
서론
이 논문은 기존 2D LiDAR 기반 이동 로봇 내비게이션의 한계를 해결하기 위해, Monocular Depth Estimation(MDE) 기반 Teacher-Student framework를 제안한다.
Teacher policy는 시뮬레이션에서 2D LiDAR와 로봇 자기 상태 정보를 입력으로 받아 PPO로 학습된다. 이후 Student policy는 시뮬레이션에서 렌더링한 depth map에 noise augmentation을 적용한 입력과 자기 상태 정보를 사용하여, Teacher의 action을 모방하는 behavior cloning 방식으로 학습된다.
실제 추론 단계에서는 4개의 RGB 카메라 이미지가 fine-tuned Depth Anything V2를 통해 depth map으로 변환되고, 이 depth map과 자기 상태 정보가 Student policy에 입력된다. Student는 최종적으로 로봇의 속도 명령 \((v_x, v_y, \omega_z)\)을 출력하며, 전체 추론은 NVIDIA Jetson Orin AGX에서 10 Hz로 실행된다.
핵심적으로 이 논문은 2D LiDAR를 사용하지 않고도, RGB 카메라 기반 depth map만으로 실제 로봇 내비게이션이 가능함을 보인 연구이다.
목차
- 서론
- 1) Teacher Model Training
- Input
- Output
- 학습방법
- Reward Function
- Teacher Model architecture
- Actor Network
- Critic Network
- 2) Teacher Model Inference
- Depth Map Generation
- Noise Augmentation
- 3) Student Model Training
- Input
- Output
- 학습 방법 (Behavior cloning)
- 4) Student Model Inference
- Input / Monocular Depth Estimation(MDE)
- Output
- Student Model architecture
- Experiment
- Simulation Environment
- Hardware spec
- Simulation Asset
- Simulation Results: Teacher Policy
- Simulation Results: Student Policy
- Sim to Real Analysis
- Conclusion
1) Teacher Model Training
시뮬레이션 환경에서 산업환경 물체(장애물)의 실제 경계보다 확장된 privileged collision mesh를 정의하고, 이에 대해 2D LiDAR raycasting을 수행하여 얻은 거리 정보와 로봇의 자기 상태 정보를 입력으로 teacher policy를 PPO 알고리즘으로 학습한다.
Input
\(o_t^{teacher}=(o^p_t,\;o_t^e)\)
자기 상태(Proprioceptive) 정보
- \(o^p_t = [s_t^{odom},\;p_{robot}^{goal},\;d_{goal},\;a_{t-1}]\)
- \(s_t^{odom}\): 로봇의 최근 속도 이력으로 논문에서는 \(n_{odom}=5\) 만큼 속도 이력 벡터로 구성됨
- \(v^{odom} = ( v_x,\;v_y,\;\omega_z)\)
- x축 방향 속도
- y축 방향속도
- z축 방향 회전 속도
- \(s_t^{odom}\) = ( \(v_t^{odom},\;v_{t-1}^{odom}, ... \;,\;v_{t-n}^{odom})\)
- \(v^{odom} = ( v_x,\;v_y,\;\omega_z)\)
- \(p_{robot}^{goal}\): 로봇 기준에서 목표가 어느 방향이 있는지 알려주는 벡터
- \(d_{goal}\): 목적지까지의 유클리드 거리(Euclidean distance)
- \(a_{t-1}\): 이전시점의 행동
- \(s_t^{odom}\): 로봇의 최근 속도 이력으로 논문에서는 \(n_{odom}=5\) 만큼 속도 이력 벡터로 구성됨
- (Omnidirectional Mobility(앞뒤좌우로 움직이는 로봇)으로 목표방향을 위해 몸체를 돌리는 행위가 필요 없음.)
외부 센서 데이터(Exteroceptive) 정보
- \(o_t^e\): 2D LiDAR Scan data
- \(n_{scan}= 3000\)
Output
마지막 출력단에서는 hyperbolic tangent 함수를 적용하여 policy의 action output을 [−1,1] 범위로 제한한다.여기서 출력값은 아직 실제 물리 속도가 아니라, 정규화된 속도 명령이다. 따라서 실제 로봇에 전달하기 전에 각 최대 속도값을 곱해 물리적 속도 명령으로 변환한다.
예를 들어 teacher policy의 출력이 다음과 같다고 하자.
그러면 실제 속도 명령은 다음과 같이 계산된다.
따라서 최종적으로 로봇에는 다음과 같은 속도 명령이 전달된다.
