
서론
이 장은 Manifold의 개념에 대해서 설명한다.
목차
- Manifold
- Manifold Hypothesis
- 1. Data compression
- 2. Data visualization
- 3. Curse of dimensionality 개선
- 4. Discovering most important features
Manifold
공간상에 데이터들을 표현하면 각 데이터들은 점의 형태로 찍혀져 있을 것이다. Manifold는 이러한 Sample들을 잘 아우르는 고차원 공간안에 있는 어떤 하위 공간(subspace)에 놓여있다고 하자.
의미가 추상적이라 잘 와 닿지 않는데 나는 이를 고차원으로 구성된 sample들을 잘 표현하도록 하는 저차원으로 embedding된 subspace(공간)로 이해했다.
Neural Network는 일반적으로 고차원 → 저차원으로 압축하는 Encoder 역할의 네트워크 부분이 발생하게 된다. 이 과정에서 feature extraction을 수행하게 된다. 이렇게 하는 이유는 고차원을 축소시켜서 저차원으로 데이터를 보게되면 유의미한 데이터만 남게되어 분류가 쉬워지기 때문이다.
따라서 우리는 고차원 공간에서의 데이터들을 데이터의 손실 없이 잘 표현해주는 저차원 공간을 찾아야 한다.
Manifold Hypothesis
“고차원의 데이터가 있을 때 이 데이터(sample)를 잘 아우르는(표현하는) subspace가 존재할 것이다” 가 바로 mainfold의 가정이다. 이렇게 찾은 manifold를 가지고 데이터의 차원을 축소시킬 수도 있고 이로인해 데이터를 더 잘 표현할 수 있게 된다.
Manifold Learning
앞에 설명한 Manifold Hypothesis를 기반으로 manifold를 잘 찾는 것을 manifold learning이라 할 수 있다.
쉽게 말해 원래 데이터의 특성을 잘 유지하면서 차원을 축소해야하는 작업이다.
차원을 축소한 결과는 크게 4가지 용도로 사용된다.
1. Data compression
encoder와 같은 데이터 압축이다.
2. Data visualization
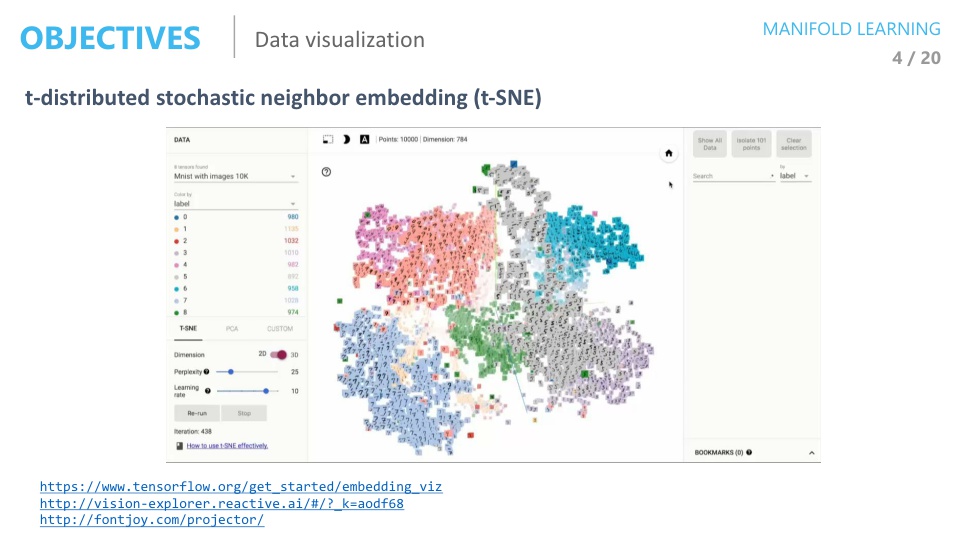
t-SNE 방법으로 가장 많이 사용하는 Visualization 방법 중 하나다.
