
서론
이 장은 DDP를 사용하는 방법과 개념에 대해서 설명한다. 사용되는 GPU의 갯수는 4개이며 각 GPU 모델은 RTX4090을 가지고 실험한다.
또한 간단하게 코드를 구현하여 Single GPU와 Multi GPU에서의 성능차이를 실험한다.
목차
용어 정리
world_size: 총 GPUs개수
Node: 사용하는 컴퓨터 수
local_rank: 각 GPU의 고유 번호(device와 비슷한 개념)
Rank : 각 노드에서의 프로세스 우선순위
만약 한대의 컴퓨터에서 4개의 GPU를 사용한다고 가정하면 아래와 같이 할당될 것이다.
local_rank: 0 RANK: 0 world_size: 4
local_rank: 1 RANK: 1 world_size: 4
local_rank: 2 RANK: 2 world_size: 4
local_rank: 3 RANK: 3 world_size: 4
예를들어 모델을 각자 4 개의 GPU를 가진 두 개의 서버 또는 node에서 training시킨다고 가정한다. 그러면 world size는 4*2 =8이다. 프로세스들에 대한 rank는 [0, 1, 2, 3, 4, 5, 6, 7]이다. 각 node에서의 local rank는 각각 [0, 1, 2, 3]이다.
torch.nn.Dataparallel
설명을 위해 GPU 4개를 순서대로 GPU0, GPU1, GPU2, GPU3 라고 부르겠다. 각 GPU 뒤의 숫자는 GPU 번호이다. 그리고 기준이 되는 GPU0(GPU를 0번)이라하겠다.
Forward pass
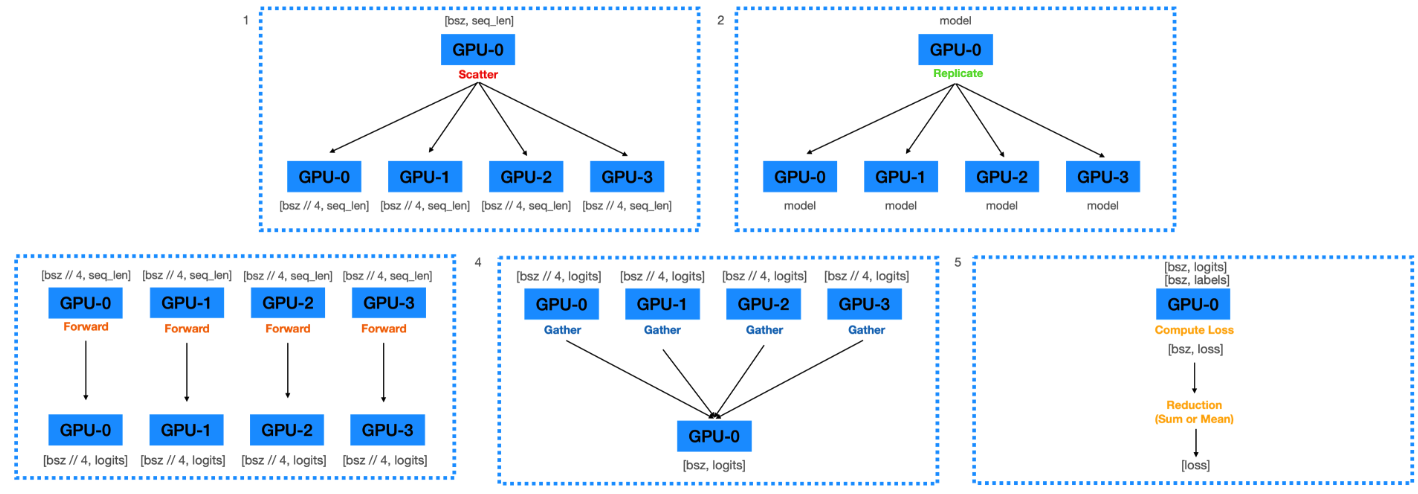
- (Scatter) GPU0에 올라온 batch_size를 GPU갯수인 4개로 나눈다. 그리고 GPU1, GPU2, GPU3에 전달한다.