- \(a_t^{teacher} = (v_x,\;v_y,\;\omega_z) \in [-1,\;1]^3\)
- \(v_x\): x축 방향 속도 명령
- \(v_y\): y축 방향 속도 명령
- \(\omega_z\): z축 회전 속도 명령
학습방법
Teacher policy는 지도학습처럼 정답 행동을 맞히는 방식이 아니라, PPO 기반 강화학습으로 학습된다.
Teacher는 매 timestep t에서 다음 입력을 받는다.
여기서 \(o^{e}_{t}\)는 privilieged collision mesh에 대해 2D LiDAR raycasting으로 얻은 거리 정보이고, \(o^{p}_t\)는 로봇의 자기 상태 정보이다. Teacher policy는 이 입력을 바탕으로 action을 출력한다.
출력된 action은 시뮬레이션 로봇에 적용되고, 로봇은 한 timestep 이동한다. 그 결과 로봇이 목표에 가까워졌는지, 충돌했는지, 장애물에 너무 가까워졌는지, 행동이 너무 급격했는지 등을 기준으로 reward를 받는다. 따라서 Teacher가 학습에서 기준으로 삼는 것은 정답 누적 보상이다.
Reward Function
- \(r_{\text{finished}}\): 목표에 도달했을 때 주는 큰 양의 보상
- \(r_{\text{collision}}\): 장애물과 충돌했을 때 주는 큰 음의 보상
- Timeout: 제한 시간 안에 목표에 도달하지 못하고 timeout된 경우
- \(r_{\text{at-goal}}\): 목표 반경 안에 진입했을 때 한 번 주는 보너스
- \(\sum_i w_ir^{t}_{i}\): 이동 중 매 timestep마다 주어지는 shaping reward
논문에서는 각 보상 값을 다음과 같이 설정한다.
Continuous Shaping Reward
이동 중에는 다음과 같은 Continuous shaping term이 적용된다.
각 항의 의미는 다음과 같다.
- \(r_{\Delta d}^t\): 목표에 가까워지면 보상을 주는 항으로 목표까지의 거리가 줄어들수록 좋은 행동으로 평가한다.
- \(r_{\text{lidar}}^t\): 장애물에 너무 가까워지면 penalty를 주는 항으로 최소 LiDAR 거리값이 \(d_{min}\)보다 작아지면 장애물에 가까운 위험한 행동으로 본다.
- \(r^{t}_{a}\): 너무 큰 속도 명령을 내지 않도록 하기 위함
- \(r_{\Delta a}^t\): 이전 행동과 현재 행동의 차이가 너무 크지 않도록 하여 속도 명령을 부드럽게 만들기 위함
논문에서 사용한 weight는 다음과 같다.
Teacher Model architecture
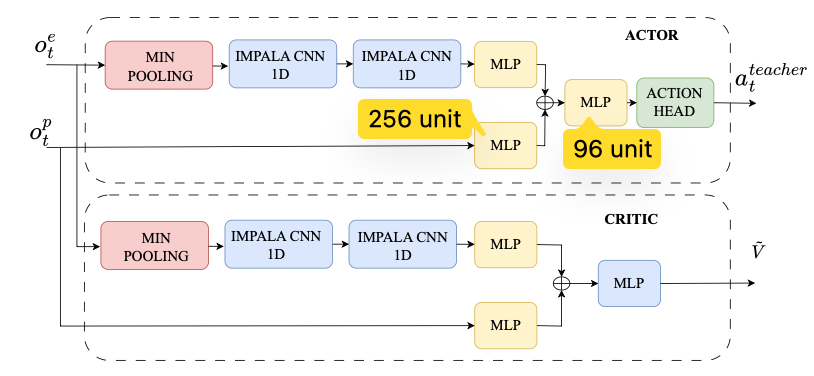
Teacher policy는 Actor, Critic Network로 구성된다.
Actor는 현재 관측값을 보고 로봇이 수행할 action을 출력한다.
Critic은 현재 관측 상태가 얼마나 좋은 상태인지 평가하는 value를 출력한다.
따라서 Actor는 “어떻게 움직일 것인가?”를 결정하고, Critic은 “현재 상태가 앞으로 좋은 보상을 받을 수 있는 상태인가?”를 평가한다.
Actor Network
LiDAR Input 처리 경로
Actor에서 LiDAR 입력 \(o^e_t\)는 다음 순서로 처리된다.
먼저 LiDAR scan은 min-pooling을 통과한다.
Min-pooling을 사용하는 이유는 장애물 회피에서 가장 중요한 정보가 평균 거리보다 가장 가까운 장애물까지의 거리이기 때문이다.
예를 들어 특정 구간의 LiDAR 거리값이 다음과 같다고 하자.
