
서론
K8s Node에서 GPU를 사용하기 위한 설치 과정을 설명한다.
1. Nvidia-driver 설치
Nvidia Driver를 설치한다.
sudo apt-get update
sudo ubuntu-drivers devicessudo apt install nvidia-driver-{version}재부팅 이후 터미널에 nvidia-smi를 입력해 제대로 설치되었는지 확인한다.
sudo reboot2. Nvidia-Docker 설치 (nvidIa-docker2)
Nvidia Container Toolkit에 포함되었음으로 Toolkit 설치인 3번으로 넘어간다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listsudo apt-get update
sudo apt-get install -y nvidia-docker2sudo systemctl restart docker설치 확인 명령어
sudo docker info | grep -i nvidia3. Nvidia-container-toolkit 설치
도커 컨테이너에서 GPU자원을 사용할 수 있도록 아래 내용을 설치한다.
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html설치 확인
dpkg -l | grep nvidia-container4. Helm 설치
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.shsudo snap install helm --classic## bitnami repo add
helm repo add bitnami https://charts.bitnami.com/bitnami
## bitnami repo 검색
helm search repo bitnami
## 최신 차트 목록 업데이트
helm repo update 5. 노드 라벨링
노드 이름을 확인한다.
kubectl get nodesTaint 설정(GPU가 필요한 Pod만 GPU 노드에서 실행되도록 함)
kubectl taint nodes {jj-node1} nvidia.com/gpu:NoSchedulejj-node1는 노드 명임으로 노드 명을 확인 후 변경해준다
