
서론
이 장은 MLE에 대해서 설명한다. 확률의 의미와 기본 개념들에 대해서 같이 알아봐보자.
목차
- Probability
- PDF(Probability Density Function)
- CDF(Cumulative Distribution Function)
- 모수 추정
- Likelihood
- Maximum likelihood
- Log likelihood function
Probability
확률이란 주어진 확률분포가 있을 때, 관측값 혹은 관측 구간이 분포 안에서 얼마의 확률로 존재하는 가를 나타내는 값이다. 이때 확률 분포를 고정하고 그 때의 관측 X에 대한 확률을 구하는 것이다.
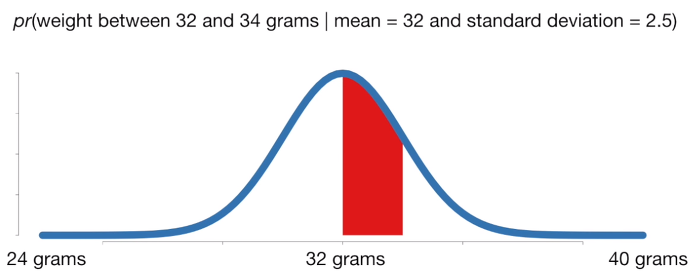
파란 확률 분포는 쥐들의 몸무게 분포로써 평균 32 표준편차 2.5를 갖는 정규분포이다. 해당 분포를 가정하고(고정하고) 쥐의 무게가 32~34 사이로 관측될 확률은 아래 그림의 빨강 영역과 같을 것이다.
- 확률은 '어떤 고정된 분포'에서 이것이 관측될 확률(Area under distribution)이다.
Likelihood에 대해서 들어가기 전에 PDF, CDF 개념에 대해서 짚고 넘어가겠다
PDF(Probability Density Function)
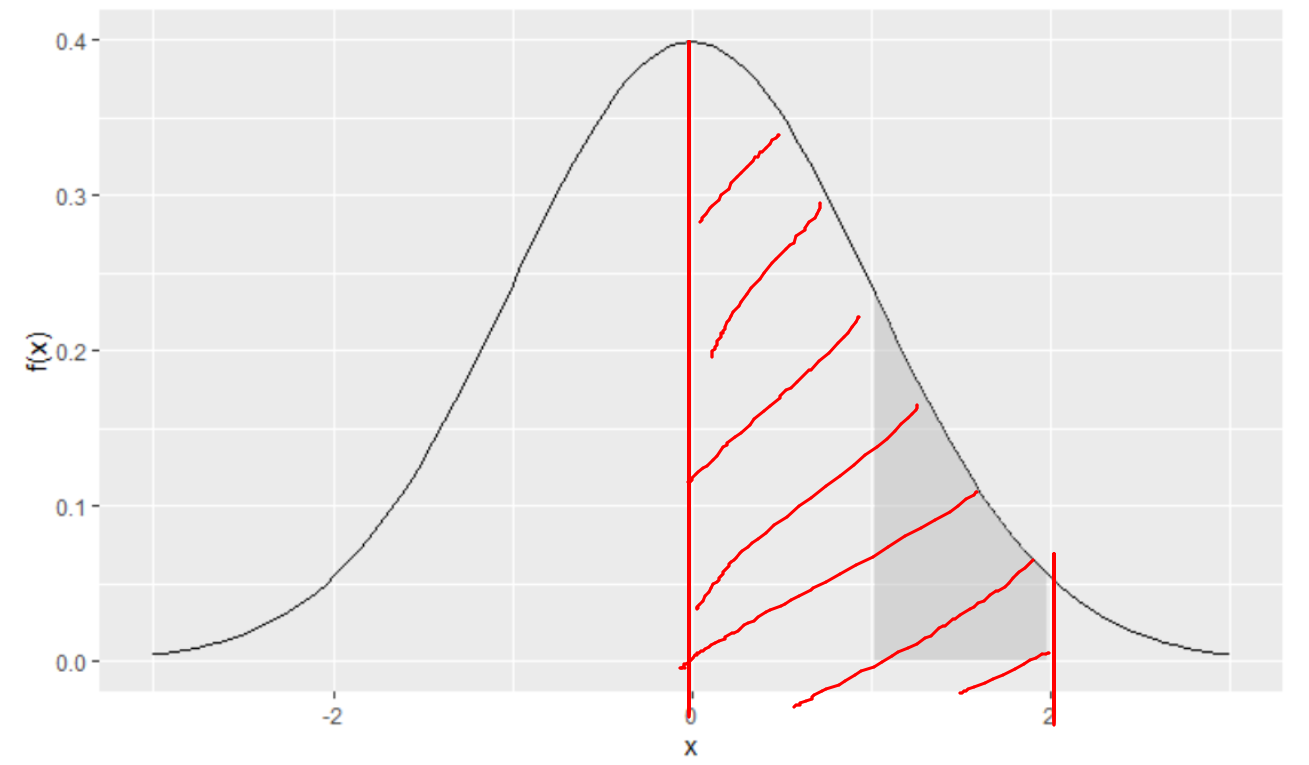
- PDF는 연속확률분포를 나타내는 확률 분포 함수이다. 연속확률 분포이기 때문에 x축 위에 있는 점들과 대응되는 y값은 크게 의미가 없고 면적으로 구간의 확률을 계산한다.