3. Curse of dimensionality 개선
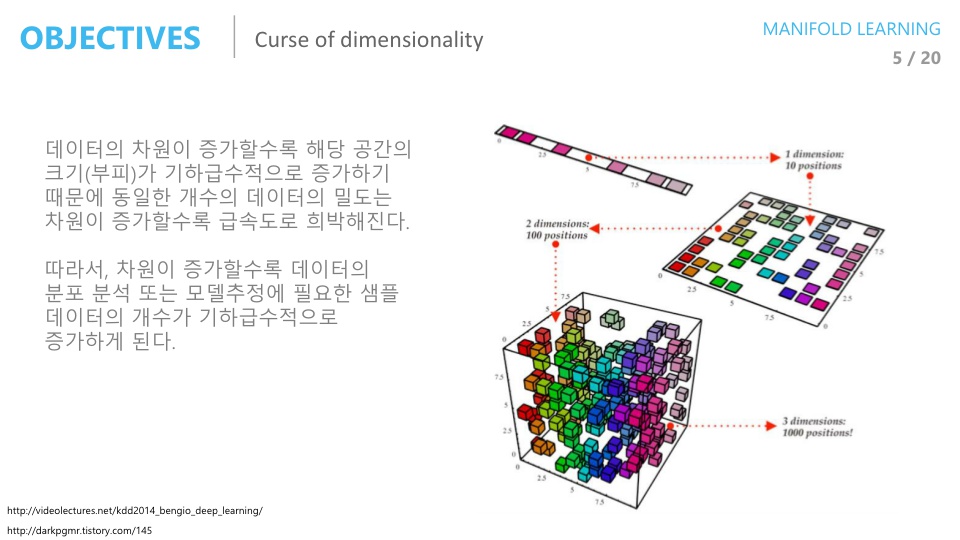
아래 그림은 차원의 저주에 대한 설명인데, 차원의 저주는 차원이 높아질수록 공간이 커지는 반면에 데이터의 수는 고정되어 있어 데이터의 밀도가 희박해 지는 문제를 뜻한다.
예를 들어 1차원 총 공간이 10만큼이고 데이터가 8개가 있다면 전체 공간에 80%만큼 데이터가 채워져 있었지만 2차원으로 늘어나면 전체 공간 100에서 8이므로 8% 공간만 차지하게 되고 3차원, 4차원으로 늘어날수록 그 비율은 더 줄어 들게 되는 문제이다.
이렇게 데이터가 적은데 비하여 공간이 커질 수록 분석 자체가 어려워 성능이 나빠진다.
위와 같이 고차원의 밀도는 낮지만 이들의 집합을 포함하는 저차원의 매니폴드를 찾으면 이 매니폴드 상에서는 데이터의 밀도가 높게 나타난다.

이미지는 굉장히 높은 차원의 데이터이다. 예를 들어, 100x100 픽셀의 흑백 이미지는 10,000차원의 데이터라고 볼 수 있다.
이러한 고차원의 이미지 데이터에서 균등 분포로 데이터를 샘플링 한다면 의미 있는 데이터를 얻을 수 없을 것이다.
그 의미는 이미지 데이터 자체가 균등하게 공간상에 존재하는 것이 아니라 이미지 유형에 따라서 공간에 밀집되어 있다는 것을 뜻한다.
균등 분포를 통해서 데이터를 샘플링 하면 노이즈 같은 이미지가 생기지만 어떤 공간에는 얼굴 이미지가, 어떤 공간에는 글씨가 있을 수 있다.
만약 얼굴 이미지를 잘 아우르는 매니폴드를 알고있고 얼굴 이미지 간의 관계성 및 확률 분포를 찾을 수가 있고 그 확률 분포에서 샘플링을 한다면 의미 있는 얼굴 이미지를 생성할 수 있다.

가장 많이 사용되는 manifold learning의 역할 중 마지막으로 언급하려는 것은 가장 중요한 feature를 찾는 것이다.