kubectl label nodes {jj-node1} nvidia.com/gpu=true라벨은 최초 nvidia device plugin을 설치했다면 설치했던 노드의 values.yaml을 참고한다.
만약 어떠한 노드에서도 플러그인이 설치되지 않았다면 6번으로 넘어간다.
cd nvidia-device-plugin
vim values.yaml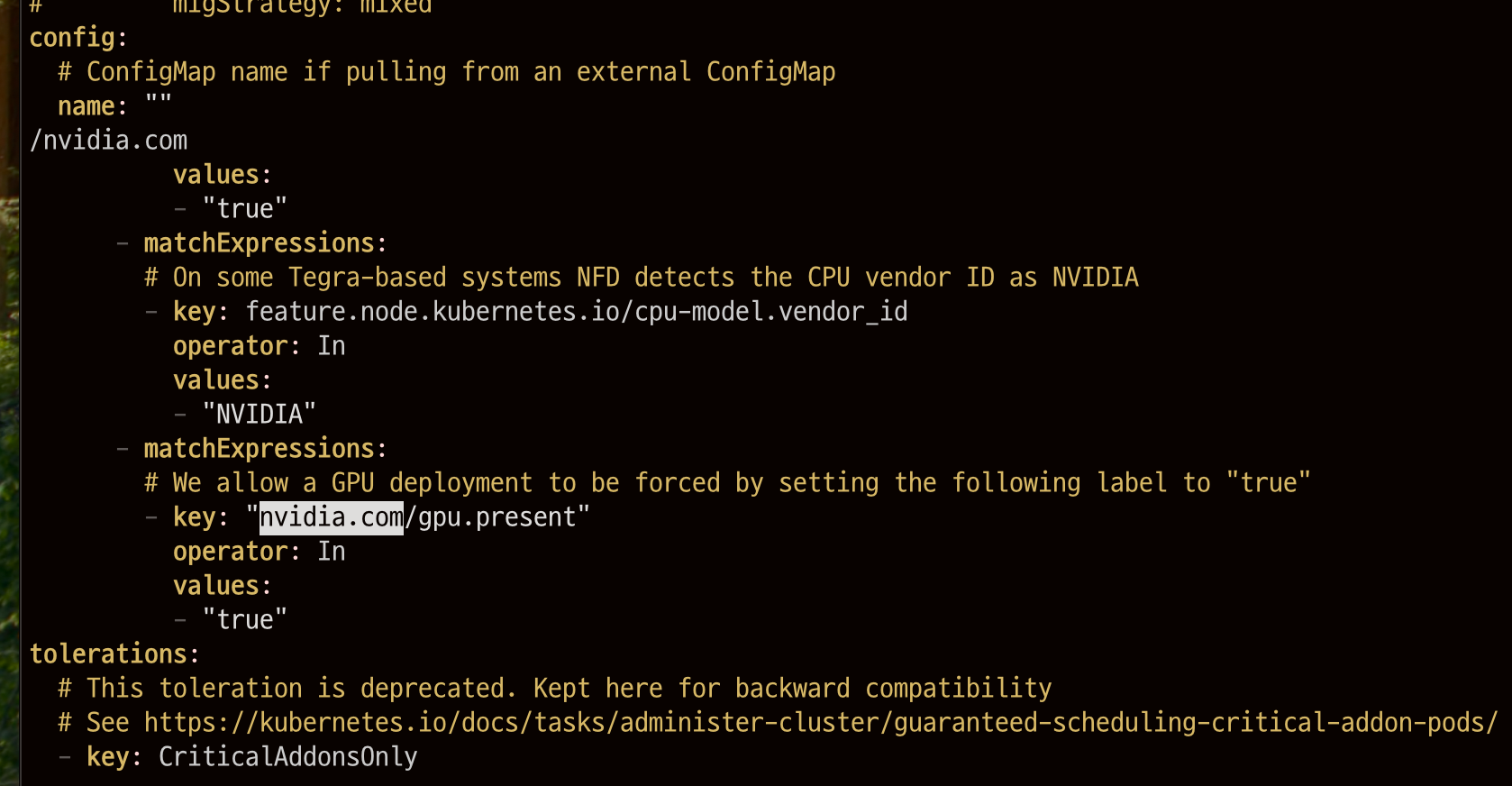
kubectl label nodes {jj-node1} nvidia.com/gpu.present=true6. Nvidia device plugin 설치
k8s에서 GPU리소스를 관리하기 위한 플로그인으로 데몬셋으로 배포하기 때문에 GPU가 있는 노드가 발견되면 플러그인을 실행시켜준다. 따라서 마스터노드에서만 설치하여 배포하면 알아서 워커 노드에도 자동 실행된다.
values.yaml에서 라벨을 확인한다.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm pull --untar nvdp/nvidia-device-plugin
cd nvidia-device-plugin
vim values.yaml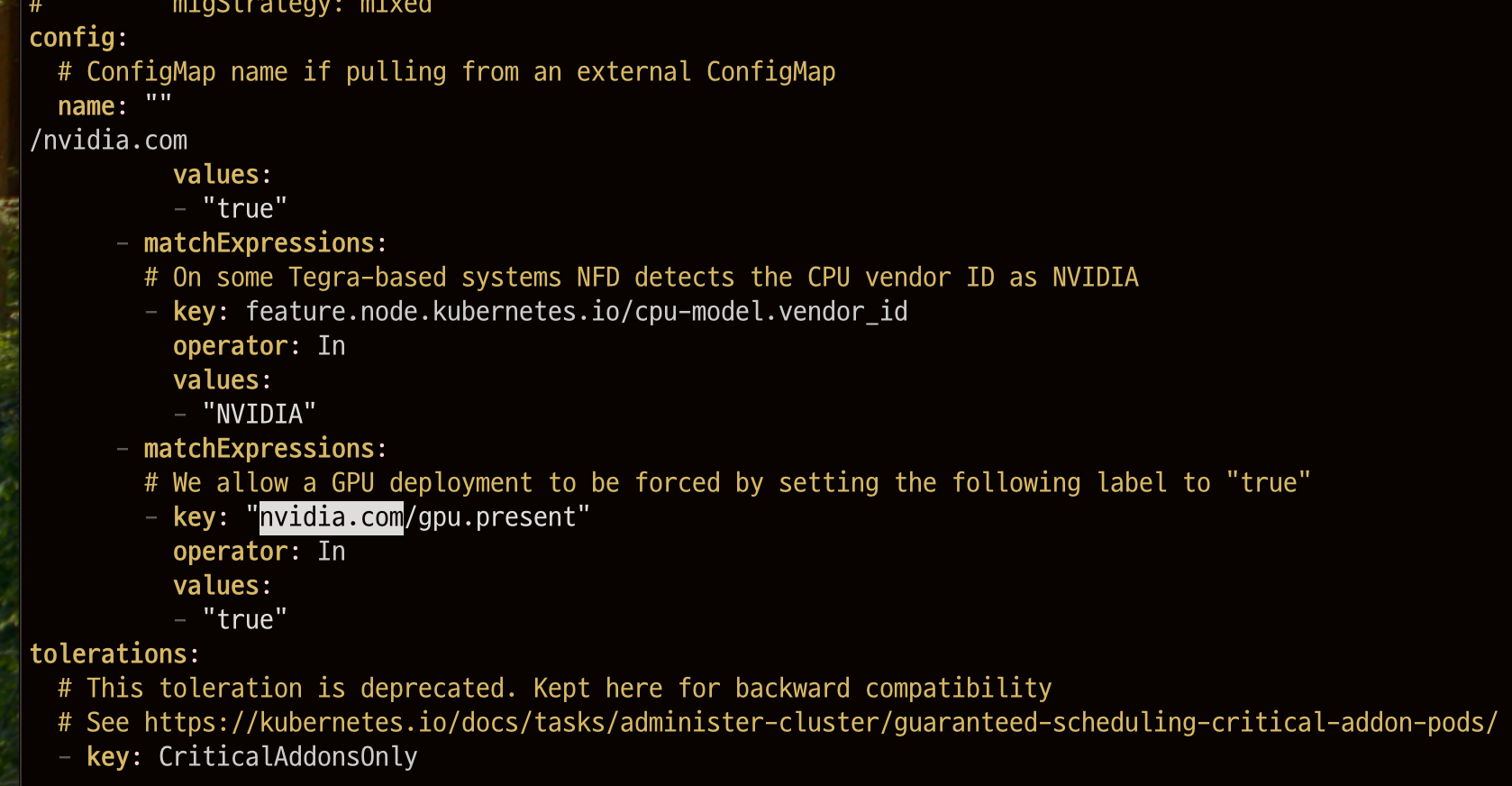
확인된 라벨로 노드 라벨 설정(데몬셋이 GPU파드를 실행할 때 위 라벨과 일치하는 노드에서만 실행하도록 한다 = GPU파드는 GPU노드에서 실행할 수 있도록 함)
kubectl label nodes jj-node1 nvidia.com/gpu.present=truehelm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.17.0helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.16.0
kubectl get daemonset nvdp-nvidia-device-plugin -n nvidia-device-plugin만약 위 과정에서 문제가 생긴경우 helm으로 설치하지 않고 yaml을 이용해 설치하는 방법은 아래 명령어를 입력한다.
kubectl create -f kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.15.0/deployments/static/nvidia-device-plugin.yml설치 되었는지 확인