- 예를들어 아래 빗금친 부분의 면적을 \(S\)라 하겠다. 0~2 사이 값의 확률을 알고 싶다면 다음과 같은 식으로 계산된다(구간의 확률). 만약 PDF의 함수를 \(f(x)\)라하고 이 함수가 정규분포를 따른다고 가정해보자.
CDF(Cumulative Distribution Function)
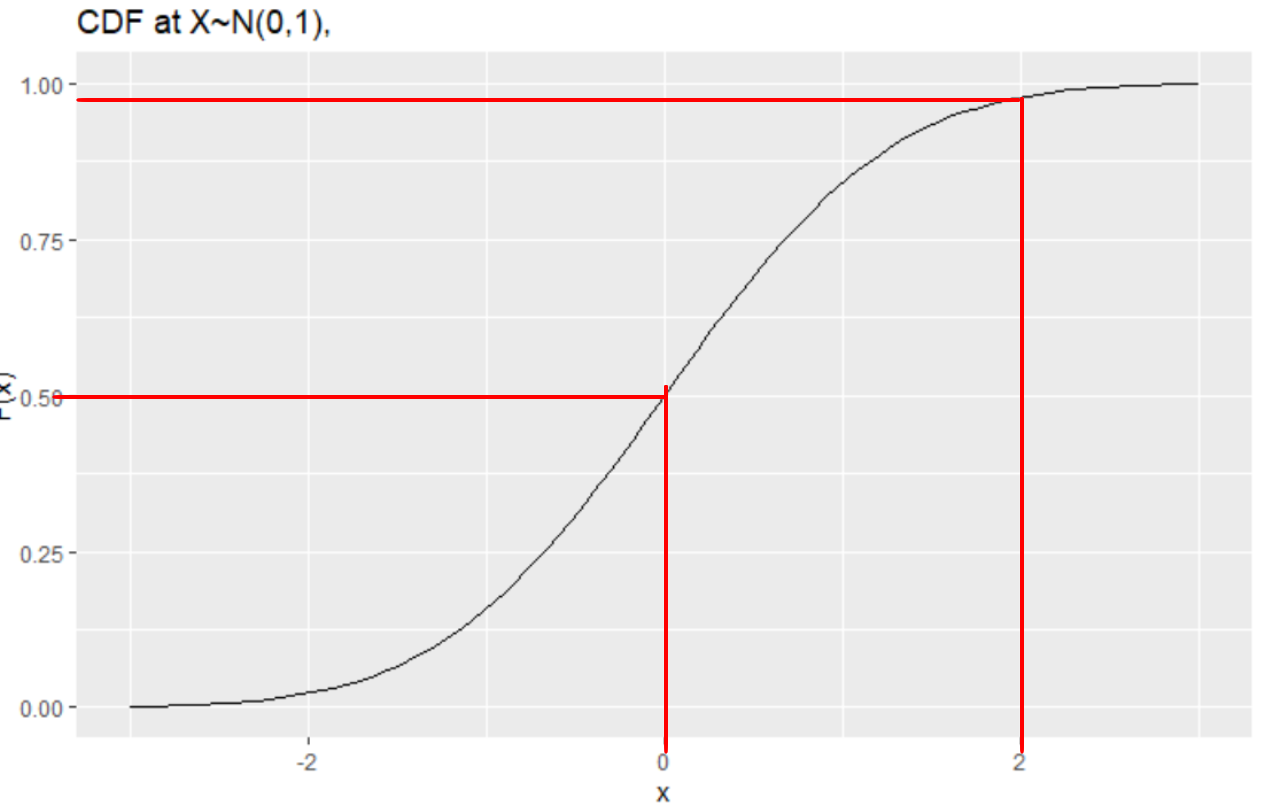
CDF는 PDF를 적분한 함수라 보면된다. 따라서 x축의 점들과 대응되는 점들의 y값이 누적확률로 의미를 가진다. PDF의 함수를 \(f\)라하고 적분한 함수를 \(F\)라 하자.
