
서론
스케줄러는 taints, tolerations, node affinity 등 다양한 조건을 고려하여 파드를 노드에 고르게 분산시키는 알고리즘을 사용한다.
그런데 나만의 스케줄링 알고리즘을 만들어 파드를 노드에 배치하고자 하려면 어떻게해야 할까?
사용자는 자신만의 스케줄러 프로그램을 작성하여, 이를 쿠버네티스 클러스터에 추가할 수 있다.
일부 애플리케이션들은 기본 스케줄러를 계속 사용할 수 있고, 특정 애플리케이션만 사용자 정의 스케줄러를 사용할 수 있다는 뜻이다.
즉, 쿠버네티스 클러스터는 동시에 여러 개의 스케줄러를 가질 수 있다.
참고로 기본 스케줄러의 이름은 default-scheduler이다.
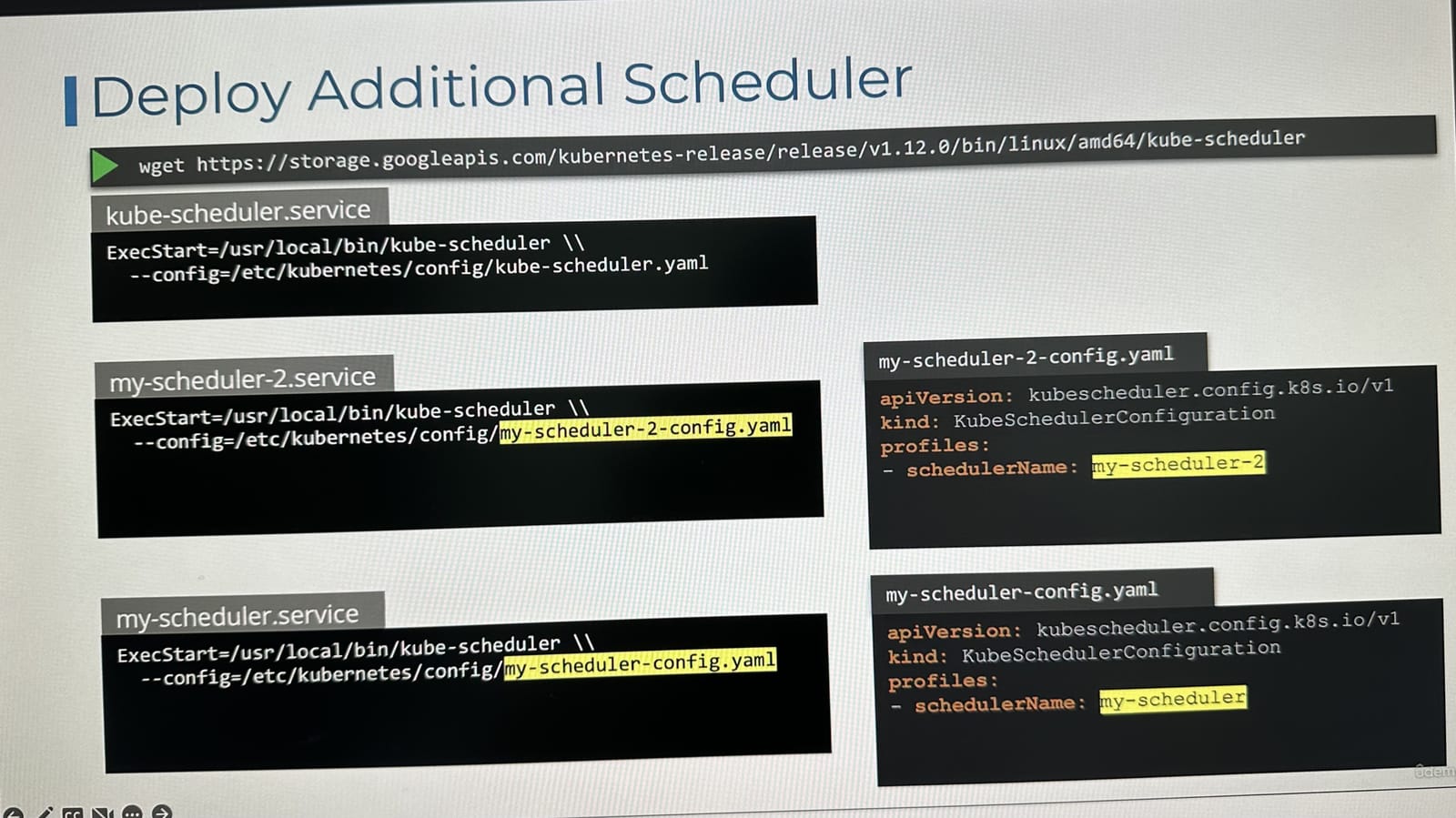
Binary 방식으로 스케줄러 설정하기
binary 파일을 다운받아 실행 옵션에 커스텀 스케줄러 설정파일 경로를 주어 사용자 정의 스케줄러를 사용할 수 있다.
그러나 요즘은 kubeadm으로 클러스터를 구성하여 control plane의 모든 구성요소들이 클러스터내 파드 또는 디플로이먼트 형태로 실행되어 별도의 실행파일(바이너리)을 통한 사용자 정의 스케줄링 방식은 잘 사용되지 않는다.
Kubeadm
그렇다면 자주 사용되는 파드형태로 사용자 스케줄러를 배포하는 방법에 대해 알아보자
- 스케줄러를 쿠버네티스에 파드(Pod) 형태로 띄우기 위해 파드 정의 파일을 작성한다.
- 사용자 정의 스케줄러를 만들기 위해
my-scheduler-config.yaml을 작성한다. - 스케줄러가 쿠버네티스 API 서버에 접근할 수 있도록
kubeconfig옵션에 인증 정보가 담긴 파일 경로를 입력해줘야 한다.
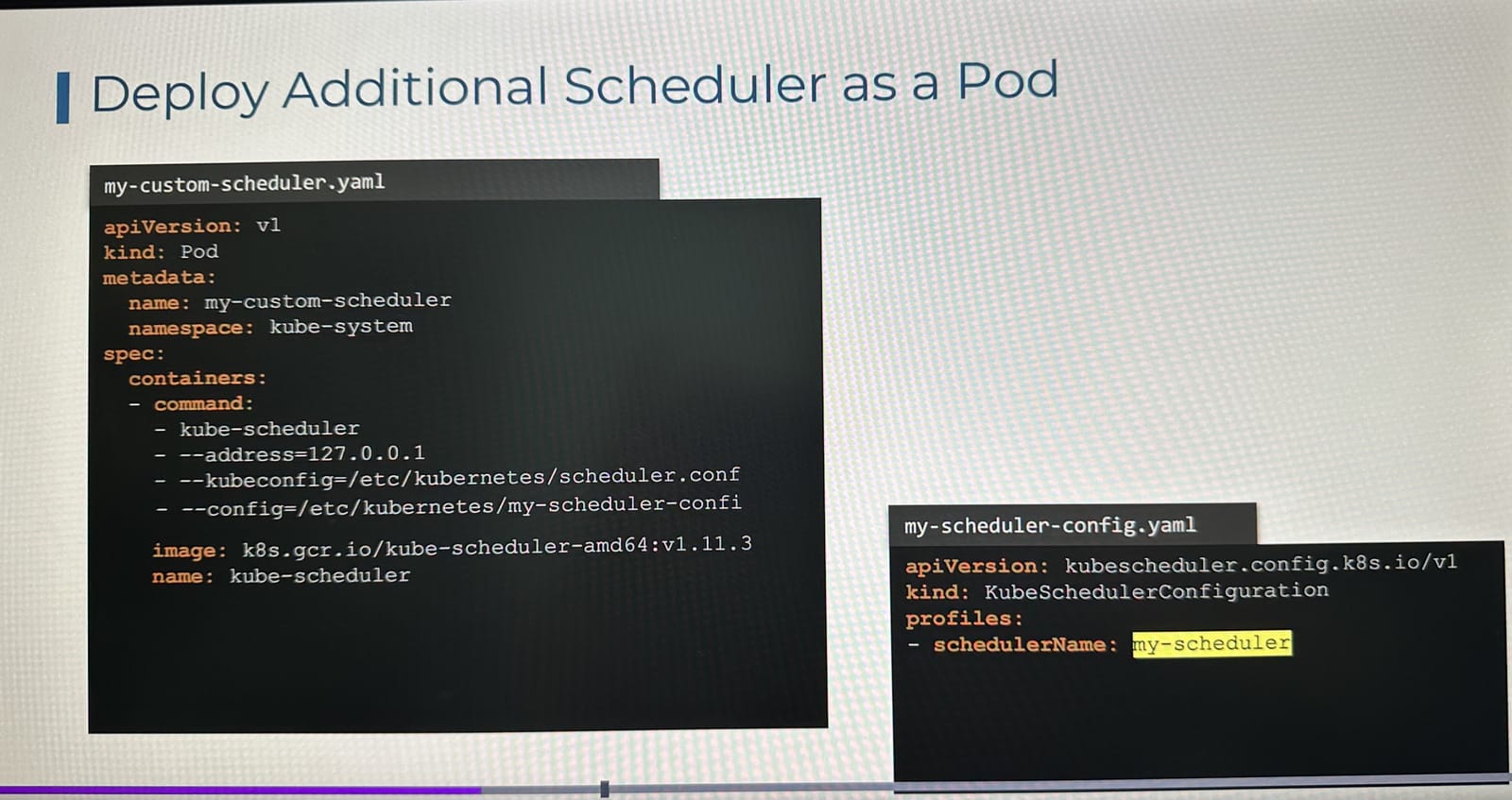
- 그 다음 사용자 kube-scheduler 설정 파일인 my-scheduler-config.yaml를 my-custom-scheduler.yaml에 config옵션에 넣어줘야한다.