- 예를들어 batch_size가 100이라하자. 그러면 GPU0에 100만큼의 데이터가 올라오고 GPU0, GPU1, GPU2, GPU3에 각 25씩 전달하게 된다.
inputs = nn.parallel.scatter(inputs, device_ids)- (Replicate) 여러개의 GPU를 사용해 모델을 학습하려면 모델을 각 GPU에 복사해줘야 한다.
- GPU0에 올라와 있는 model parameter를 GPU0, GPU1, GPU2, GPU3에 전달한다.
replicas = nn.parallel.replicate(model, device_ids)- (Forward) 각 Device(GPU)내에서 forward연산을 수행하여 모델의 출력을 계산한다.
logit = nn.parallel.parallel_apply(replicas, inputs)- (Gather) 각 Device에서 연산된 출력값을 하나의 Device(GPU0)로 모은다.
logit = nn.parallel.gather(outputs, output_device)- 하나의 Device(GPU0)에서 모아진 출력과 Loss Function을 통해 Loss값을 계산한다.
Backward pass
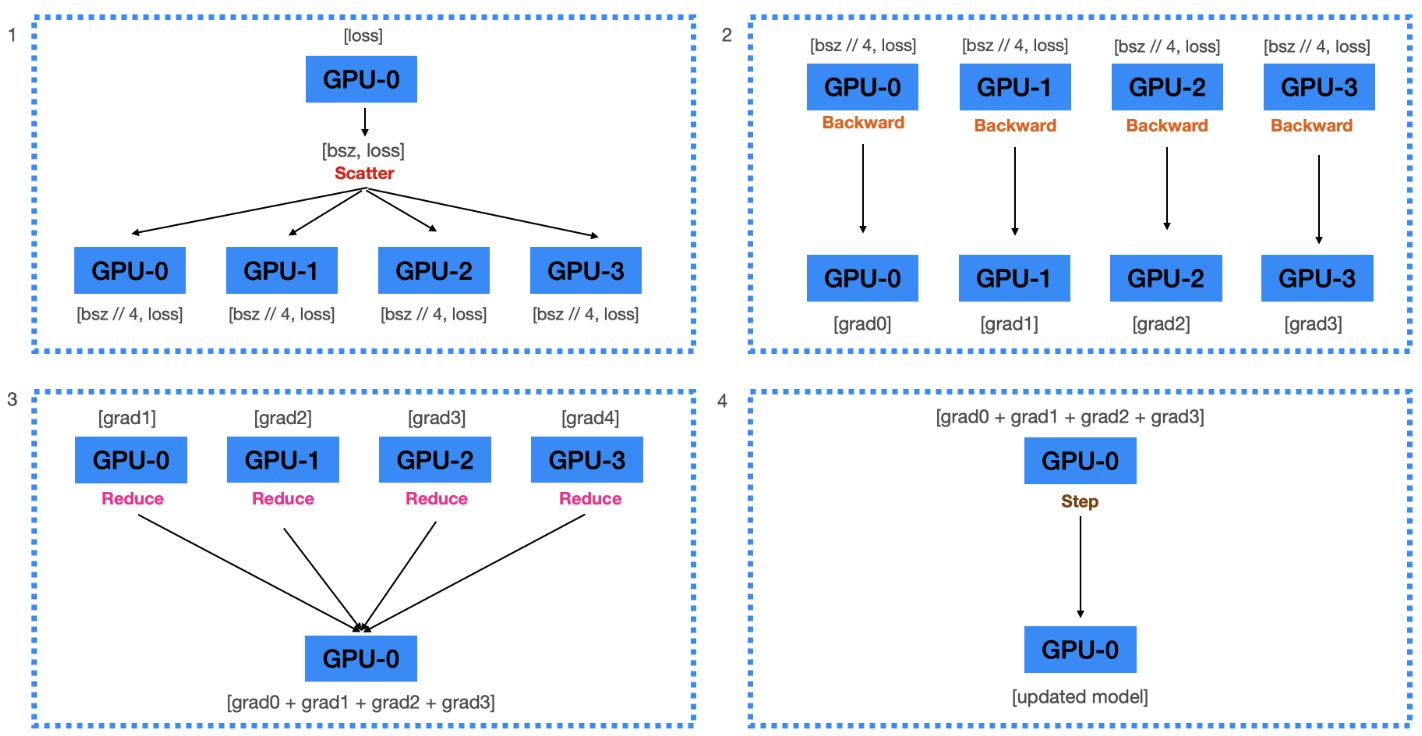
- (Scatter) 하나의 Device(GPU0)에서 계산된 loss를 GPU갯수인 4개로 나눈다. 그리고 GPU1, GPU2, GPU3에 전달한다.