PDF는 면적이 확률이기 때문에 y값이 0~1사이로 고정되지 않지만 CDF는 y값이 확률이기 때문에 모든 y값들이 0~1사이의 값을 갖는다.
만약 x가 0과 2사이의 확률 값을 구하고 싶다면 아래와 같다.
모수 추정
모집단의 일부인 표본에서 통계 분석 방법을 적용해 모수(parameter)를 추정하는 방법을 모수 추정이라 한다.
표본으로 부터 추정하는 이유는 분석 대상 전체(모집단)를 분석하기에는 많은 비용이 발생하므로 부분(표본)을 통해 모집단의 특성을 파악하는 것이다.
하지만 이러한 통계적 추론에는 부분(표본)을 통해 전체를 추정하는 격이므로 오차가 발생할 수 밖에 없다. 이러한 모수 추정에서 발생하는 오차를 표준오차라고 한다.
- 데이터들이 어떤 확률 분포에서 샘플링 되었다고 생각해 보도록 하겠다.
- 위 식에서 \(p(x| \theta)\) 의미하는 바는
이상적인 확률 분포를 뜻한다. 이러한 이상적인 확률분포에서 \(X\)를 수집한다. - 일반적으로 모수(paramter) \(\theta\)추정의 목적은 관측된 데이터의 실제 확률 분포 \(p(x| \theta)\)를 최대한 잘 근사 하는 수학적 모형을 찾는 것이다. 이와 같이 근사하는 방법을 사용하는 이유는 실제 데이터 확률 분포 또는 실제 파라미터 \(p(x| \theta)\)를 정확히 할 수 없기 때문이다.
- 따라서 임의의 확률 모형 \(p(x|\cdot)\) 을 가정한 뒤, 적어도 그 모형이 데이터를 가장 잘 설명하는 파라미터 \(\hat{\theta}(\approx\theta)\)를 찾는 것이다.
아래 좀 더 자세히 설명하겠다.
Likelihood
연속확률분포에 해당되는 PDF에서 y값은 의미를 갖지 않지만 Likelihood를 쉽게 설명하기 위해 그림에 나온 분포의 y값이 의미를 가진다고 보겠다. 즉 이산확률분포와 같이 y값이 확률이라고 가정하고 설명하겠다.(정확히는 연속확률분포라면 구간에 대한 면적을 구해서 면적에 대한 값을 최대화하는 식으로해야함)
고정되는 요소가 분포가 아니라 관측값들이 고정되는 관점으로 보면된다. 쉽게 말해 가능도란 어떤 값이 관측되었을 때, 이것이 어떤 확률 분포에서 나왔을 지에 대한 확률이다.