- [3.0, 2.8, 2.9, 0.5, 3.1]
min-pooling을 적용하면 가장 가까운 장애물 거리인 0.5 m가 보존되어 가까운 장애물 정보를 유지하면서 LiDAR 입력 크기를 줄이는 역할을 한다.
그 후 1D IMPALA-CNN block을 통해 LiDAR 거리 배열에서 공간적 패턴을 추출한다.
LiDAR scan은 각도 순서대로 나열된 1차원 거리 배열이므로, 2D CNN이 아니라 1D CNN을 사용한다.
Proprioceptive input 처리경로
Actor에서 자기 상태 입력은 MLP를 통해 처리된다.
Feature concatenation
LiDAR 경로에서 추출된 feature와 자기 상태 정보 경로에서 추출된 feature는 하나로 결합된다.
결합된 feature는 다시 MLP를 통과하고 마지막 Action Head에서 최종 Action을 출력한다.
Action Head의 출력범위는 tanh가 적용되어 action값이 [-1, 1] 범위로 제한된다.
Critic Network
Critic은 Actor와 거의 동일한 입력을 사용하지만, 출력은 action이 아니라 value이다.
Critic의 역할은 현재 관측 상태가 얼마나 좋은지를 평가한다.
최종적으로 Object Function으로는 PPO를 사용한다.
2) Teacher Model Inference
Teacher 모델의 학습이 완료되면 학습된 Teacher Policy를 시뮬레이션 환경에서 Inference하여 Student 모델 학습용 데이터를 생성한다.
Input
이때 Teacher는 Training과 똑같이 입력으로 Privileged Information(2D LiDAR)와 자기 상태정보를 입력으로 받아 행동을 출력한다.
- \(o_t^{teacher}=(o^p_t,\;o_t^e)\)
output
2-1) Depth Map Generation
동시에 Student가 실제로 사용할 입력을 만들기 위해, 로봇에 장착될 4대의 카메라 위치에서 바라본 depth map을 시뮬레이션에서 렌더링하여 추출한다.
- \(D_t\in\R^{4\times300\times480}\)
Noise Augmentation
시뮬레이션에서 렌더링된 depth map은 실제 카메라와 Monocular Depth Estimation(MDE) 모델이 만든 depth map보다 훨씬 깨끗하다. 따라서 실제 환경과의 차이, 즉 sim-to-real gap을 줄이기 위해 \(D_t\)에 노이즈를 추가한다.
- \(D_t \rightarrow D^{noise}_t\)
적용되는 노이즈는 다음과 같다.
- Gaussian smoothing: 렌즈 흐림 효과 반영
- Motion blur: 로봇 움직임으로 인한 흐림 반영
- Background smudging: 먼 거리 depth 품질 저하 반영
- Elastic smearing: 물체 경계 왜곡 반영
- Random scale-shift perturbation: MDE의 scale/shift 오차 반영
- Low-frequency Gaussian noise: 환경적 노이즈 반영
- Quantization noise: 거리 값 압축 및 양자화 오차 반영
3) Student Model Training
Student는 직접 강화학습을 하지 않고, Teacher가 출력한 행동을 정답으로 하여 behavior cloning 방식으로 학습한다.
Input
Student 모델은 noise가 추가된 depth map과 로봇의 자기 상태 정보를 입력으로 받는다
- \(o_t^{student}=(D_t^{noise},\;o_t^p)\)
4개의 카메라에서 얻은 depth map
시뮬레이션에서 4개 카메라 시점으로 렌더링한 depth map Dt에 noise augmentation을 적용한 입력이다. 이는 추후 Student inference에서 MDE 출력으로 발생할 수 있는 blur, scale-shift, edge distortion, quantization noise 등을 모사하기 위한 것이다.
- \(D_t^{noise}\)
자기 상태 정보
- \(o_t^p = (s_t^{odom}, p_{robot}^{goal}, d_{goal}, a_{t-1})\)
- \(s_t^{odom}\): 로봇의 속도 이력
- \(p_{robot}^{goal}\): 로봇 기준 목표 방향 벡터
- \(d_{goal}\): 목표까지의 거리
- \(a_{t-1}\): 이전 시점의 행동
Output
Student 모델 역시 Teacher와 동일한 action space를 사용하며, 마지막 출력단에서 tanh를 적용하여 action 값을 [-1, 1] 범위로 제한한다. 이후 각 출력값에 최대 속도값을 곱해 실제 로봇의 속도 명령으로 변환한다.
- \(a_t^{student} = (v_x,\;v_y,\;\omega_z) \in [-1,\;1]^3\)
학습 방법
Student는 noisy depth map과 자기 상태 정보를 입력으로 받아 Teacher의 행동을 모방하도록 학습한다.