- (Backward) 각 Device는 전달 받은 loss를 사용하여 독립적으로 gradient를 계산한다.
- (Reduce) 계산된 모든 gradient를 GPU0에서 모두 더해준다.
- (Update) 모아진 gradient를 이용해 GPU0에 있는 모델에 가중치를 업데이트한다.
data_loader = DataLoader(datasets, batch_size=128,
num_workers=4)
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3],
output_device=0)문제점
Forward의 4, 5번의 과정과 같이 출력을 하나로 모으고 loss값을 계산함으로 다른 Device(GPU1, GPU2, GPU3) 대비 GPU0의 메모리 사용량이 더 높다.
torch.nn.parallel.DistributedDataParallel (DDP)
DDP는 기존 DataParallel의 문제점을 계선한다.
Single Node(한 대의 컴퓨터)에서 Multi-GPU를 사용할 수도 있고 Multi Node(여러대의 컴퓨터)에서도 Multi-GPU를 사용할 수 있다.
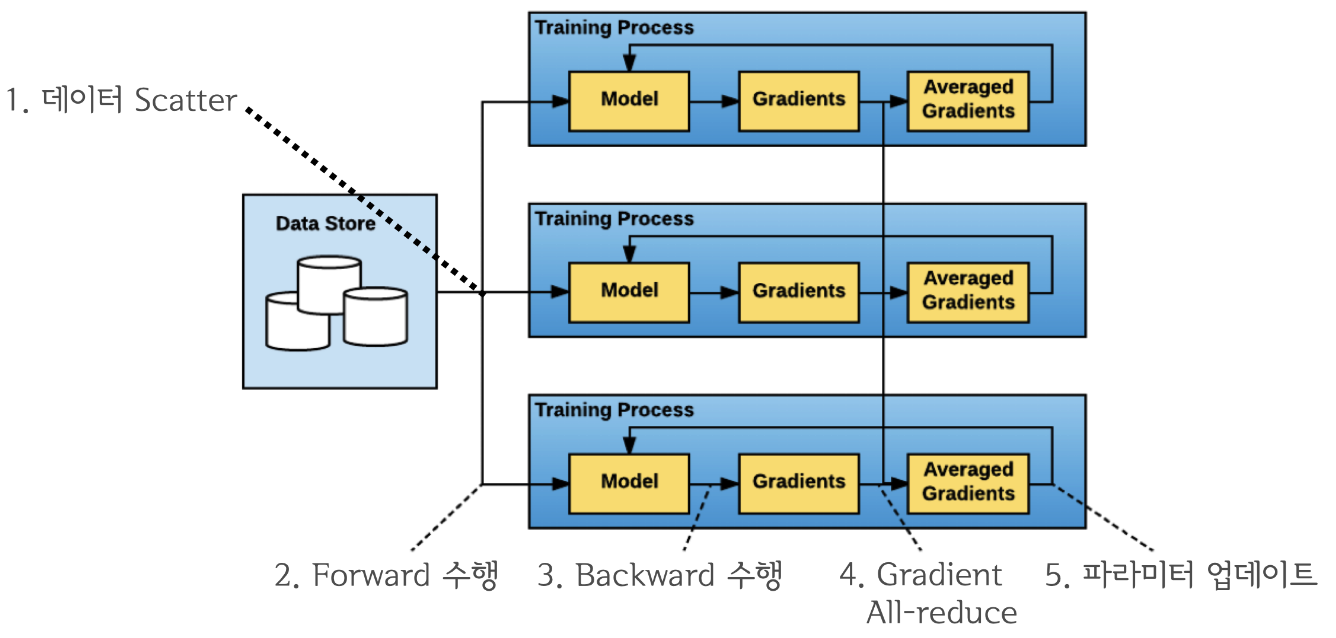
- 데이터 Scatter
- 만약 batch_size가 100이라면 DP처럼 GPU갯수 만큼 나눠지지 않고 GPU0, GPU1, GPU2, GPU3처럼 각각 100씩 할당받는다 따라서 global_batch_size는 400이된다.