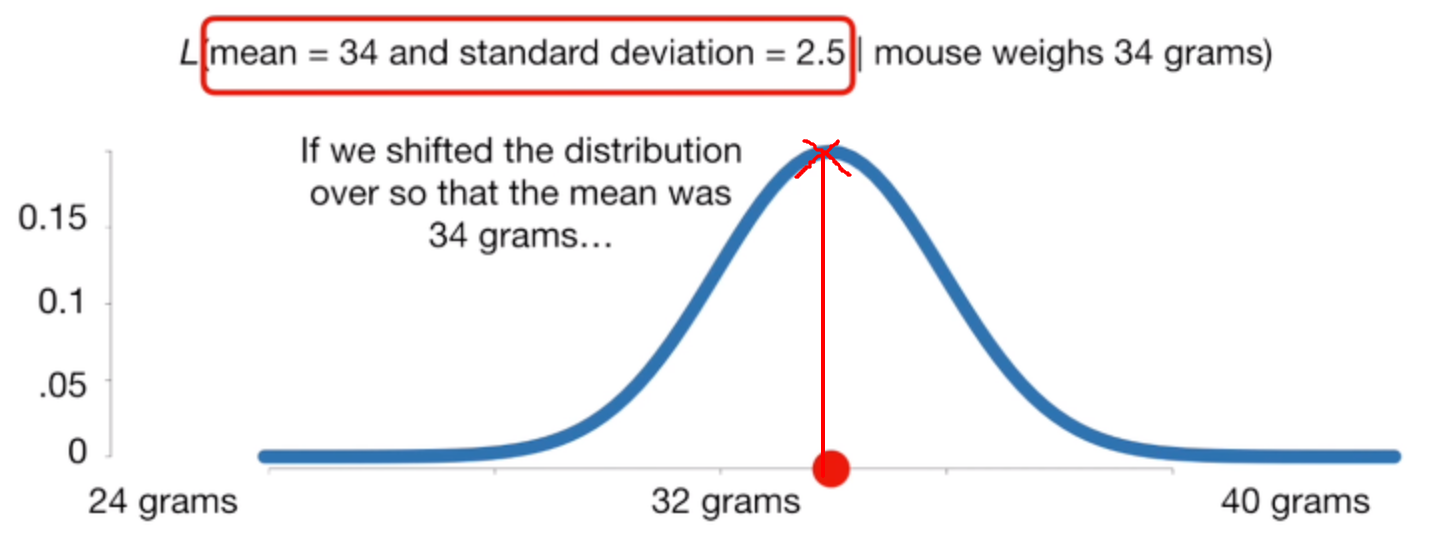
예를들어보자. 쥐를 하나 골라서 무게를 달았는데 34g이 나왔다. 이때 관측결과가 정규분포 \(N(\mu=32,\;\theta=2.5)\)에서 나왔을 확률값은 0.12(빨강색 +)이고 이 값)이 가능도이다. 관측값이 고정되고, 그것이 주어졌을 때 해당 확률분포에서 나왔을 확률을 구하는 것이다.
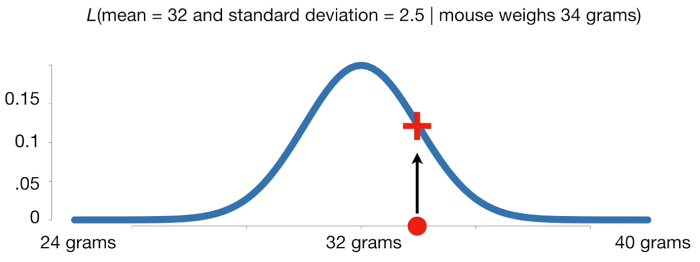
그렇다면 아래 그림에서 평균이 34인 확률분포에서 나왔을 확률은 어떻게 될까? 그림과 같이 그 가능도는 높아진 것을 확인할 수 있다.
Maximum likelihood
Maximum likelihood는 각 관측값에 대한 총 가능도(모든 가능도의 곱)가 최대가 되게하는 분포를 찾는 것이다.
예를 들어보자.
(분포_1, 분포_2 … 분포_N)라는 것의 parameter(\(\mu, \theta\))를 추정하고 모든 관측치에 대한 가능도를 구해보자.
이때 다 곱하는 이유는 주어진 data sample들이 독립적으로 관측된다고 가정하기 때문이다.