- \(a_t^{student} = \pi_{\theta}(D_t^{noise}, o_t^p) \approx a_t^{teacher}\)
4) Student Model Inference
Student 모델 학습이 완료되면, 실제 로봇에 장착된 4개의 RGB 카메라와 fine-tuned Depth Anything V2 모델을 사용하여 실시간 추론을 수행한다.
Training 단계에서는 시뮬레이션에서 렌더링된 depth map에 noise augmentation을 적용한 \(D_t^{noise}\)를 사용했지만, 실제 Inference 단계에서는 로봇에 장착된 RGB 카메라 이미지로부터 Depth Anything V2가 depth map을 직접 추정한다.
Input
여기서 \(D_t^{MDE}\)는 4개의 RGB 카메라 이미지로부터 fine-tuned Depth Anything V2를 통해 추정한 depth map이다.
4개의 RGB 카메라에서 얻은 이미지를 각각 Depth Anything V2에 입력하여 depth map을 추정하고, 이를 channel 방향으로 stack하여 Student policy의 visual observation으로 사용한다.
Monocular Depth Estimation(MDE)
- \(D_t^{MDE} = [I^1_t,\;I^2_t,\;I^3_t,\;I^4_t]\)
실제 로봇에서는 4개의 RGB 카메라가 로봇 주변 \(360^\degree\)FOV를 커버한다.
각 카메라 이미지에 대해 fine-tuned Depth Anything V2를 적용한다.
여기서 \(I^k_t\)는 k번째 RGB 카메라 이미지이고, \(D_t^{MDE}\)는 4개 카메라에서 추정된 depth map stack이다.
실제 추론 단계에서는 privileged LiDAR나 privileged collision mesh를 사용하지 않는다는 것이다.
Student는 오직 onboard RGB camera로부터 추정된 depth map과 자기 상태 정보만을 사용한다.
자기 상태 정보(Proprioceptive)
Student는 Training 단계와 동일하게 로봇의 자기 상태 정보도 함께 입력으로 받는다.
- \(s_t^{odom}\): 로봇의 속도 이력
- \(p_{robot}^{goal}\): 로봇 기준 목표 방향 벡터
- \(d_{goal}\): 목표까지의 거리
- \(a_{t-1}\): 이전 시점의 행동
Output
출력단에서는 Training 단계와 동일하게 tanh(⋅)를 적용하여 action 값을 [−1, 1]범위로 제한한다.
이후 각 출력값에 최대 속도값을 곱하여 실제 로봇의 속도 명령으로 변환한다.
따라서 최종적으로 로봇에는 다음과 같은 속도 명령이 전달된다.
학습 방법
Student policy는 PPO로 직접 강화학습하지 않고, Teacher가 생성한 expert action을 정답으로 사용하는 supervised imitation learning, 즉 behavior cloning 방식으로 학습한다.
Student 학습의 목표는 다음과 같다.
학습 과정에서는 Teacher action과 Student action 사이의 차이를 줄이기 위해 behavior cloning loss를 사용한다. 이 loss는 Teacher가 출력한 action과 Student가 예측한 action 사이의 평균제곱오차, 즉 MSE로 정의된다.
여기서 N은 batch 안의 sample 개수이다.
Student는 depth map 자체를 정답으로 학습하는 것이 아니라, depth map과 자기 상태 정보를 보고 Teacher의 속도 명령 \((v_x,v_y,ω_z)\)을 모방하도록 학습한다.
Student Model architecture
Student policy는 Teacher actor network와 유사한 구조를 가진다.
하지만 Teacher가 privileged information인 2D LiDAR 정보를 사용하는 것과 달리, Student는 4개의 RGB camera로부터 얻은 depth map을 입력으로 사용한다.
Teacher는 학습 과정에서 더 정확한 환경 정보를 이용하여 좋은 행동을 생성하고, Student는 실제 로봇에서 사용 가능한 depth map과 proprioceptive observation만을 이용하여 Teacher의 행동을 모방하도록 학습된다.
