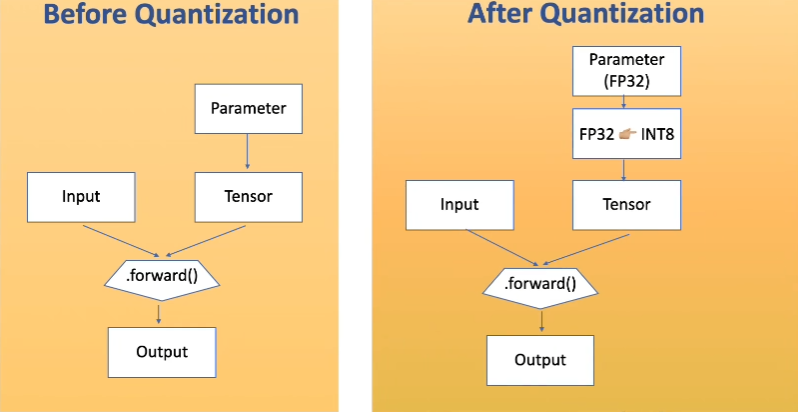
Neural Network 일반적으로 Parameter는 모델의 정확도를 높이기 위해 32bit floating point(FP32)로 펴현된다. 하지만 임베디드 장치와 같이 리소스가 제한된 환경에서 FP32로 표현하게 되면 Inference과정에서굉장히 많은 시간이 소요된다. 따라서 parameter가 표현하는 가중치를 실수형 변수에서 정수형 변수로 변환하는 과정을 뜻한다.
아래 그림과 같이 Quantization을 적용하면 일반적으로 많이 사용 하는 FP32 타입의 parameter를 INT8로 변환 후 Inference를 하게된다.
Quantization 적용해보기
위 그림의 왼쪽이 FP32일 때의 숫자이고 오른쪽은 formula를 통해 변환한 INT8에 해당하는 값이다. 실제로는 FP32과 INT8의 숫자는 딥러닝 모델의 weight에 해당한다고 보시면 된다.
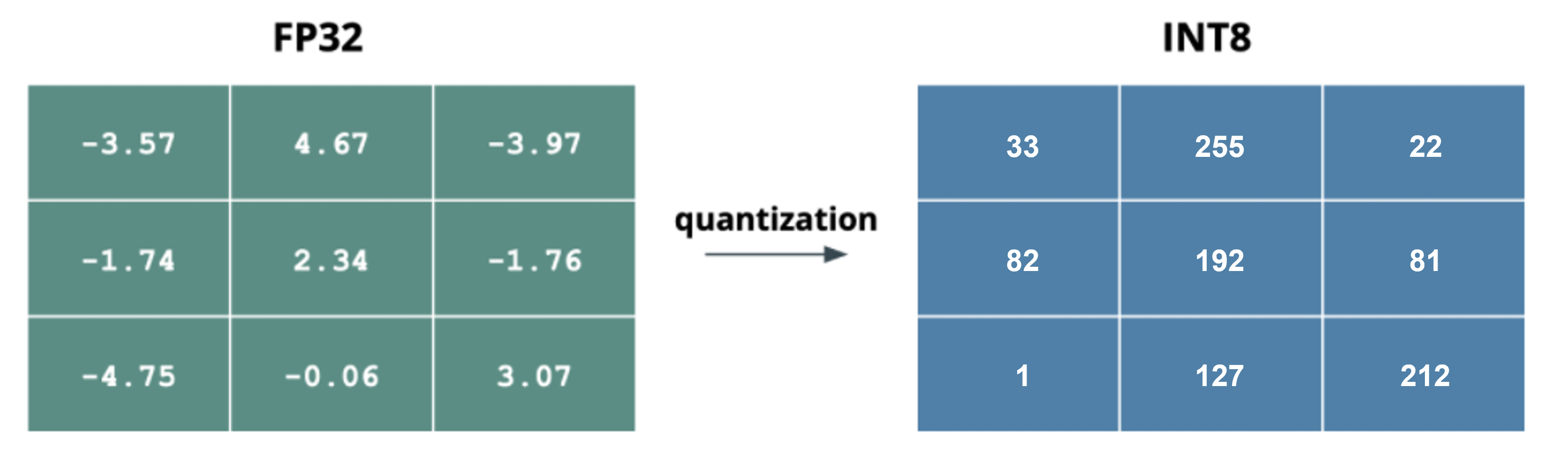
\(x\)는 FP32타입의 원래 Input값이고 \(x_q\)는 \(x\)값을 INT8로 Quantized된 값이다.
아래 수식은 Quantization할 때 사용되는 formula이다. \(round\)를 해주는 이유는 \(x_q\)가 INT8이기 때문이다.
\[x= s(x_q-d) \\ x_q = round(\frac{1}{s}x +d)\]
위 식에서 \(s\)
\(s(scale\;factor)\):
\(d(zero \;point):\)
Comment