- (분포_1의 평균을 0.7, 분산을 4로 한다면)의 가능도 값을 \(L_1\)
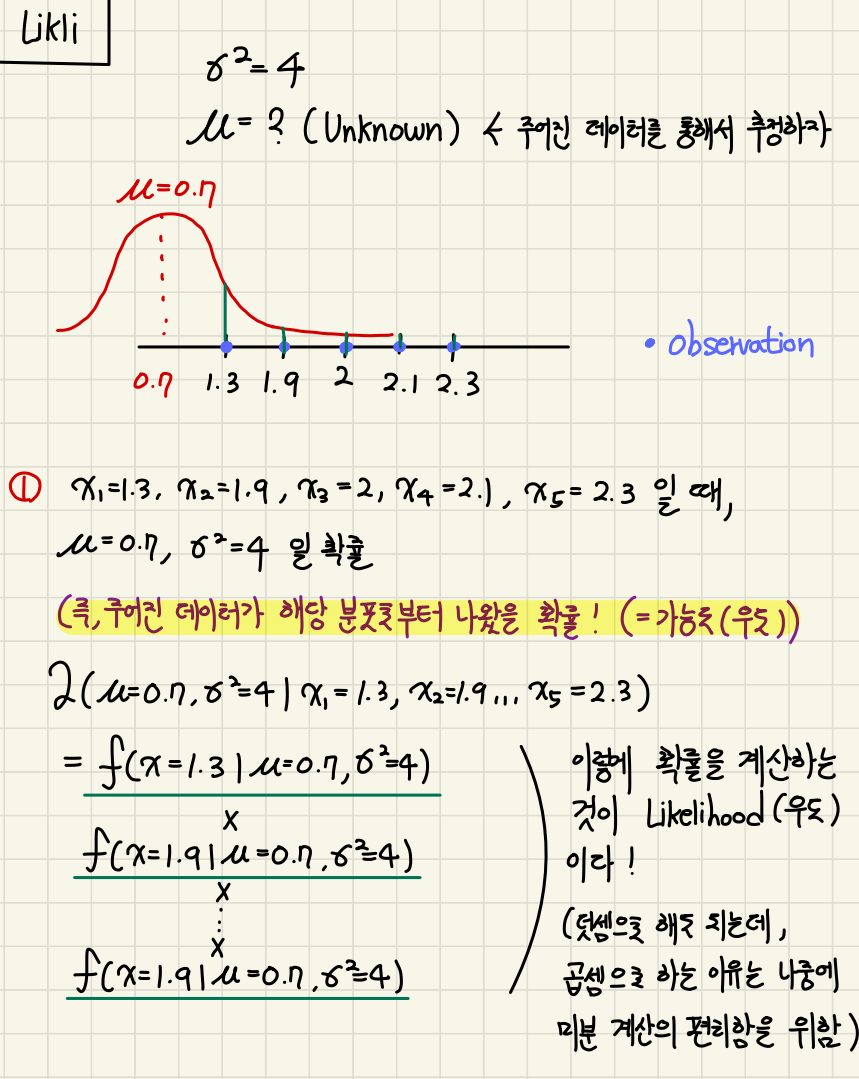
- (분포_2의 평균을 0.9, 분산을 4로 한다면)의 가능도 값을 \(L_2\)
- (분포_3의 평균을 1.1, 분산을 4로 한다면)의 가능도 값을 \(L_3\) …
- 이렇게 쭉 구하면 \(L_1, L_2, ... ,L_N \)이 구해질 것이고 이 중에서 가장 큰 L값이 바로 Maximum likelihood이다.
아래 그림 처럼 여러 개의 관측값을 구했다고 가정해보자.
Maximum likelihood Estimation 종류의 계산은 먼저 임의의 분포를 가정하는 것이 일반적인데 우리는 일단 정규분포를 가정하고 설명하겠다.

먼저 관측될 가능성이 가장 큰 분포가 뭔진 몰라도 정규분포라는 것을 가정했다. 그렇다면 만약 해당 왼쪽에 평균이 치우친 정규분포일 때 총 가능도는 어떻게 될까?