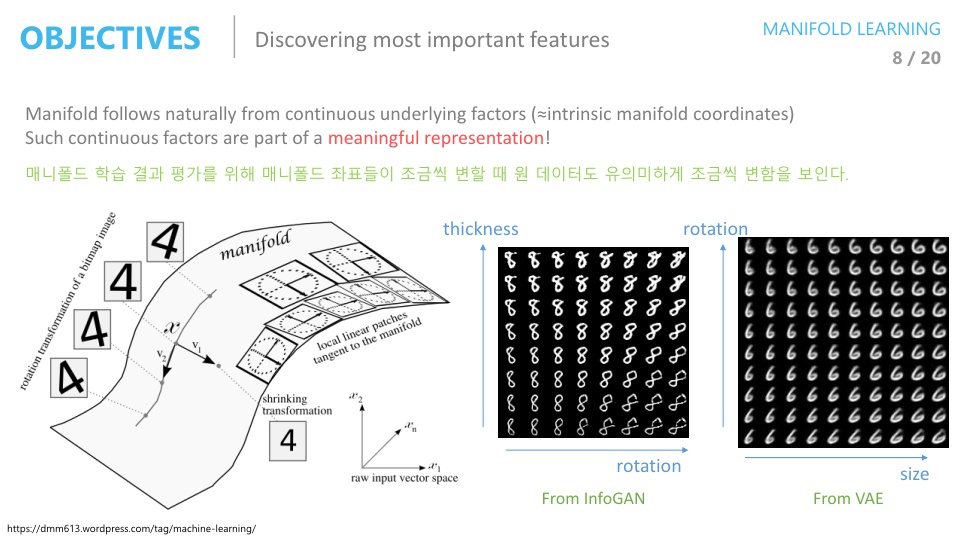
아래 슬라이드의 MNIST 이미지는 28 x 28 크기로 784 차원을 가지는 데 여기서 데이터를 잘 아우르는 manifold를 찾는다면 그 manifold에는 이미지의 회전, 변형, 두께등의 유의미한 feature가 있을 수 있다.
이러한 feature들은 자동으로 찾아지는데 그 이유는 Unsupervised learning으로 학습되어 지기 때문이다.
학습 방식이 비지도학습인것이지 비지도학습에서만 사용되는 것은 아니며 이러한 개념을 착안하여 manifold의 개념이 지도학습에서도 이용되어 진다.
Deep Neural Networks은 고차원 입력 데이터에서 유용한 특징을 추출하는 역할을 하는데 이런 과정에서, 매니폴드 학습과 비슷한 원리가 사용될 수 있다. 신경망의 각 계층은 입력 데이터의 점점 더 낮은 차원의 표현(representation)을 학습하는데, 이는 본질적으로 매니폴드를 학습하는 것과 유사하다.
예를 들어, 이미지 인식에서 심층 신경망은 처음에는 저차원 특징(예: 선, 색상 등)을 학습하고, 이런 특징을 결합하여 점점 더 복잡한 패턴(예: 얼굴, 객체 등)을 학습하는 방식으로 작동하기 때문이다.
4. Discovering most important features
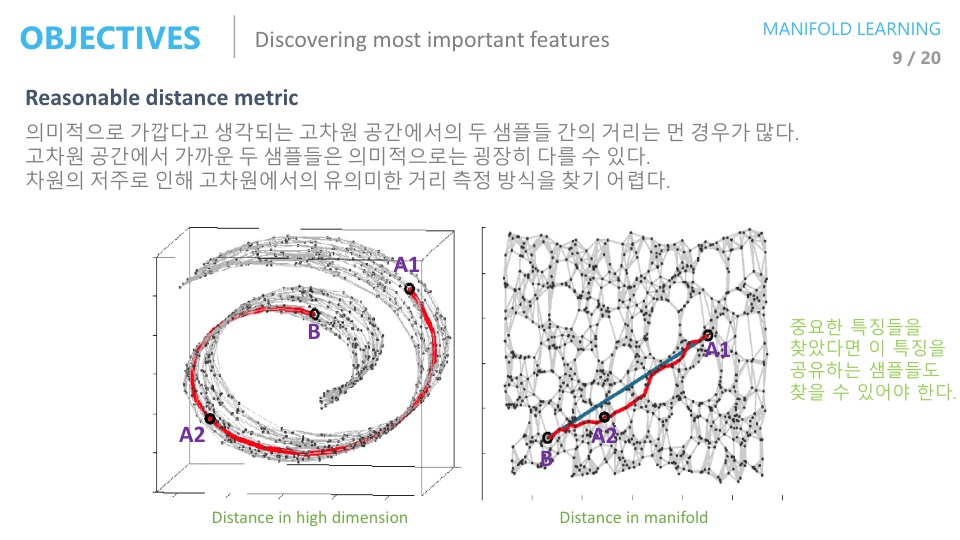
또한 manifold를 잘 찾으면 의미적으로 가까운 데이터들을 찾을 수 있다.
