
서론
이 장은 Normalization과 Regularization의 차이점에 대해서 설명한다.
그리고 Batch Normalization과 Layer Normalization에 대해서 설명한다.
목차
Normalization
데이터에 scale을 조정하는 작업으로 모델의 학습을 더 효율적으로 만드는 것이다.
다른 특성들과 비교하여 특성의 값의 범위가 너무 크거나 작으면, 그 특성이 모델의 학습에 지나치게 영향을 미치거나 거의 무시되는 결과를 초래할 수 있는데 이를 방지하기 위해 normalization을 사용하여 모든 특성의 값이 비슷한 범위에 들어가도록 조정한다. 흔히 사용되는 normalization기법은 Min-Max Scaling과 Standardization(Z-score normalization)이다.
Min-Max Scaling
Standardization(Z-score normalization)
Regularization
모델이 과적합(overfitting)되는 것을 방지하기 위해 predict function에 복잡도를 조정하는 작업이다.
따라서 Regularization은 복잡한 함수보다 더 간단한 피팅 함수에 보상(reward)을 합니다.
흔히 사용되는 Regularization기법은 L1(Lasso) regularization과 L2(Ridge) regularization이다.
L1 Regularization(Lasso)
Original Loss는 원래의 손실 함수를, λ는 regularization strength를, w는 모델의 가중치를 나타낸다. λ는 hyperparameter로, 이 값이 클수록 regularization의 효과가 강해지고 |w|는 가중치 벡터의 L1 norm(즉, 가중치의 절대값의 합)이다.
L1 regularization의 주요 특징은 일부 가중치를 0으로 만든다는 것이다. 즉, 불필요한 특성의 가중치를 0으로 만들어 모델이 해당 특성을 무시하도록 한다.
Loss = Original Loss + λ*|w|L2 Regularization(Ridge)
Original Loss는 원래의 손실 함수를, λ는 regularization strength를, w는 모델의 가중치를 나타낸다. λ는 hyperparameter로, 이 값이 클수록 regularization의 효과가 강해지는데 ||w||²는 가중치 벡터의 L2 norm (즉, 가중치의 제곱의 합)이다.
L2 regularization의 주요 특징은 모든 가중치를 작게 만든다는 것이다. 이렇게 하면 모델이 학습 데이터의 노이즈에 덜 민감해지므로 과적합을 방지하는데 도움이 된다. 그러나 L2 regularization은 L1 regularization과 달리 가중치를 완전히 0으로 만들지는 않는다.
Loss = Original Loss + λ*||w||²Batch Normalization과 Layer Normalization
Batch Normalization과 Layer Normalization은 평균과 분산을 계산하는 축(axis)에 따라 차이가 있다.
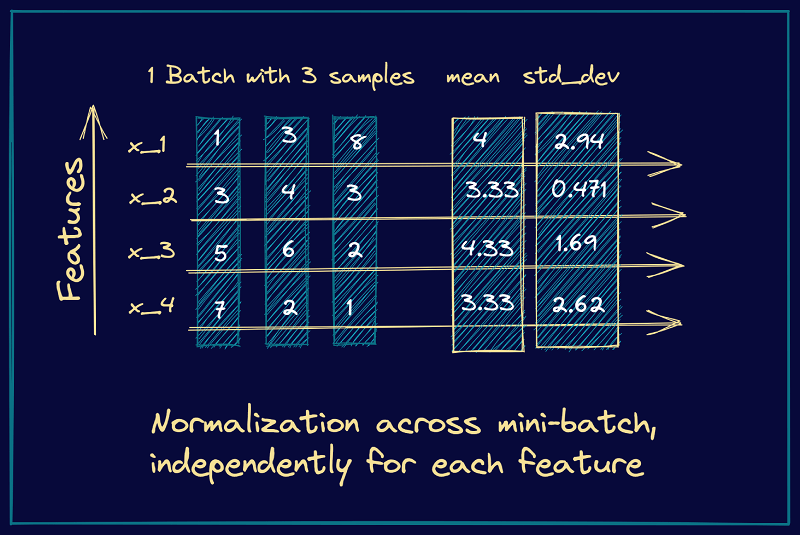
아래 그림을 봐보면 1 Batch with 3 samples 라고 적혀있다.
즉 각각의 x_1, x_2, x_3, x_4은 데이터의 특징이라고 보면된다.
3개의 열은 a, b, c라는 3개의 데이터다.
Batch Normalization은 “각 feature의 평균과 분산”을 구해서 batch에 있는 “각 feature 를 정규화”한다. 따라서 가로로 이뤄진 [1, 3, 8], [3, 4, 3], [5, 6, 2], [7, 2, 1] Batch에 있는 x_1, x_2, x_3, x_4의 특징에 대해서 각각 평균과 분산을 구하는 것이다.
반면 Layer Normalization은 세로로 평균과 분산을 구한다고 보면된다. 즉, “각 input의 데이터들에 대한 평균과 분산”을 구해서 batch에 있는 “각 input을 정규화” 한다고 생각하면 된다.
[reference]
https://yonghyuc.wordpress.com/2020/03/04/batch-norm-vs-layer-norm/
https://gaussian37.github.io/dl-concept-various_normalization/
Comment