- 그리고 해당 경로에
my-scheduler-config.yaml넣고 볼륨을 만들어my-custom-scheduler.yaml파일에 마운트 시켜주어 설정파일을 전달해준다. - 이를 통해
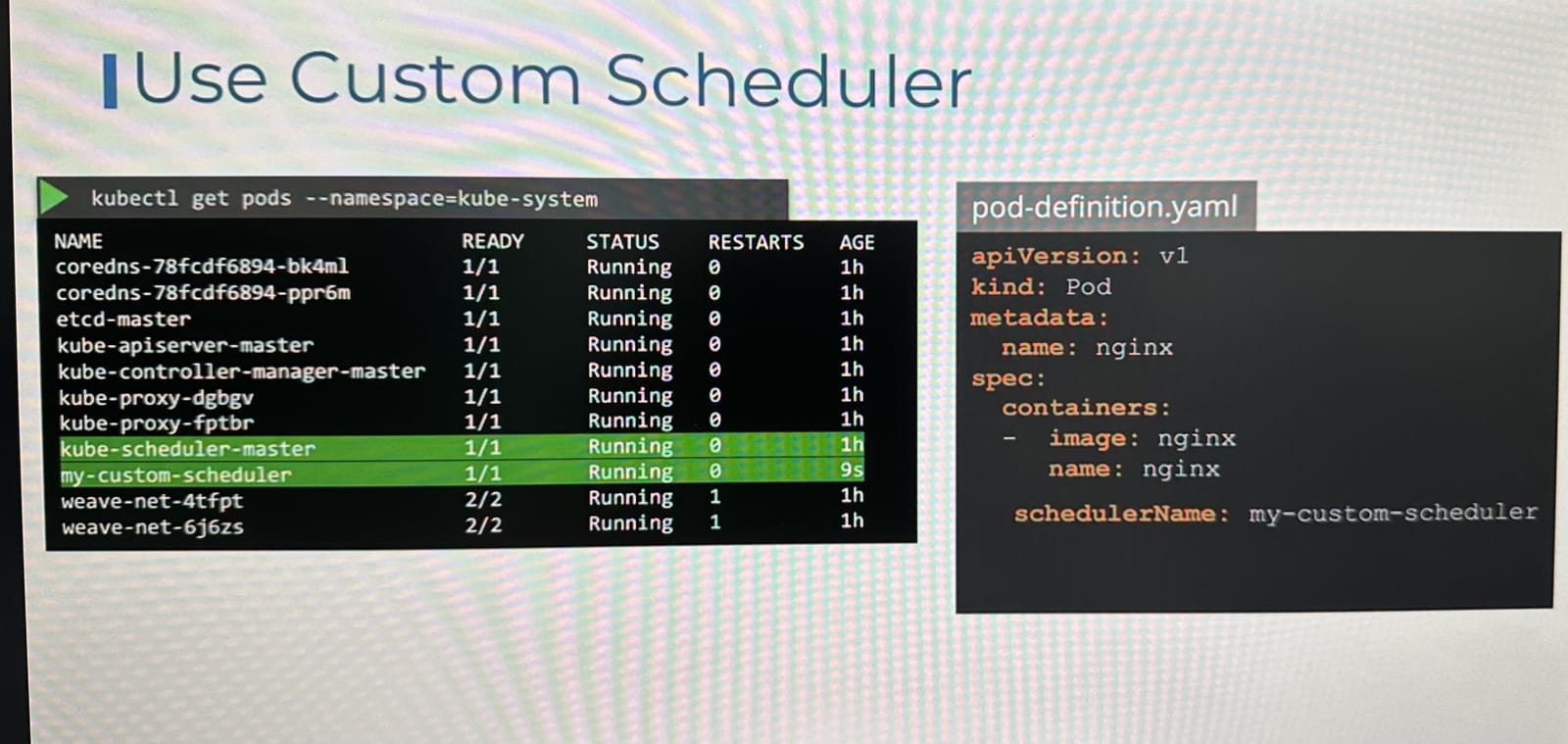
schedulerName: my-custom-scheduler로 지정된 Pod들은 사용자 정의 스케줄러가 스케줄링하게 된다.
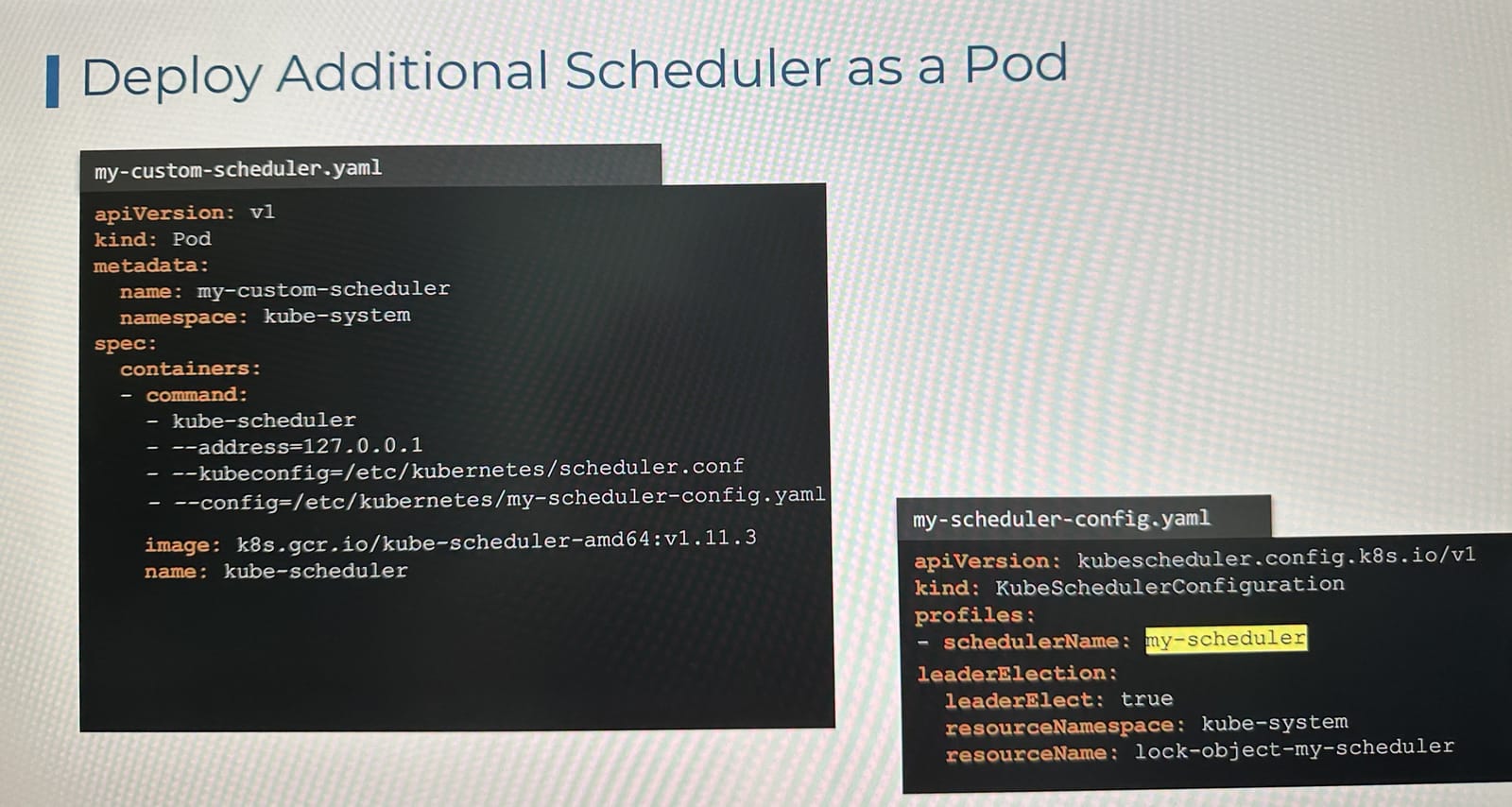
LeaderElection 옵션
- leaderElect 옵션은 여러 마스터 노드에서 스케줄러가 중복 실행될 때 사용된다.