- Forward 수행
- 각 Device(GPU)내에서 forward연산을 수행하여 모델의 출력을 계산한다.
- Backward 수행
- 각 Device에서 연산된 출력값을 가지고 Loss Function을 통해 Loss값을 계산하여 gradient를 구한다.
- Gradient All-Reduce
- gradient를 효율적인방식(Ring All-Reduce 등)을 통해 각 Device(GPU0, GPU1, GPU2, GPU3)들과 동기화한다.
5. Weight Update

코드 구현
Dependency
import os
import torch
import torchvision
import torch.distributed as dist
from torchvision.models import resnet50
import torchvision.transforms as transforms
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler멀티프로세스 초기화
world_size, local_rank를 초기화할 때 넣어줘야 한다.
# DDP
distributed = False
if 'WORLD_SIZE' in os.environ:
distributed = int(os.environ['WORLD_SIZE']) > 1
# Total gpu number
world_size = int(os.getenv('WORLD_SIZE', 1))
# 1. initialize process group
if distributed :
# local_rank 값 구하기
local_rank = int(os.getenv('LOCAL_RANK', -1))
torch.distributed.init_process_group(backend='nccl',
init_method='env://',
rank=local_rank,
world_size=world_size)
torch.cuda.set_device(local_rank)
else :
world_size = 1
local_rank = 0
print(f"DDP:{distributed}, local_rank:{local_rank} GPU:{torch.cuda.current_device()}, Total_device:{world_size}")실행결과
각각의 device로 이뤄진 프로세스들이 실행되는 모습을 볼 수 있다.

DataLoader(Train_Sampler) 구성
데이터셋은 torchvision에서 지원해주는 cifar10을 사용하겠다. 그리고 만든 dataset을 DistributedSampler에 넣어준다.
# Create train_sampler
if distributed :
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=world_size, rank=local_rank, shuffle=True)
else :
print("train Sampler not initialized")
train_sampler = None
# Create Train_Loader
workers = 4
batch_size = 100
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=(train_sampler is None),
drop_last=True,
pin_memory=True,
num_workers=workers,
sampler=train_sampler
)모델 정의
model = resnet50(weights="IMAGENET1K_V2")
model.to(local_rank)
# DDP
if distributed :
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = DDP(model, device_ids=[local_rank])Train
num_epochs = 5
for epoch in range(num_epochs):
model.train()
# Train_sampler
train_sampler.set_epoch(epoch)
for step, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(local_rank), labels.to(local_rank)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
#print(f"Before All Reduce-GPU:{local_rank}, loss:{loss}")
if dist.is_available() and dist.is_initialized():
loss = loss.data.clone()
dist.all_reduce(loss.div_(dist.get_world_size()))
#print(f"After All Reduce-GPU:{local_rank}, loss:{loss}")
if local_rank==0 and step % 50 == 0:
print(f"Step [{step}/{len(train_loader)}]\t Loss: {loss.item()}")Run
멀티 프로세스를 사용하기 때문에 다음과 같은 방법으로 코드를 실행시켜야 한다.