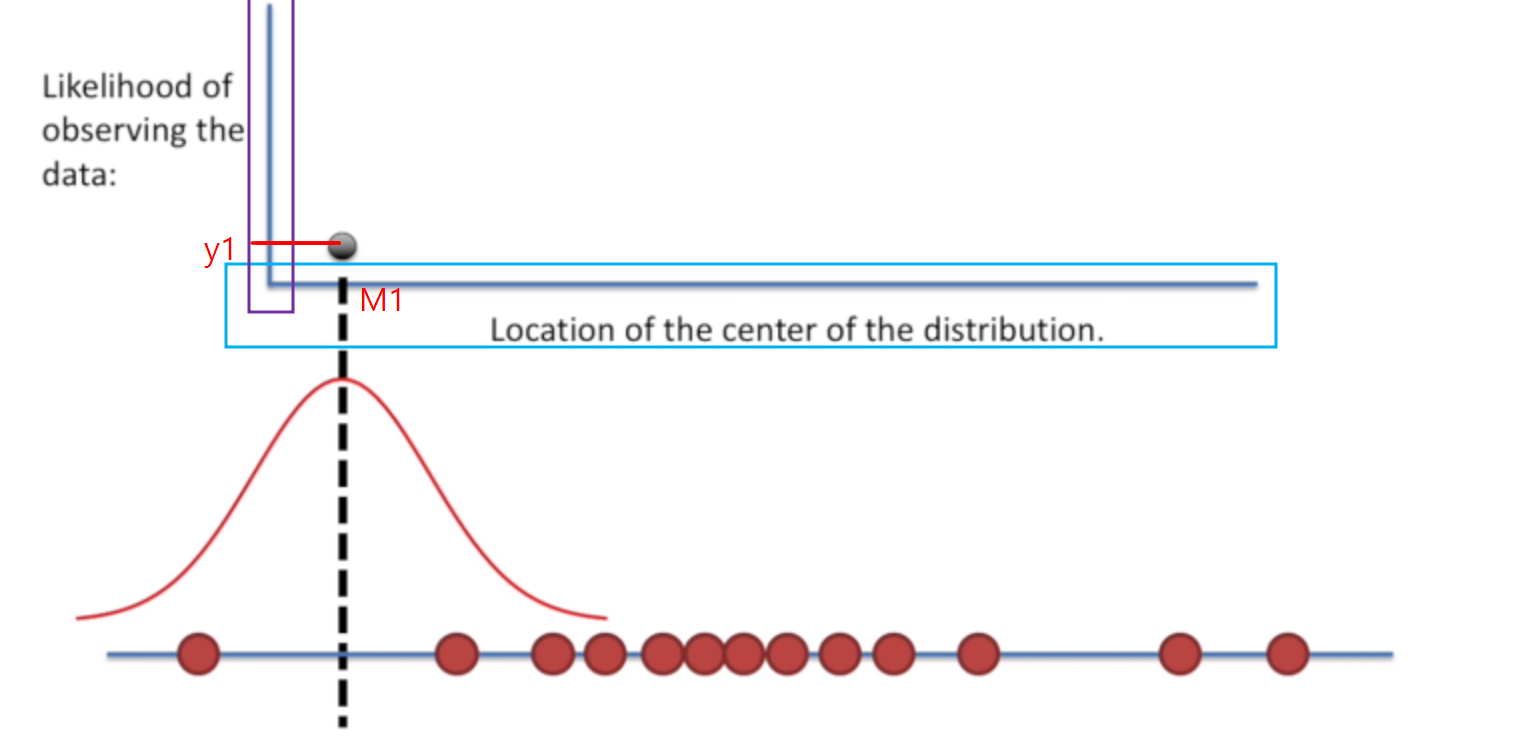
- Likelihood of observing the data(보라색 박스)는 전체 관측치(빨강 sample들)에 대한 최가능도이다.
- 파란색 박스에 해당하는 x축은 각 분포의 평균을 나타낸다.(따라서 분포의 가운데)
아래 그림을 해석하면 전체 관측치에 대해 parmeter M1(평균)을 갖는 분포의 likelihood는 y1이다.
다시 말하면 데이터가 빨간색 sample들로 주어졌을 때(분산은 고정시키고 평균만 변경함), 평균이 M1 정규분포에 대한 likelihood(우도, 가능도) 가 y1이다.
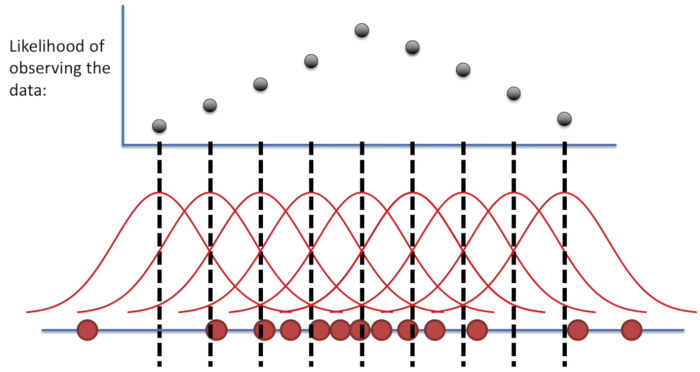
아래 그림은 정규분포의 평균을 조금씩 키웠을 때마다(평균에 해당하는 x축을 오른쪽으로 이동) 가능도는 어떻게 변하는가를 확인할 수 있다. 즉 우리가 수집한 관측값들이 나올 수 있는 가장 가능한 확률분포는 가능도가 제일 큰, 즉 검은 점이 제일 높이 위치한 정규분포에서 왔다고 추정하면 되겠구나! 라는 결론을 내릴 수 있는 것이 최대 우도 추정이다.