helm list -n nvidia-device-pluginDocker이미지에서 nvidia-smi가 잘 동작하는지 확인
sudo ctr image pull docker.io/nvidia/cuda:11.0.3-base-ubuntu20.04sudo ctr run --rm -t \
--runc-binary=/usr/bin/nvidia-container-runtime \
--env NVIDIA_VISIBLE_DEVICES=all \
docker.io/nvidia/cuda:11.0.3-base-ubuntu20.04 \
cuda-11.0.3-base-ubuntu20.04 nvidia-smi! Failed to initialize NVML: Unknown Error 오류가 나는 경우
sudo vim /etc/docker/daemon.json 아래처럼 exec-opts문구를 추가
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"exec-opts": ["native.cgroupdriver=cgroupfs"]
} 이후 설정파일 수정
sudo vim /etc/nvidia-container-runtime/config.tomlno-cgroups가 "true" 로 되어있다면 "false"로 변경해준 후 저장한다. 그 후 docker를 재시작해준다.
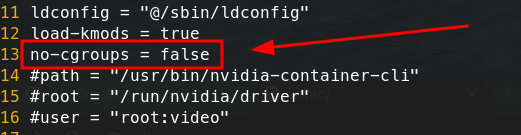
sudo systemctl restart docker다시 도커 명령어 실행하면 nivdia-smi가 잘 뜨는 것을 확인할 수 있다.
sudo ctr run --rm -t \
--runc-binary=/usr/bin/nvidia-container-runtime \
--env NVIDIA_VISIBLE_DEVICES=all \
docker.io/nvidia/cuda:11.0.3-base-ubuntu20.04 \
cuda-11.0.3-base-ubuntu20.04 nvidia-smi배포해보기
jj@jj-node1:~/workspace$ cat mnist.yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule블로그 같은 곳에 했던 걸 정리하기
- 안되는 gpu하나 살리기
- 오닉스 런타임 고치고
- 노드포트와 서비스에서 인그래스(로드벨런스) 쪽 개념 정리
Comment