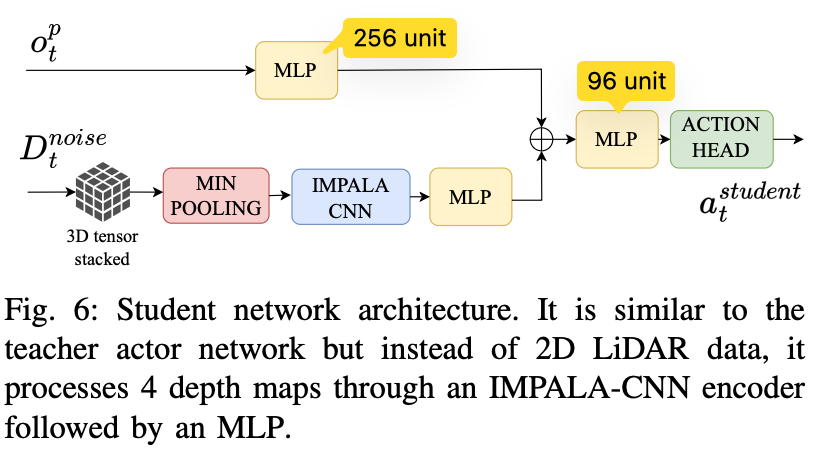
Proprioceptive input 처리 경로
Student network에서 자기 상태 입력 \(o^p_t\)는 MLP를 통해 처리된다.
이 MLP는 로봇의 자기 상태 정보를 feature vector로 변환한다.
그림에서는 이 경로의 출력 feature dimension을 256 unit으로 표현한다.
proprioceptive input은 MLP를 통과하여 256차원의 feature로 변환된다.
Depth map input 처리 경로
먼저 4개의 depth map은 하나의 3D tensor 형태로 stack된다. 여기서 H와 W는 depth map의 height와 width를 의미하고, 4는 네 개의 camera 또는 네 개의 depth map channel을 의미한다.
Depth map은 먼저 min-pooling을 통과한다. Min-pooling을 사용하는 이유는 navigation이나 collision avoidance 문제에서 가장 중요한 정보가 평균 depth 값이 아니라 가장 가까운 장애물까지의 거리이기 때문이고 로봇이 충돌을 피하는 데 중요한 정보를 유지하면서 입력 크기를 줄이는 역할을 한다.
그 후 IMPALA-CNN encoder를 통해 depth map의 공간적 특징을 추출한다. Depth map은 이미지 형태의 2차원 공간 정보를 가지므로 CNN을 사용하여 장애물의 위치, 거리 분포, 통로 구조, 주변 환경의 패턴 등을 feature로 추출한다.
CNN을 통과한 feature는 다시 MLP를 거쳐 depth feature vector로 변환된다. 그림의 구조에 맞추어 depth feature도 256차원으로 표현된다.
Feature concatenation
Student network는 proprioceptive feature와 depth feature를 하나로 결합한다..
만약 두 feature가 각각 256차원이라면, concat 이후 feature dimension은 512차원이 된다.
이후 MLP를 통과해 96차원의 feature로 바뀐다.
Action output
Action Head는 96차원의 hidden feature를 입력으로 받아 최종 student action을 출력한다.
따라서 Student policy는 다음과 같이 표현할 수 있다.
Experiment
본 연구에서는 제안한 Teacher-Student framework를 시뮬레이션 환경과 실제 로봇 플랫폼에서 평가하였다.
Simulation Environment
시뮬레이션 학습은 Isaac Sim 5.1과 Isaac Lab framework를 사용하여 수행되었다. 학습에는 단일 NVIDIA RTX 4090 GPU가 사용되었으며, 해당 GPU는 24 GB VRAM을 가진다.
Teacher policy는 대규모 강화학습을 위해 1024개의 병렬 시뮬레이션 환경에서 학습되었다. 여러 환경을 동시에 실행함으로써 다양한 navigation 경험을 빠르게 수집할 수 있으며, PPO 기반 teacher policy 학습의 효율을 높일 수 있다.
학습 환경은 서로 다른 크기를 갖는 세 가지 arena configuration으로 구성되었다. 이를 통해 로봇이 특정 공간 크기에만 과적합되지 않고, 다양한 공간 규모에서 일반화된 navigation policy를 학습하도록 하였다.
[Example]
Arena configuration 1: 작은 공간
- 좁은 실내
- 장애물 간격이 좁음
Arena configuration 2: 중간 크기 공간
- 일반적인 창고 통로 크기
Arena configuration 3: 큰 공간
- 넓은 물류 창고 형태
- 이동 거리가 김각 episode에서는 15종류의 서로 다른 object type으로 구성된 pool에서 장애물을 샘플링하고, 이를 arena 내부에 무작위로 배치하였다. 이러한 random obstacle placement는 다양한 장애물 배치와 navigation scenario를 생성하여 policy의 일반화 성능을 높이는 역할을 한다.