--nproc_per_node: 훈련시킬 GPU의 갯수를 입력하면 된다.
torch_ddp.py: 본인이 실행할 파이썬 파일이다.
python3 -m torch.distributed.run --nproc_per_node=4 torch_ddp.py실행시켜보면 Before All Reduce 부분을 보면 각 GPU들의 loss값이 다르다는 것을 볼 수 있다.
그러나 All_Reduce를 통해 동기화되어 loss값이 같은 값을 갖는 것을 볼 수 있다.

GPU-Utils 확인
확인해보면 4개의 GPU를 모두 잘 사용하고 있다.
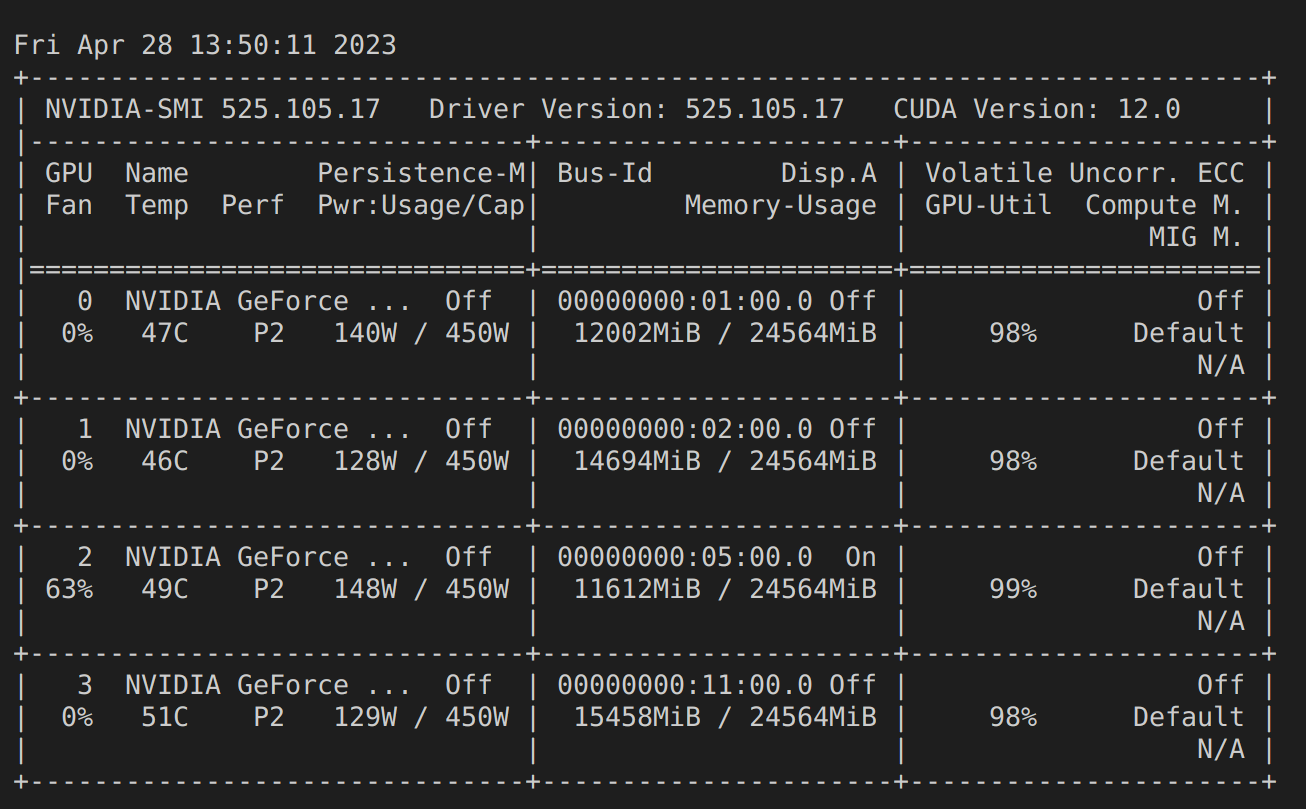
DDP Evaluation
GPU 4개를 가지고 동시에 학습시켰을때 옳바르게 학습되는지 Test loader를 따로 구현해 정확도를 봐보면 잘 학습되는 것을 볼 수 있다.