- 스케줄러가 여러 개가 동시에 같은 작업을 하면 충돌이 생기기 때문에 설정해주어 충돌을 막는다
- 그래서
leaderElect: true를 설정하면, 여러 스케줄러가 여러 노드에서 동시에 실행 중이라면, 오직 하나만 활성 상태가 될 수 있다. 쉽게말해 락을 건다고 보면 된다. --leader-elect=true와 함께--lock-object-name=<이름>을 주면 “같은 lock-object-name을 가진 스케줄러 인스턴스끼리만” 리더 선출(락 경쟁)을 한다.
- 그리고 ServiceAccount, ClusterRole, ClusterRoleBinding 설정을 해주고 배포하면 된다.
- 커스텀 스케줄러가 Kubernetes API Server와 통신하고, 스케줄링 관련 리소스를 읽고 조작할 수 있는 권한을 가지게 해주기 위함
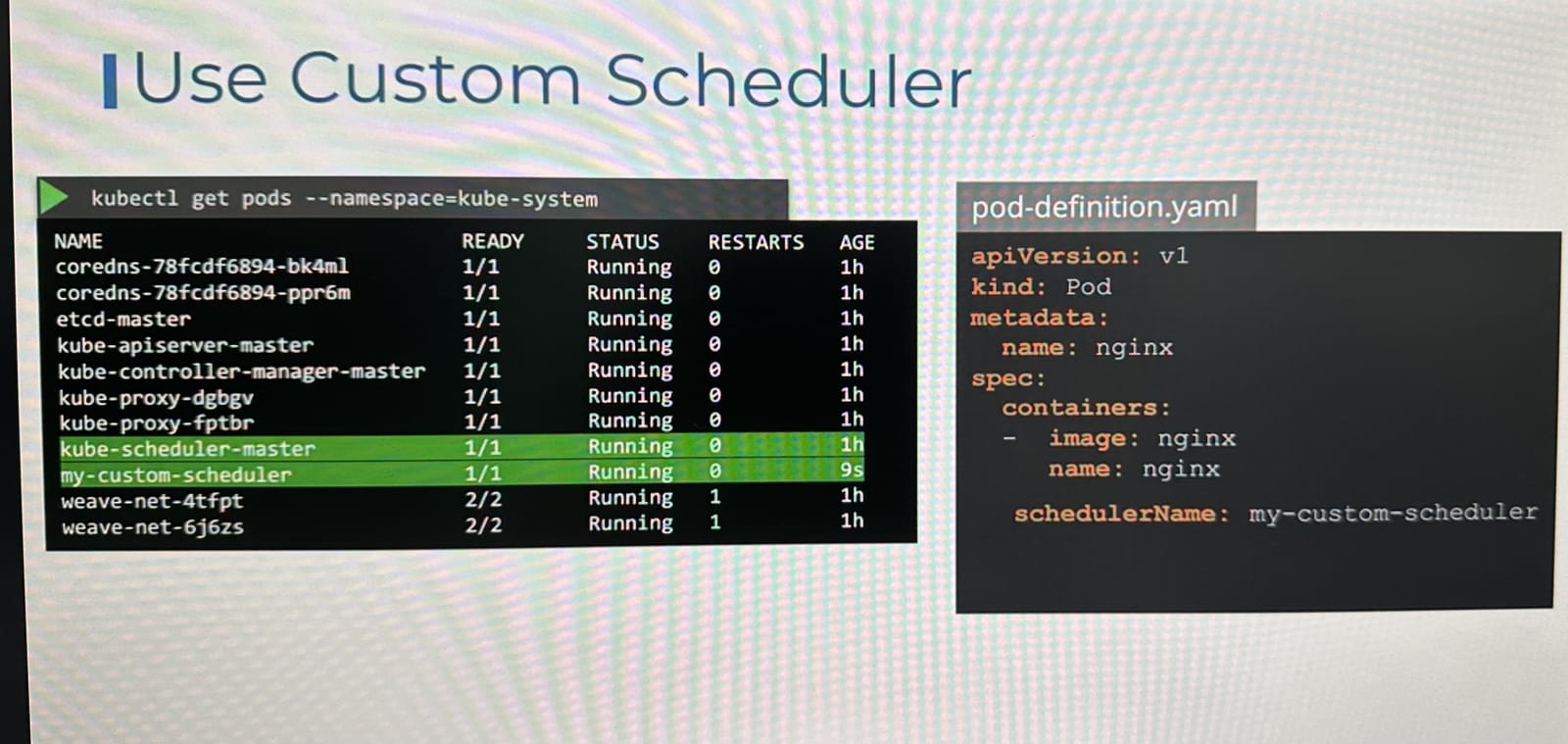
- 이후 생성할 파드에서 사용자 정의 스케줄러를 사용하고싶다면 아래 그림과 같이
schedulerName필드에 이름을 넣어서 사용할 수 있다. - 만약 스케줄러가 올바르게 설정되지 않았다면, 해당 Pod는 계속해서 Pending 상태로 남게된다.
그렇다면 어떤 스케줄러가 이 Pod를 스케줄링했는지 어떻게 알 수 있을까?
아래 명령어를 통해 알 수 있으며 SOURCE 영역부분이 해당 스케줄러가 된다.
kubectl get events -o wide
그리고 스케줄러에 문제개 생겼을 경우 로그를 확인하는 방법이다.
kubectl logs <my-scheduler> --name-space=kube-system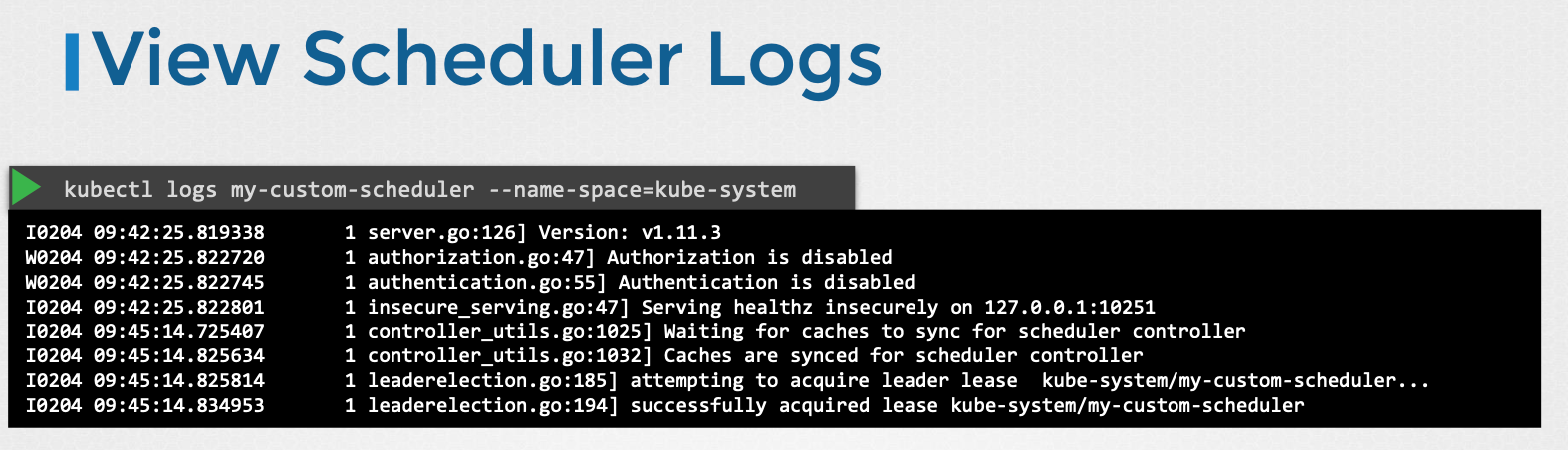
쿠버네티스 스케줄링 상세 동작방식
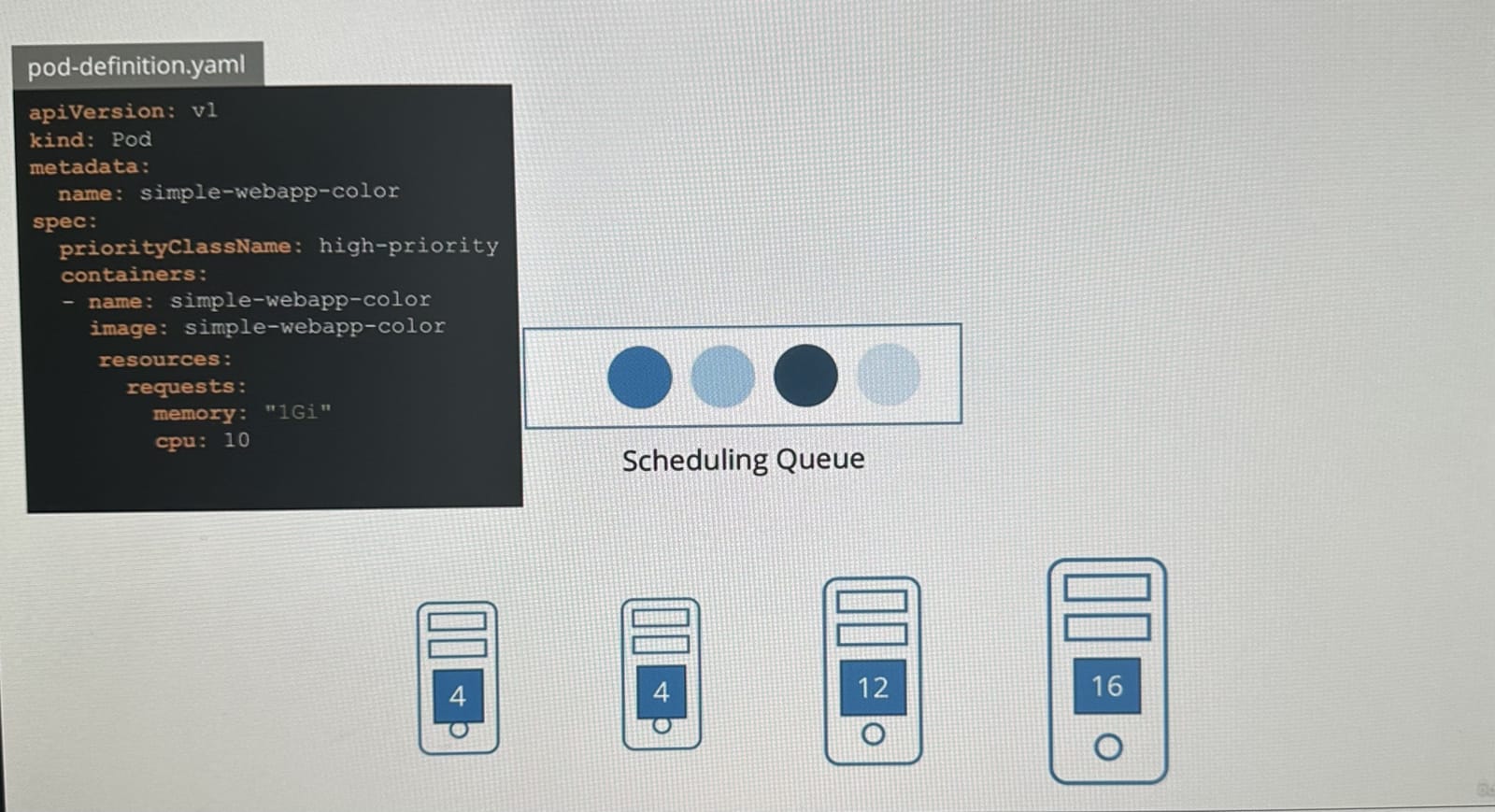
노드는 총 4개가 존재하며, 우리가 파드A를 추가로 하나 만들었다 하자.