- Simulator: Isaac Sim 5.1
- Framework: Isaac Lab
- GPU: NVIDIA RTX 4090 24 GB × 1
- Parallel environments: 1024
- Arena configurations: 3 different sizes
- Obstacles: randomly sampled from 15 object types
Hardware spec
Robot: DJI RoboMaster S1
- 4개의 Mecanum wheel을 사용하여 전방향 이동 가능
- 앞뒤, 좌우 이동 및 제자리 회전 가능
Onboard Computer: NVIDIA Jetson Orin AGX
- Student policy inference 수행
- Fine-tuned Depth Anything V2 기반 MDE 모델 실행
- 외부 서버 없이 로봇 내부에서 실시간 추론 수행
Camera System
- 4개의 RGB camera 사용
- AR0234 global shutter image sensor 장착
- 로봇이 움직일 때 일반 rolling shutter 카메라는 이미지가 휘거나 찌그러질 수 있다. Global shutter는 이미지 전체를 한 번에 찍는 방식으로 움직임이 있는 상황에서도 왜곡이 상대적으로 적다. 그래서 이동 로봇이나 자율주행, 로봇 비전에서 유리하다.
- Arducam LN056 wide-angle lens 사용(광각)
- 4대의 카메라로 로봇 주변 360° FOV 커버
- Luxonis FFC4 module을 통해 hardware trigger 기반 동기화(4대의 카메라가 동시에(같은 시간에) 사진을 촬영하도록 하기위함)
- Image resolution: 480 × 300 pixels
Camera Calibration
- Basalt framework와 AprilTag target으로 카메라 간 calibration 수행 (extrinsic calibration)
- Kannala-Brandt calibration parameter로 광각 렌즈 왜곡 보정 (intrinsic calibration)
- 각 카메라 FOV: 93.97° × 67.64°
LiDAR
- RPLIDAR S2 2D LiDAR 장착 for teacher model
- 실제 LiDAR scan을 n_scan = 3000개의 고정 각도 위치로 rebinned
Simulation Asset
시뮬레이션에서는 실제 DJI RoboMaster S1 로봇을 그대로 단순 모델로 사용하지 않고, 실제 로봇의 동역학 특성이 반영되도록 simulation asset을 구성하였다.
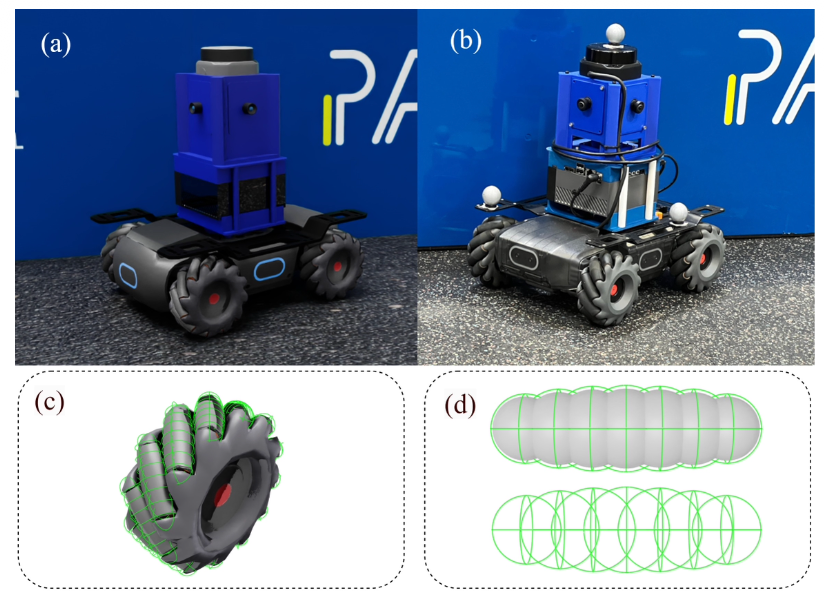
- 메카넘 휠의 롤러 형상은 실제로는 복잡한 곡면 구조를 가지지만, 시뮬레이션에서 이를 그대로 충돌 계산에 사용하면 연산량이 커지고 접촉 계산이 불안정해질 수 있다.
- 따라서 논문에서는 각 롤러를 7개의 sphere collider로 근사하였다. 즉, 눈에 보이는 바퀴 형상은 실제와 유사하게 유지하되, 물리 엔진이 바닥과의 접촉 및 충돌을 계산할 때는 여러 개의 작은 구 형태 collider를 사용하도록 단순한다.
또한 시뮬레이션 로봇이 실제 로봇처럼 움직이도록 하기 위해 마찰, joint damping과 같은 물리 파라미터를 실제 로봇의 움직임 데이터를 바탕으로 추정했다.
- 이를 위해 실제 로봇의 ground-truth motion data를 기록하고, system identification 방법을 사용하여 시뮬레이션 모델의 물리 파라미터를 실제 로봇의 움직임에 맞게 최적화하였다.