MLE(Maximum Likelihood Estimation)
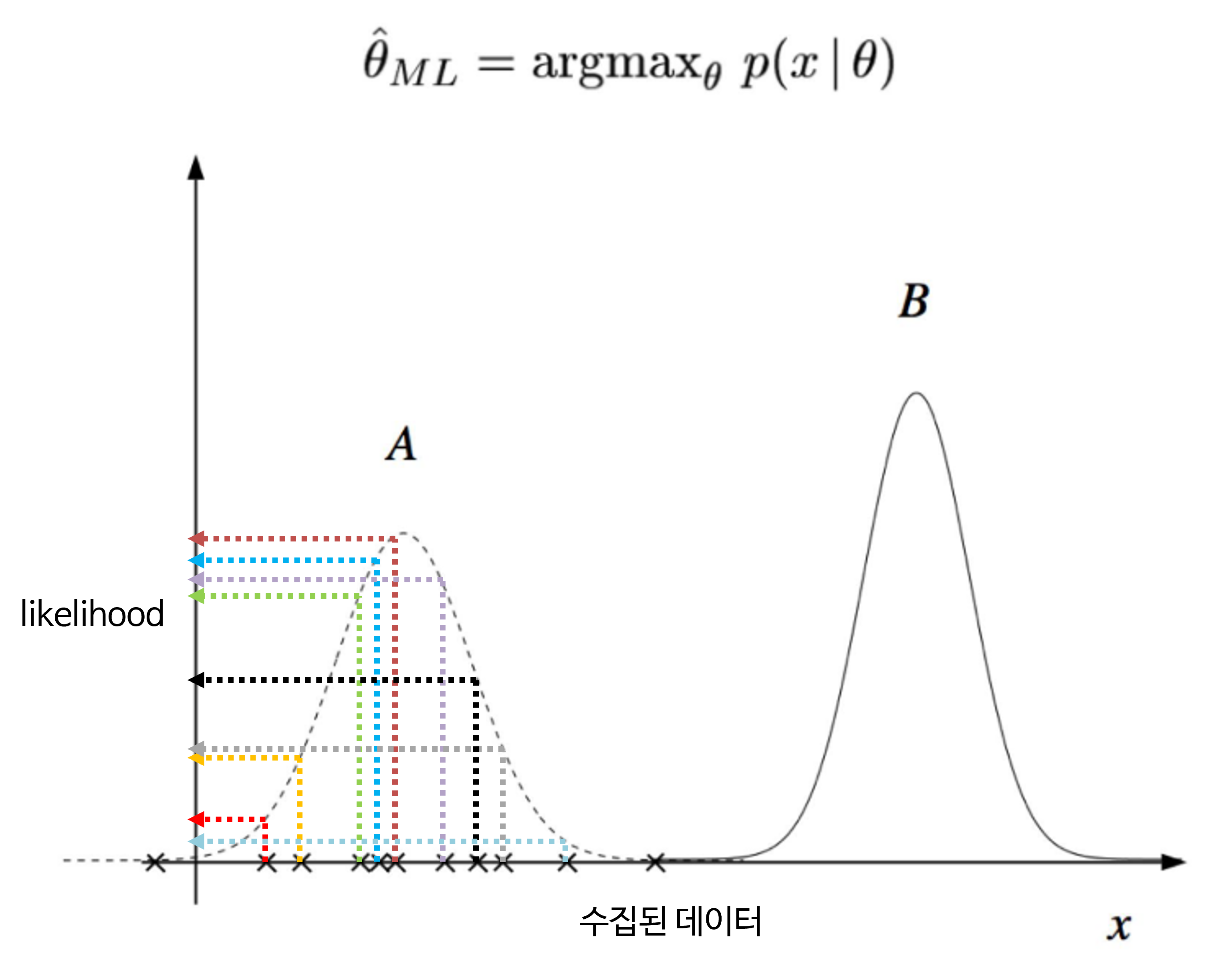
정리해보자. 아래 그림을 보면 \(x\)축 위에 X로 표시된 수집된 데이터가 있다. A라는 분포와 B라는 분포가 가우시안 분포라고 한다면, 두 분포 중에서 수집된 데이터를 잘 표현하는 분포는 A이다. 이 때 두 분포 A, B를 결정하는 값은 \(\theta = (\mu,\sigma^2)\) 이다. 앞에서 설명한 것처럼 likelihood의 곱을 최대로 만들어 주는 \(\hat{\theta}\) 를 찾는 문제가 MLE다.