파드A는 10개의 CPU를 요구하기 때문에, 남은 CPU가 10개 이상인 노드에만 스케줄링될 수 있으며
파드A뿐만 아니라 다른 파드들도 스케줄링 큐에서 스케줄링되길 기다리고 있다.
이 큐에서는 파드들이 정의된 우선순위에 따라 스케줄링되기를 기다리며 이 예시에서는 파드가 높은 우선순위를 가지고 있다고 가정하자.
우선순위를 설정하려면 Pod-definition.yaml에서 보이는 PriorityClass를 생성해야 하며, 이름과 우선순위 값을 설정해야 한다.
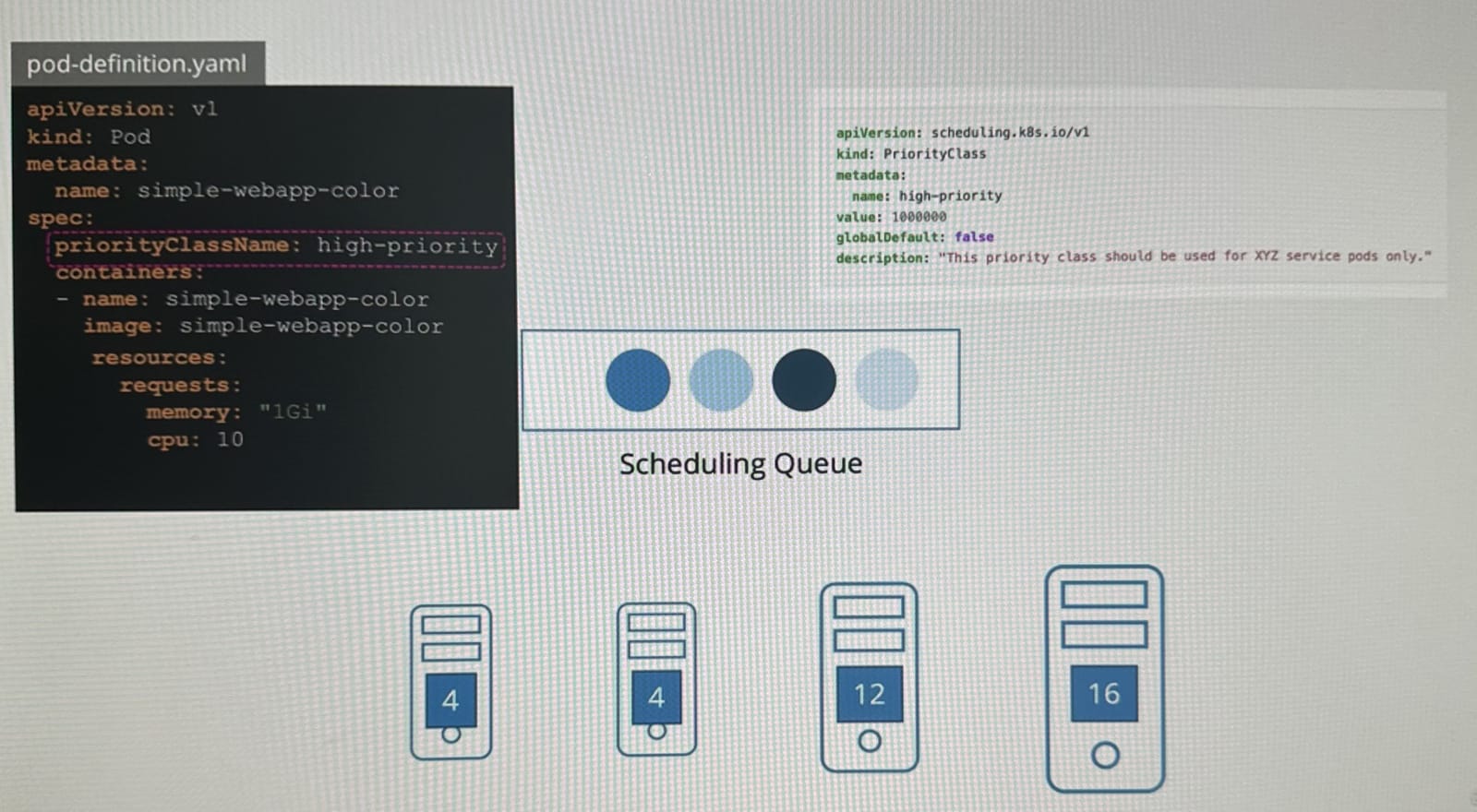
위 처럼 클래스를 생성해주고 1,000,000 우선순위를 부여했다.
높은 우선순위를 가진 파드가 큐의 앞쪽에 배치되어 먼저 스케줄링되게 된다.
이 정렬 과정은 1. 스케줄링 단계에서 일어난다.
그 다음, 실행할 수 없는 노드들이 걸러지는 2. 필터링 단계로 넘어간다.
위 예시에서는 첫 두 노드가 CPU 자원 10개를 제공할 수 없기 때문에 필터링된다.