- System identification은 실제 시스템의 입력과 출력을 보고, 그 시스템을 잘 설명하는 모델 파라미터를 찾는 과정
마지막으로 RoboMaster 모터는 매우 낮은 속도 명령에서는 실제로 잘 움직이지 못한다. 이러한 저속 구동 한계를 반영하기 위해 각 바퀴에 deadzone을 적용하였다. 이는 작은 속도 명령이 들어왔을 때 실제 로봇처럼 시뮬레이션 상에서도 움직이지 않거나 반응이 제한되도록 만드는 설정이다.
Simulation Results: Teacher Policy
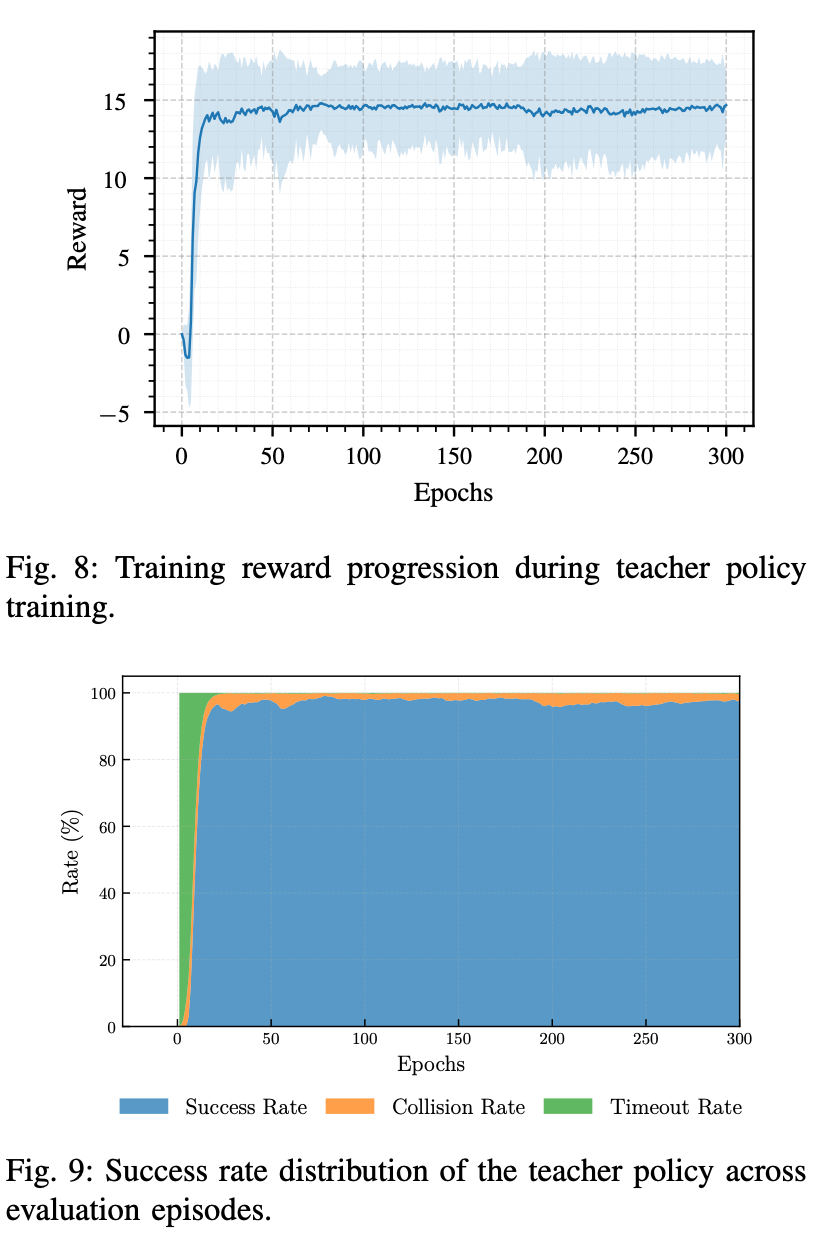
Teacher policy는 시뮬레이션 환경에서 PPO 알고리즘을 사용하여 300 epoch 동안 학습되었고, 전체 학습은 약 120분 정도 소요되었다.
학습 결과, 평균 episode reward는 초기 25 epoch 안에서 급격히 증가하였다. 이후 50 epoch 이후에는 reward가 약 14.5 부근에서 안정화되었으며, 이는 policy가 비교적 빠르고 안정적으로 수렴했음을 보여준다.
Episode 종료 유형을 보면, 학습 초기에는 로봇이 목표에 도달하지 못해 timeout이 많이 발생했다. 이후 로봇이 움직이는 방법을 배우면서 일시적으로 collision이 증가했고, 학습이 진행될수록 장애물을 피하며 목표에 도달하는 successful episode가 대부분을 차지하게 되었다.