아래 그림에서 왼쪽의 고차원 데이터에서는 유클리디안 거리로 A1은 B와 가깝지만 manifold상에서의 거리를 오른쪽에서 보면 A1은 A2와 가깝다.
아래 그림을 보면 manifold상에서가 아닌 고차원 상에서의 유클리디안의 거리가 가까우니 image간의 관계가 높을 것이라는 기대로 이미지를 sampling해보면 가운데에 있는 이미지는 팔이 여러개인 의미없는 데이터임을 알 수 있다.
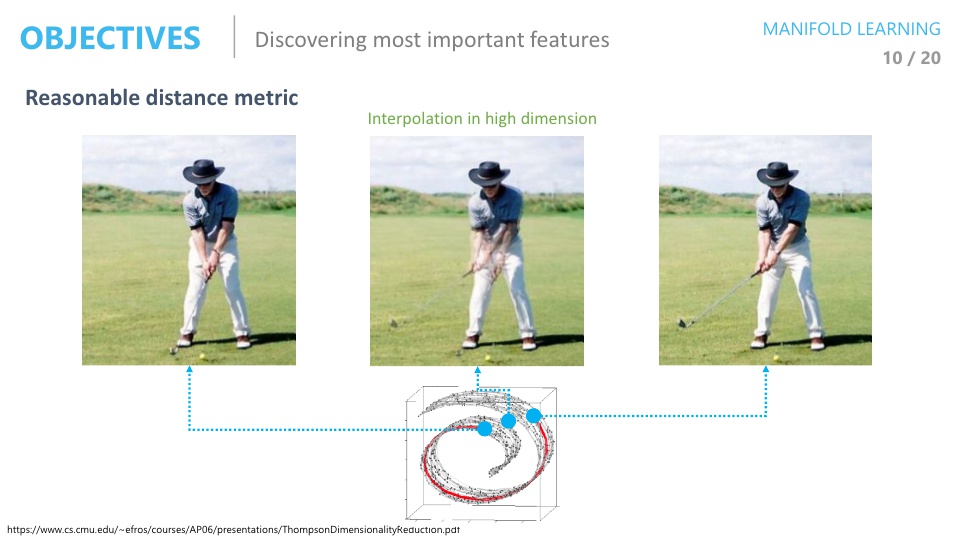
하지만 고차원 공간에서가 아니라 manifold상에서 가운데에 위치할 이미지를 찾는다면 기대하는 의미가 있는 이미지가 나올 수도 있다.