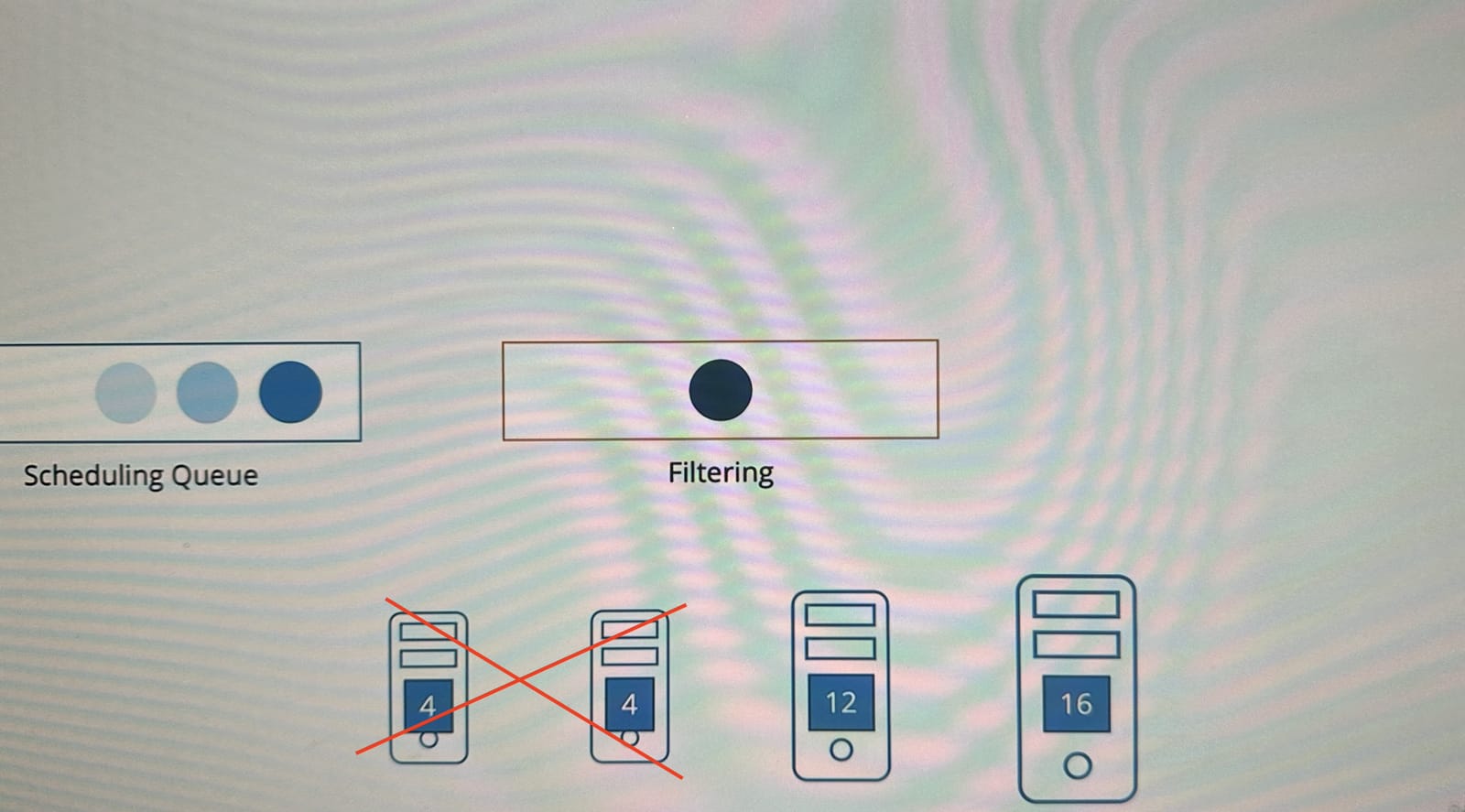
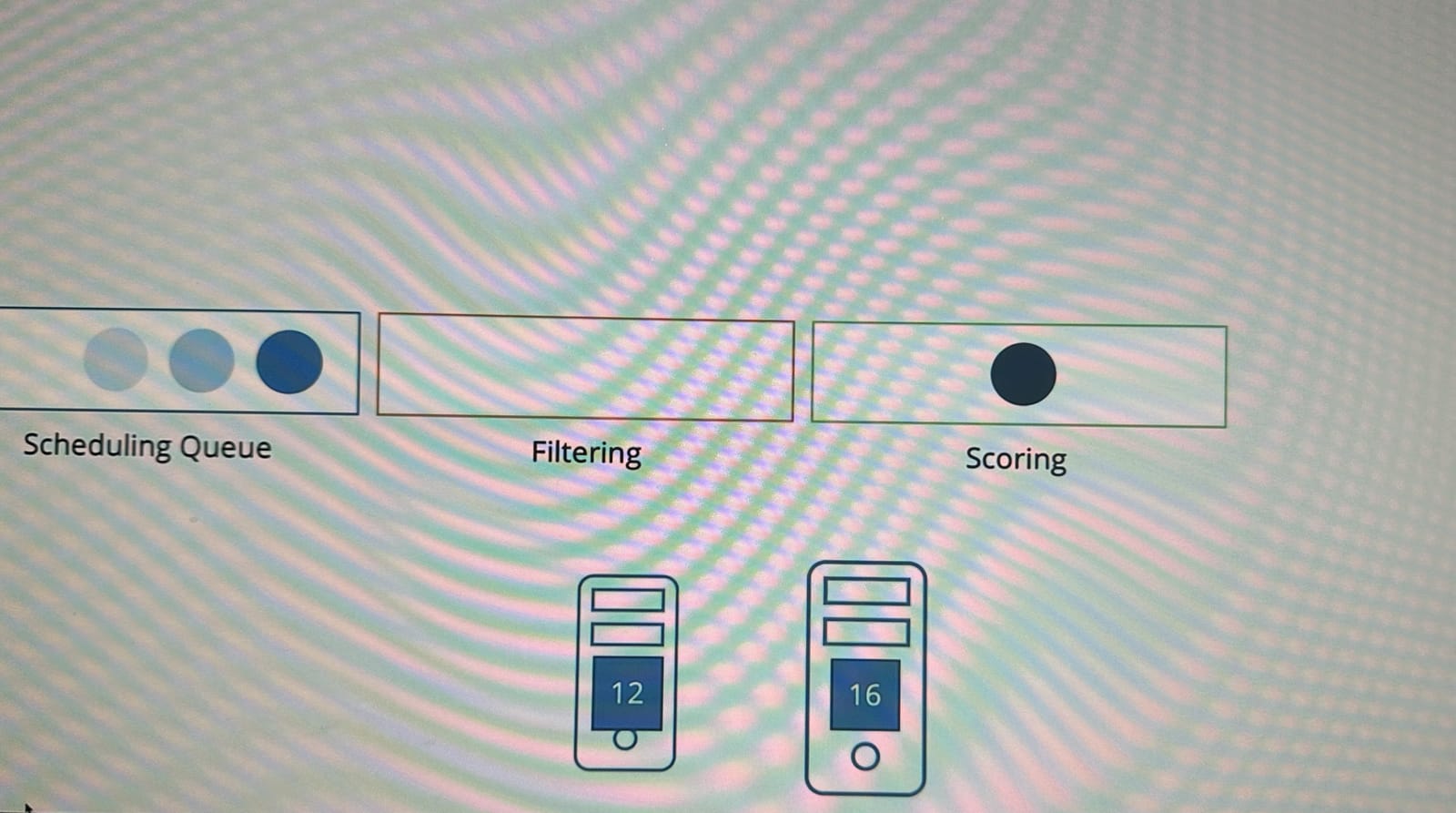
다음 단계는 3. 스코어링(점수 부여) 단계이다.
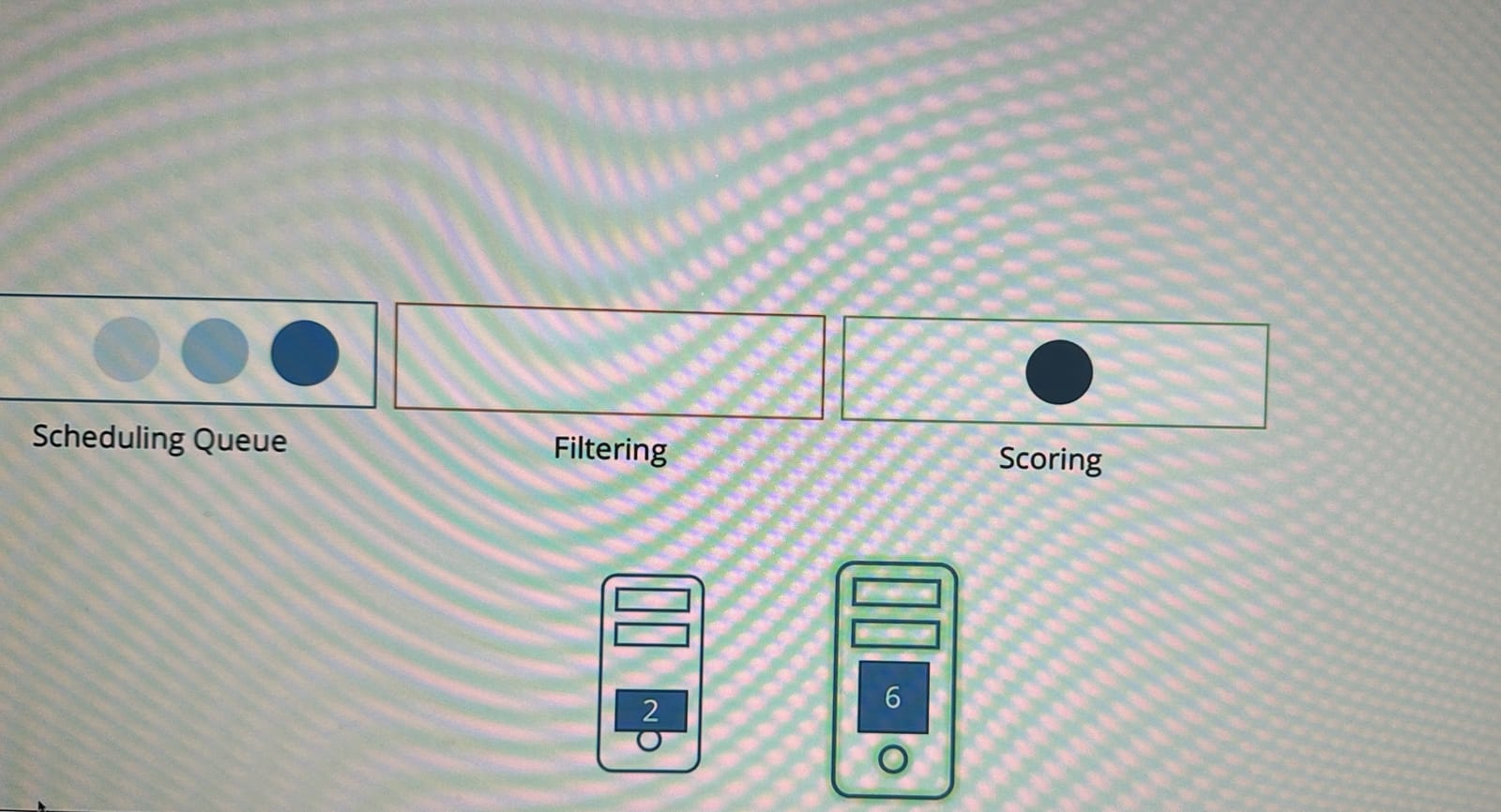
이 단계는 남은 두 노드에 대해, 스케줄러가 파드가 요구하는 CPU를 할당한 후 남은 자원을 기준으로 각 노드에 점수를 부여한다.