최종적으로 Teacher policy는 시뮬레이션에서 최대 98.5%의 성공률을 달성하였다. 이는 privileged LiDAR 정보와 자기 상태 정보를 이용한 Teacher policy가 충돌을 피하면서 목표 지점까지 안정적으로 이동하는 행동을 잘 학습했음을 의미한다.
Simulation Results: Student Policy
Teacher에게 privileged collision mesh를 준 이유는 2D LiDAR가 실제로는 한 높이의 단면만 보기 때문에 지나갈 수 없는 장애물이나 좁은 공간을 놓치지 않도록, 시뮬레이션에서 장애물의 충돌 영역을 로봇 footprint 기준으로 확장해 준 것이다.
Student policy 학습 및 실제 배포를 고려할 때는 이러한 privileged 정보를 사용하지 않는다. 왜냐하면 Depth map은 이미지 전체 영역에서 장애물의 높이와 형태를 함께 포착할 수 있기 때문이다.
Sim to Real Analysis
실제 환경 실험에서 Teacher와 Student의 주행 궤적을 비교한 결과:
- Teacher는 3번의 주행 중 2번 사다리와 충돌
- Student는 목표 지점에 도달하였다.
Student는 MDE 기반 depth map을 사용하여 장애물의 전체 수직 구조를 더 잘 관측하는 반면 Teacher가 사용하는 2D LiDAR가 특정 높이의 scan plane만 관측하기 때문에, 사다리처럼 높이 방향 구조가 복잡한 장애물을 충분히 인식하지 못했다.
하지만 Student의 주행 경로는 진동하는 움직임을 보였다. Depth Anything V2와 Student policy 추론 과정에서 발생하는 inference latency, MDE depth map의 잔여 오차, 그리고 실제 RoboMaster의 동역학을 시뮬레이션에서 완전히 정확히 모델링하지 못한 오차가 함께 작용한 결과로 분석된다.
또한 Depth Anything V2를 창고 환경 데이터로 fine-tuning했음에도 불구하고, 실제 거리와 MDE가 추정한 depth 사이에는 절대 거리 오차가 남아 있었다. MDE는 가까운 거리에서는 비교적 정확했지만 먼 거리에서는 오차가 증가하였다. 이로 인해 실제 환경과 시뮬레이션 사이의 residual sim-to-real gap이 여전히 존재한다.
Conclusion
이 논문은 기존 2D LiDAR 기반 이동 로봇 내비게이션을 MDE 기반 vision navigation으로 대체하기 위한 teacher-student framework를 제안하였다. Teacher는 시뮬레이션에서 privileged LiDAR 정보를 이용해 PPO로 학습되고, Student는 4개 RGB 카메라로부터 얻은 depth map과 자기 상태 정보를 입력으로 사용하여 Teacher의 행동을 모방하도록 학습된다.
시뮬레이션 실험에서 MDE 기반 Student는 장애물 밀도에 따라 82–96.5%의 성공률을 달성했으며, standard 2D LiDAR Teacher의 50–89% 성공률보다 일관되게 높은 성능을 보였다. 실제 로봇 실험에서도 Student는 평균 80%의 성공률을 기록했고, LiDAR 기반 Teacher는 37%에 그쳤다.
Student가 더 좋은 성능을 보인 이유는 depth map이 2D LiDAR의 scan plane 밖에 있는 장애물까지 포착할 수 있기 때문이다. 2D LiDAR는 특정 높이의 한 평면만 관측하지만, full-frame depth map은 장애물의 수직 구조와 전체 형상을 볼 수 있어 복잡한 3D 장애물 회피에 유리하다.
또한 전체 추론 pipeline은 NVIDIA Jetson Orin AGX에서 onboard로 실행되며, 외부 서버 없이 10 Hz 제어 주파수로 동작한다. 즉, 실제 로봇에 탑재 가능한 실시간 vision-based navigation system임을 보였다.
현재 한계로는 정적 장애물 환경에 한정된 점, 먼 거리에서 MDE scale error가 남아 있는 점, 그리고 다른 외부 baseline과 직접 비교하지 못한 점이 있다.(로봇 플랫폼, 센서 마다 너무 다 다양하기 때문)
향후 연구에서는 동적 장애물 회피와 online adaptation을 통해 sim-to-real gap을 더 줄이는 방향으로 확장할 계획이다.
Online adaption: 시뮬레이션에서 학습한 모델을 실제 로봇에 올렸을 때, 실제 환경과 시뮬레이션이 완전히 다르기 때문에 생기는 차이를 로봇이 운용 중에 계속 보정하는 것
Comment