Log likelihood function
- 머신러닝 및 딥러닝에서 많이 다루는 방법이 단순히 likelihood를 최대화 하는 것이 아니라 log likelihood를 최대화 하는 방법을 많이 사용한다.
- 왜냐하면 MLE를 추정할 때, 어떤 분포에서 각 sample들이 가지는 확률을 전부다 곱하여 likelihood를 구하는데, 이 결과가 기하급수적으로 작아지므로(확률은 0~1사이의 값을 갖기 때문이다) 합으로 바꾸어서 표현하기 위함이다.
- MLE 방식으로 모수 추정을 하기 위해서 실제 likelihood \(L(\theta)\)에 log를 붙인 log likelihood \(l(\theta)\)를 아래 식과 같이 표현할 수 있다.
- 아래 수식의 의미는 함수 “\(L(\theta)\)를 최대로 만드는 \(\theta\)값을 찾아라” 뜻이다. 이때 \(x\)는 함수 \(L\)의 입력값이 된다. 함수 \(L(\theta)\) 혹은 \(l(\theta)\)를 최대로 만드는 그 \(\theta\)값을 \(\hat{\theta}\)으로 정의하라 라는 것이다.
- 식 (1) → 식 (2)로 변경해도 등식이 성립하는 이유는 log 함수가 단조 증가 함수이기 때문에 log를 적용해도 최솟값, 최댓값에 해당하는 모수를 추정할 때 전혀 영향을 미치지 않는다.
- 식 (3) → 식 (4)로 변경하면서 평균을 구하는 의미를 부여한다. 물론 이 과정에서도 MLE에 해당하는 \(\theta\)를 찾는 것에는 영향을 미치지 않는다.
Dataset \((x_i)_{i=1}^{n}\)으로 부터 정의된 식 (9)를 흔히 empirical expectation이라 부르며 아래와 같이 표현한다.
⚠️ 단조 증가 함수란?
입력 값이 증가함에 따라 출력 값도 증가하는 함수를 말한다. log 함수는 단조 증가 함수로 입력 값 사이의 순서 관계가 출력 값 사이의 순서 관계에 동일하게 영향을 미친다.
만약 a < b가 주어진 상황에서 어떤 단조 증가 함수 f를 적용하면, f(a) < f(b)가 되고 반대로 a > b라면 f(a) > f(b)가 된며 a = b라면, f(a) = f(b)된다.
MLE with Gaussian
MLE로 Parameter를 추정하고자 할 때, DataSet이 특정 분포(베르누이, 가우시안 분포) 등을 따른다고 먼저 가정하여 분포를 선택한다.
이 가정을 기반으로 Dataset이 표현하는 분포의 parameter를 추정하는 것이다.
따라서 확률 분포를 가우시안이라고 가정하고 모수를 추정해보겠다.
가우시안 분포임으로 아래와 같은 식으로 쓸 수 있다.
Likelihood를 구하면 아래 식으로 표현할 수 있다. \((\log_a MN = \log_aM + \log_aN)\)성질에 의거.
양변에 Log를 씌우면 아래와 같다.
Liklihood \(L\)의 최대값을 구하기 위해 \(\mu\)로 미분한 함수가 0이 되는 지점이 최대값이 된다.(이계도함수로 또 찾지 않는 이유는 원래의 함수가 Convex(정규분포처럼)하기 때문이라 생각된다.)
쉽게 말하면 원래의 함수가 Convex한 모형을 갖기 때문에 꼭짓점의 기울기가 0일 것이고 따라서 미분한 함수에서 = 0을 찾으면 된다는 것이다.
이번엔 \(L\)함수가 최대값을 갖도록하는 를 찾아보자.
가 됨으로 정리하면 아래와 같다.
따라서
가 된다.
[reference]
https://gaussian37.github.io/ml-concept-probability_model/#mle-with-gaussian-1
Comment