이 예시에는 첫 번째 노드는 2개의 CPU가 남고, 두 번째 노드는 6개가 남기 때문에 두 번째 노드가 더 높은 점수를 받아 이 노드가 선택된다.
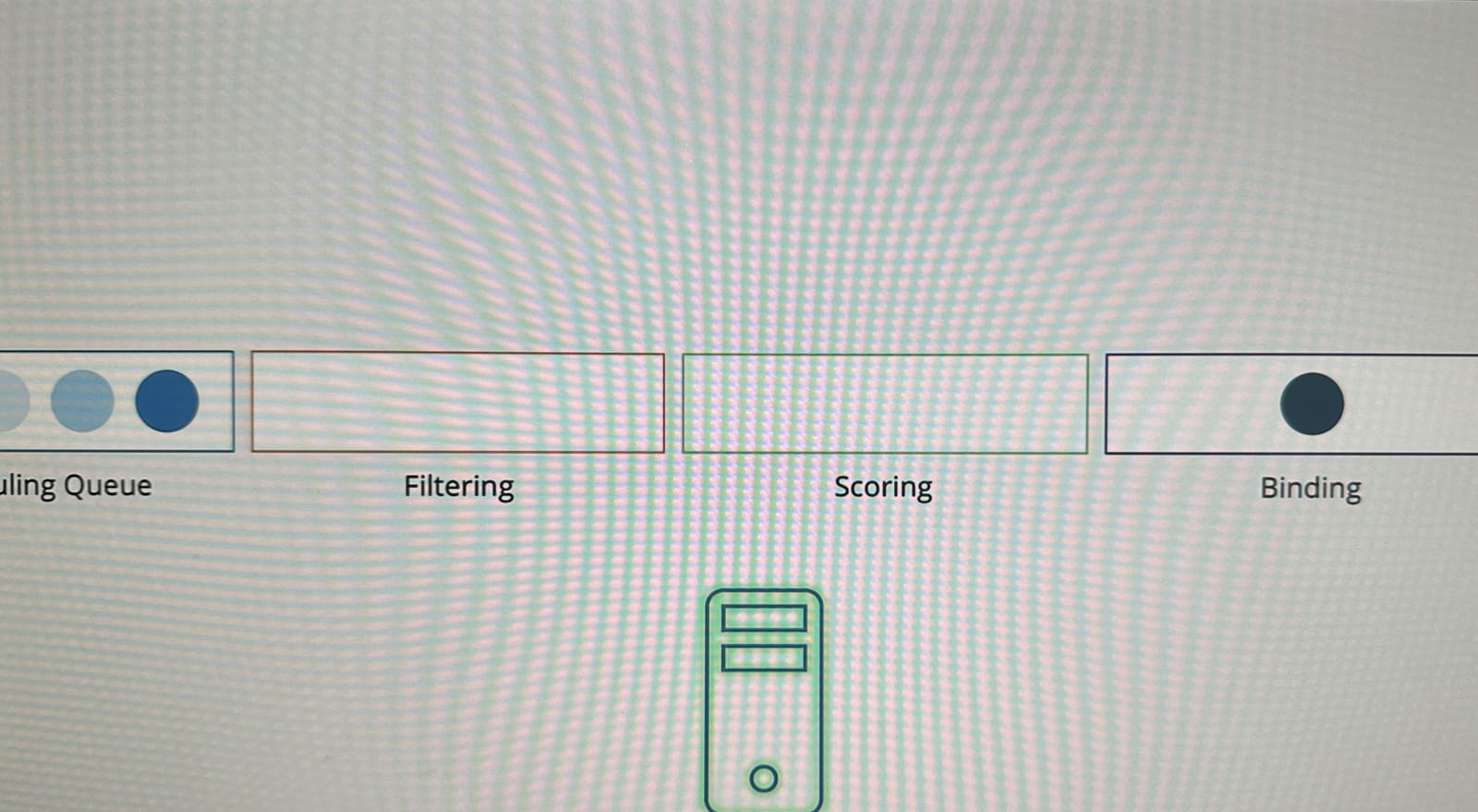
다음 단계는 4. 바인딩 단계이다.
여기서 파드는 최종적으로 가장 높은 점수를 받은 노드에 바인딩 된다.
이러한 모든 작업들은 특정 플러그인들에 의해 수행된다.
예를들어,
- 스케줄링 큐
-
priorty sort라는 플러그인에 의해 파드를 정렬한다.
-
- 필터링 단계
node resource fit플러그인이 노드가 충분한 자원을 가지고 있는지 식별하고 자원이 부족한 노드는 필터링한다.node name플러그인은 파드에 특정 노드 이름이 설정되어 있는지 확인하고 일치하지 않는 노드들은 필터링한다.Node unschedulable플러그인은 unschedulable 플래그가 true로 설정된 노드를 필터링한다.
- 스코어링 단계