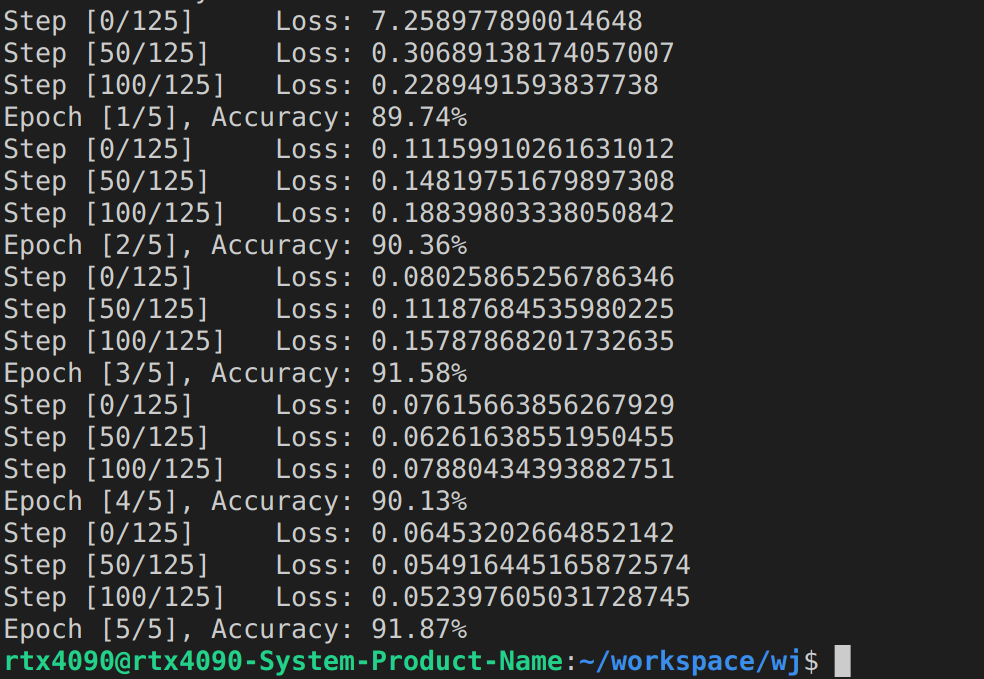
Single GPU Evaluation
이번에는 GPU 1개만을 가지고 훈련을 시켜보았다.