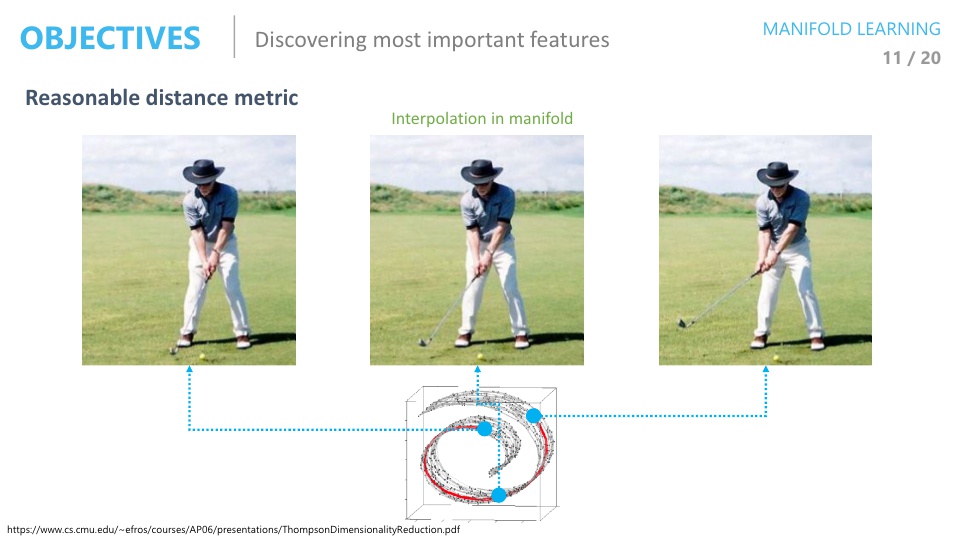
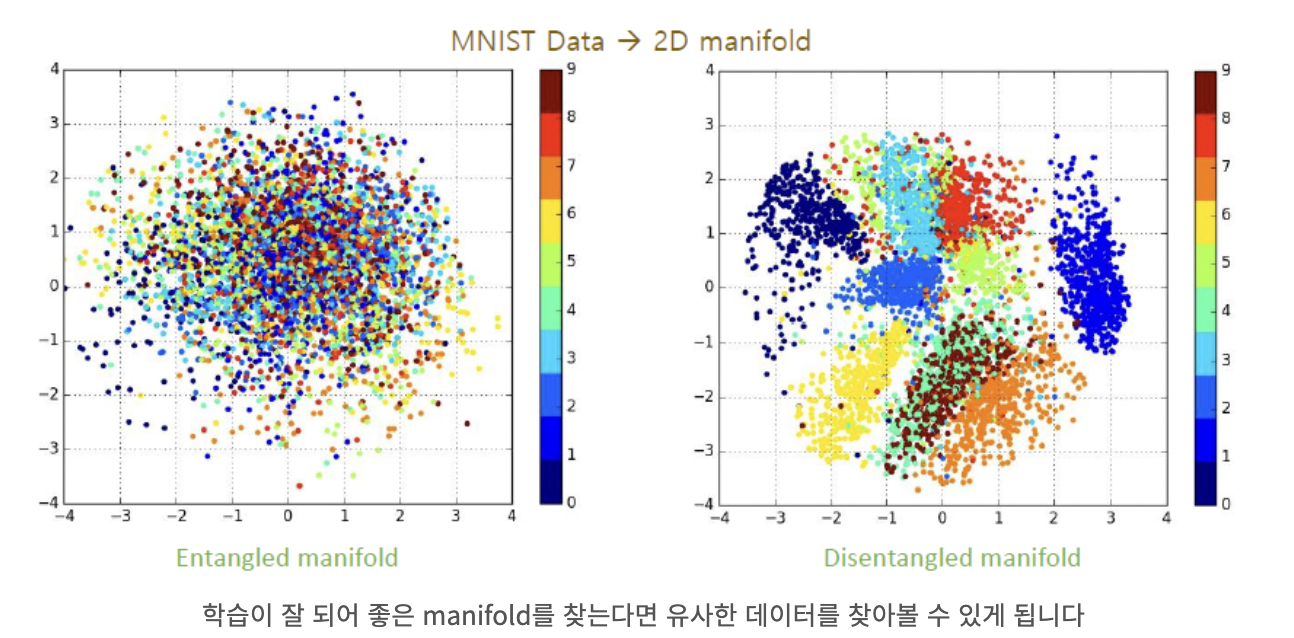
잘 학습된 manifold에서는 오른쪽 이미지와 같이 Disentangled형태를 가지게 된다.
위 그래프는 0 ~ 9 까지의 숫자 이미지를 2차원으로 차원 축소한 다음에 그래프상에 표시한 것인데 오른쪽 같이 숫자별로 군집되어 있어야 유의미한 feature로 manifold가 만들어 졌다고 할 수 있다.
[reference]
https://deepinsight.tistory.com/124
https://greatjoy.tistory.com/51
https://velog.io/@xuio/TIL-Data-Manifold-학습이란
https://kh-mo.github.io/notation/2019/03/10/manifold_learning/
Comment