node resources fit플러그인이 각 노드에 점수를 할당합니다image locality플러그인은 배포될 파드가 사용하는 컨테이너 이미지가 이미 존재하는 노드에 대해 높은 점수를 준다.
- 바인딩 단계
defaultBinder플러그인이 파드를 실제로 노드에 바인딩하는 역할을 한다.
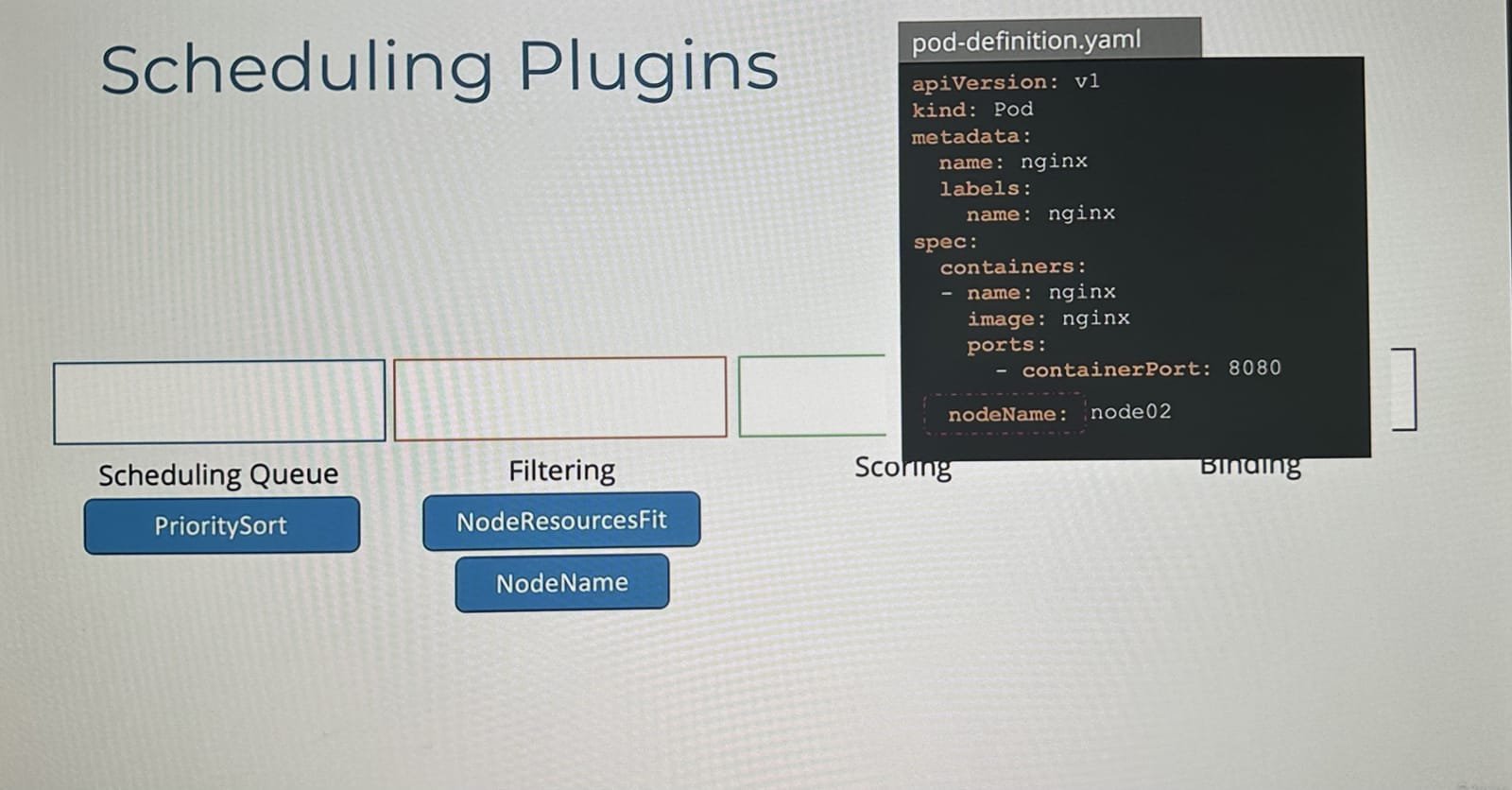

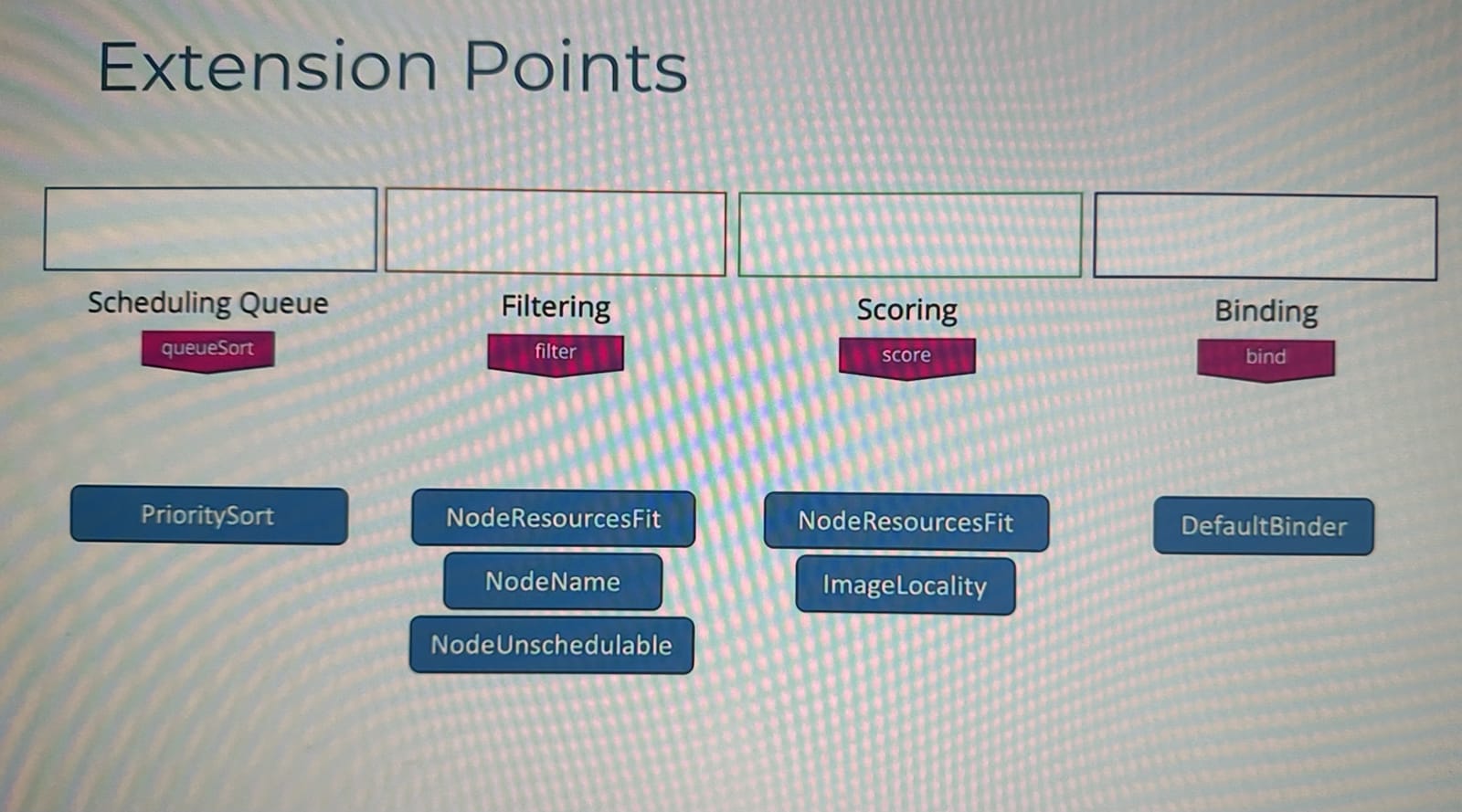
Kubernetes에서는 위와 같은 플러그인들을 어떤 플러그인을 어디에 사용할지 또는 직접 플러그인을 작성해서 연결할 수도 있다.
각 스케줄링 단계에서 extension point 지점에 플러그인을 연결하여 동작을 커스터마이징 할 수 있다.
- 예) 스케줄링 큐: queue sort라는 Extension point가 있고 여기에 priority sort 플러그인이 연결되어있다.
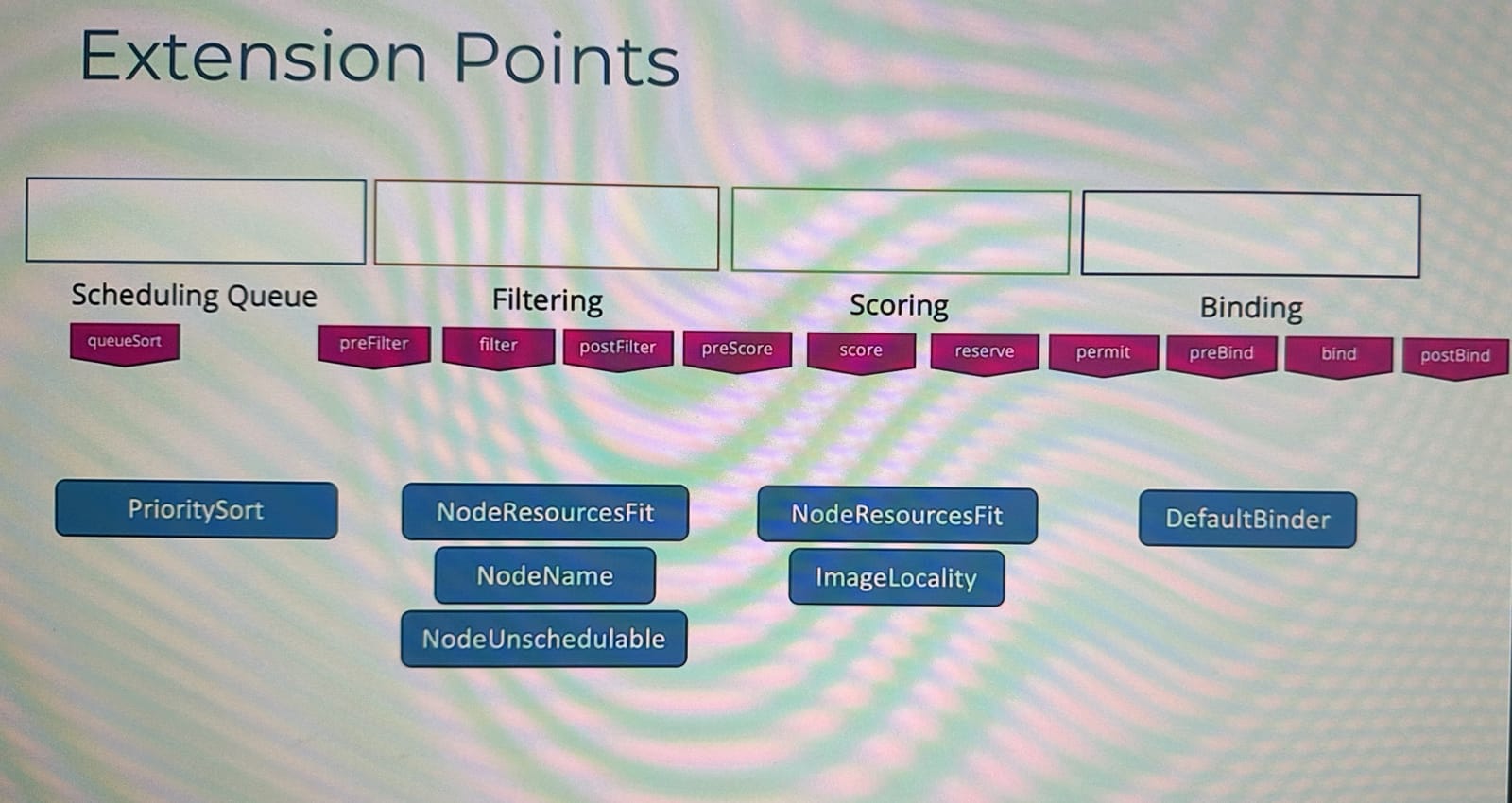
또한 위의 Extension Point외에도 실제로는 각 단계의 앞뒤로 더 많은 포인트가 존재한다.