python3 torch_ddp.py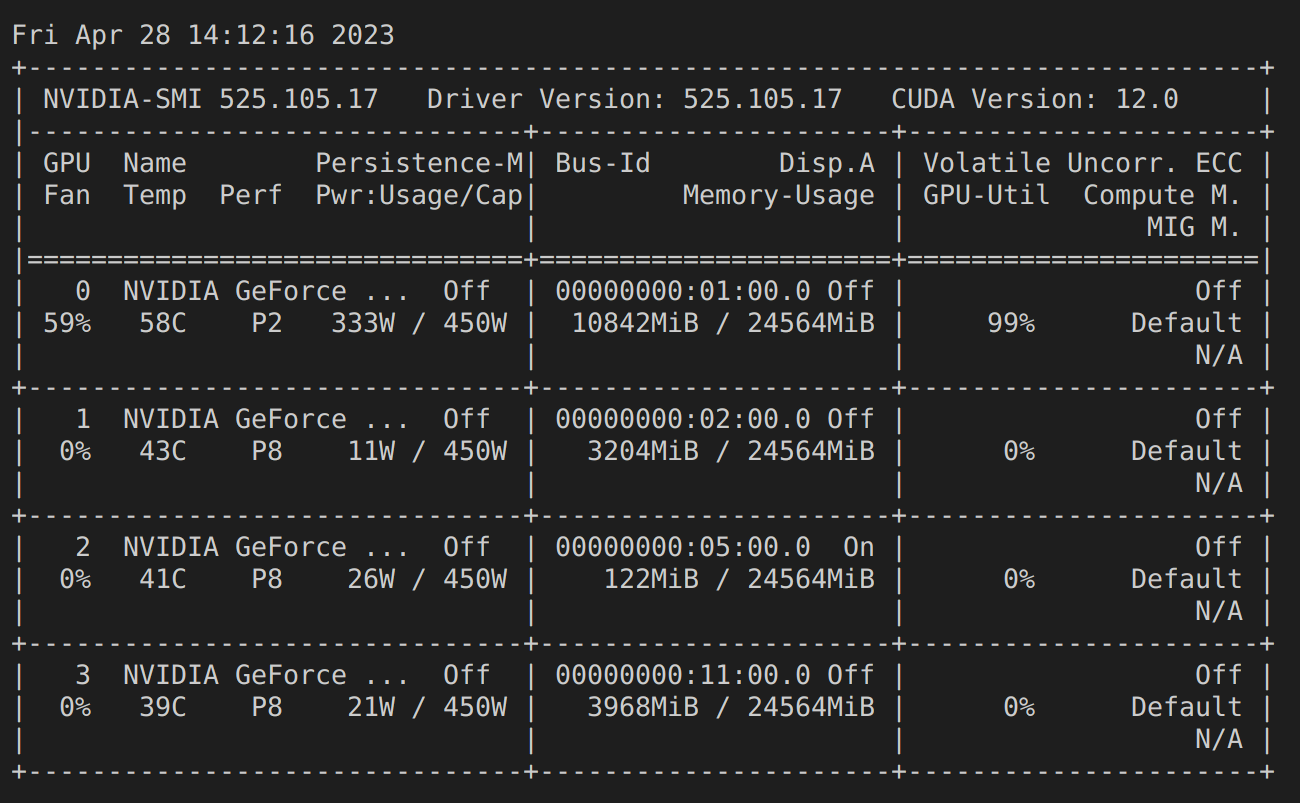
그리고 GPU 1개를 가지고 학습시켜보았는데 아래와 같은 결과를 보였다.
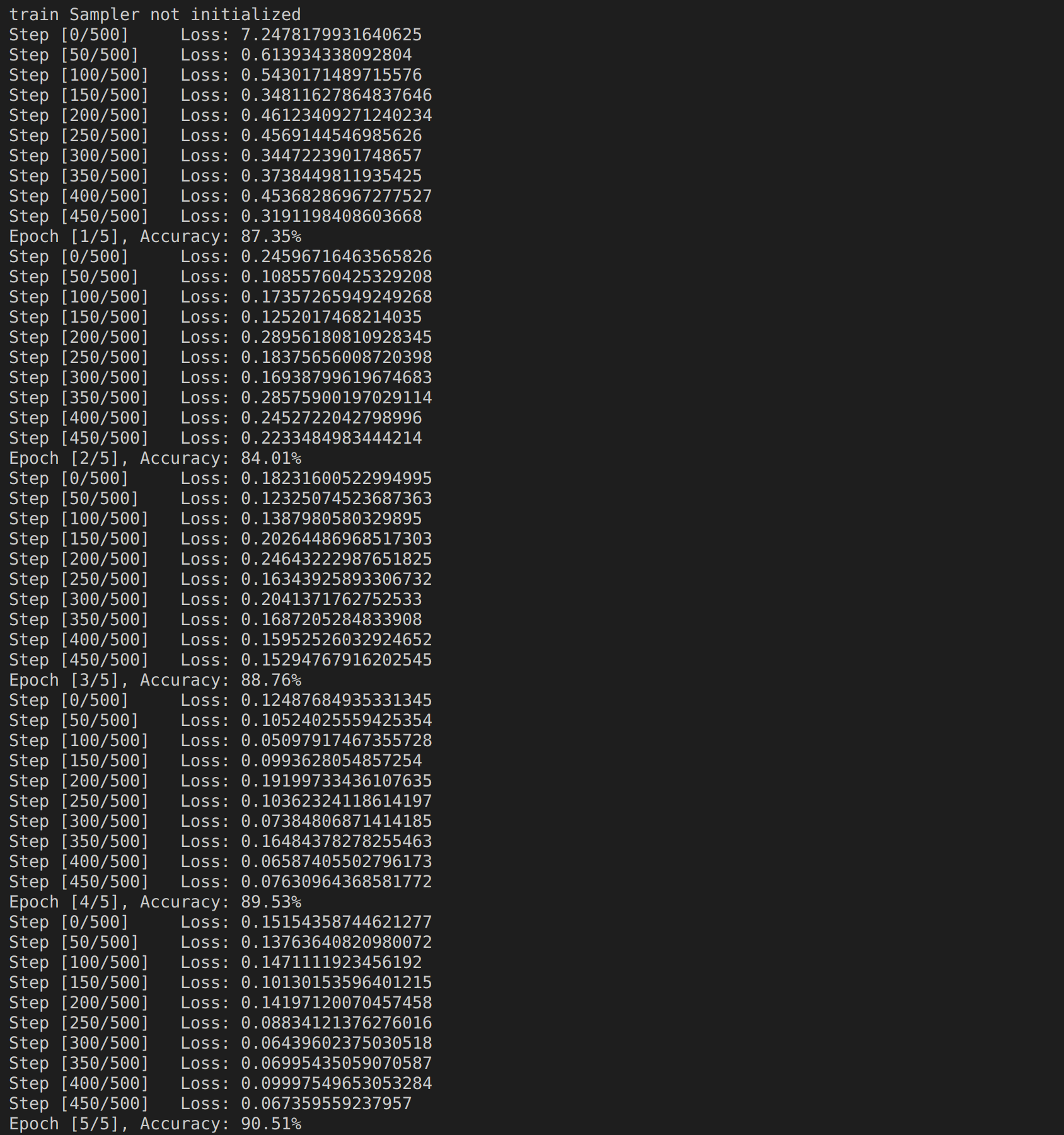
전체 코드
원래는 SimCLR 모델을 DDP로 학습하려 했고 SimCLR에는 DDP가 P2P방식으로 구현되어 있었는데 4090에서는 P2P통신을 지원하지 않아 다른 방식의 DDP를 사용해야 했다.
위에서 설명한 코드와 SimCLR에 멀티 프로세싱을 통한 nccl 방식의 ddp구현도 같이 공유한다.
위에 사용된 간단한 코드는 ResNet50_DDP라는 폴더안에 있다.
https://github.com/woorej/Pytorch_DDP
결론
비록 5번의 Epoch를 돌려본 결과지만 GPU 4개를 사용해 학습시킨 모델이 GPU 1개만 사용해 학습시킨 모델보다 성능이 더 잘 나오는 것을 볼 수 있다. 이는 모델에서 학습시키는 batch_size의 크기 때문이라 본다. 4개의 GPU에서는 batch_size를 4배만큼 가져간다. 즉, batch_size가 100이라면 400의 batch를 바라보고 학습시킨다는 의미다.
ResNet50의 경우 batch_size의 영향을 크게 받지 않는 것 같지만 Contrastive Learning과 같은 SimCLR 모델에서는 batch_size가 클 수록 모델의 성능이 더 잘 나오기 때문에 DDP의 학습이 중요하다고 볼 수 있다.
[reference]
https://seunghan96.github.io/python/dlf/DPP/
https://medium.com/daangn/pytorch-multi-gpu-학습-제대로-하기-27270617936b
Comment