따라서 플러그인을 만들어서 원하는 지점에 연결하여 사용할 수 있다.
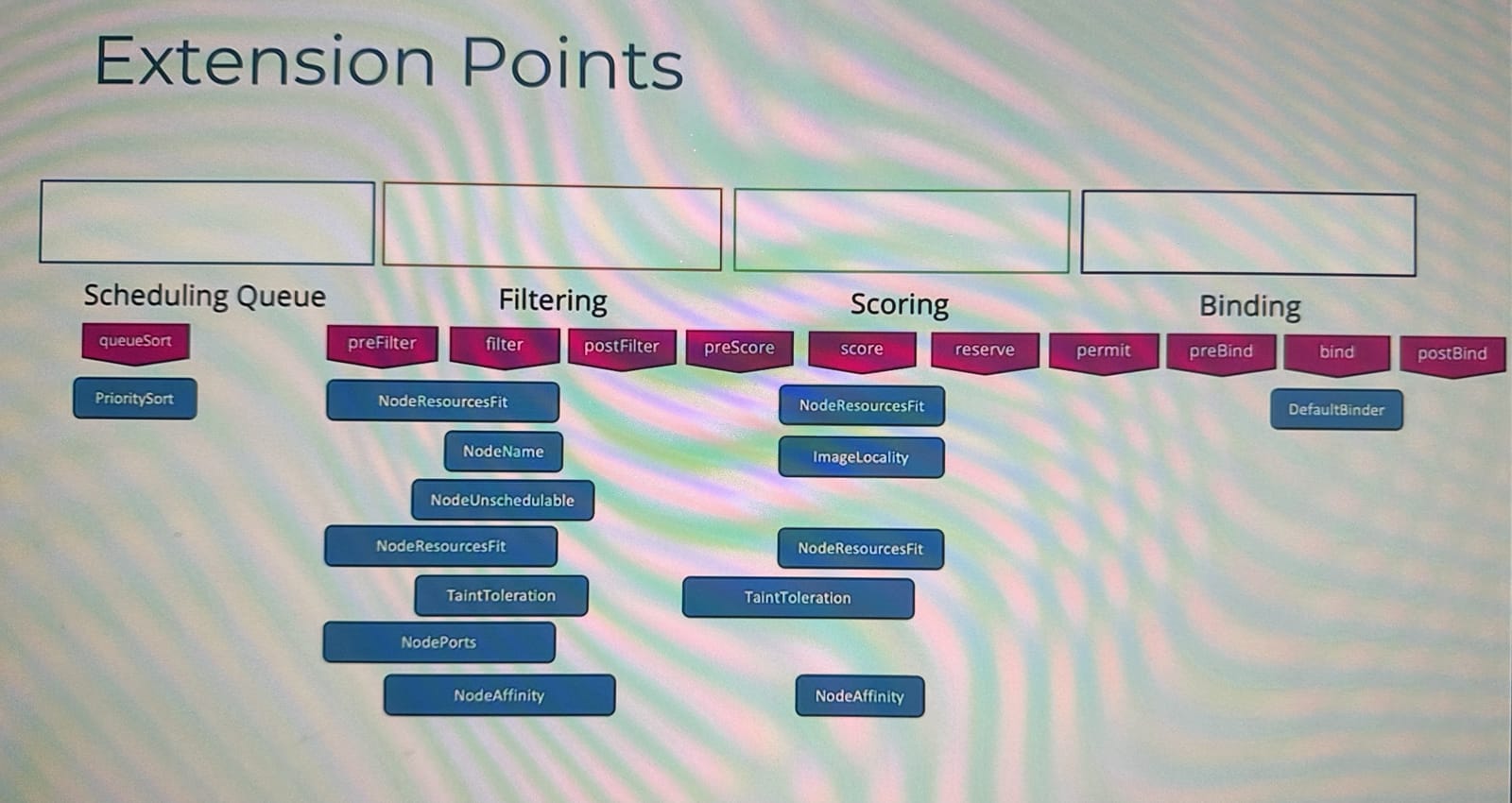
일부 플러그인들은 여러 단계를 연속적으로 할당하기도하며 일부 플러그인은 특정 Extension Point에서만 동작한다.
Configuring Scheduler Profiles
- 과거 Kubernetes에서는 여러 개의 스케줄러를 생성할 때, 각 스케줄러마다 별도의 설정 파일을 사용하고 독립적으로 관리하였다.
- 하지만 이 방식은 스케줄러마다 별도의 프로세스가 생성되어 실행되어 동일한 노드에 대해 동시에 스케줄링을 시도할 경우 race condition이 발생할 수 있다.
Kubernetes 내부적으로 스케줄러 하나당 하나의 프로세스가 할당

- 쿠버네티스(1.18+ 이후)는 단일 스케줄러 인스턴스에 여러 프로필을 지원하도록 하여 여러 스케줄러를 하나의 설정 파일에서 관리가 가능하다.
- 이 방식은 하나의 프로세스내에서 여러 스케줄러가 동작하게된다.
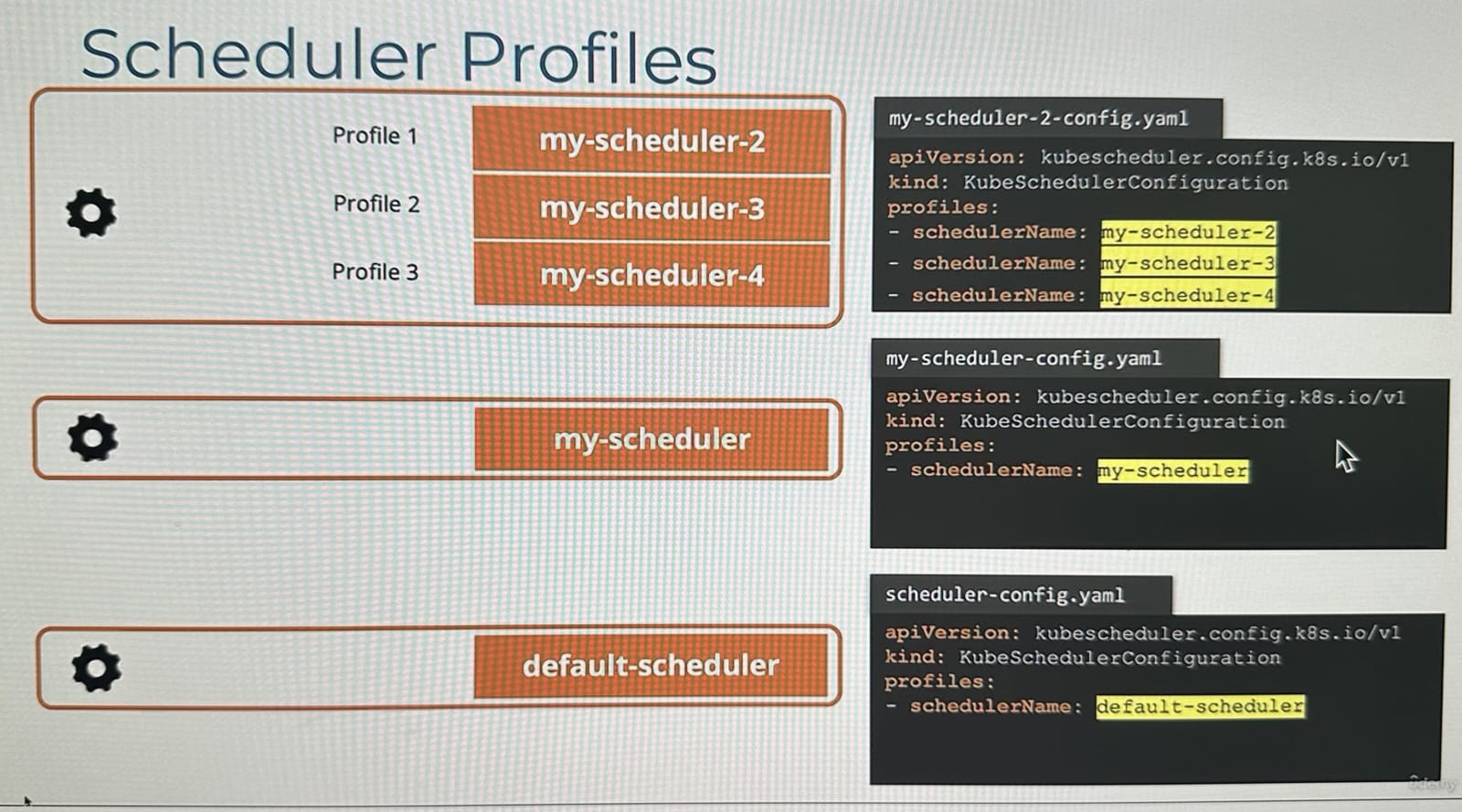
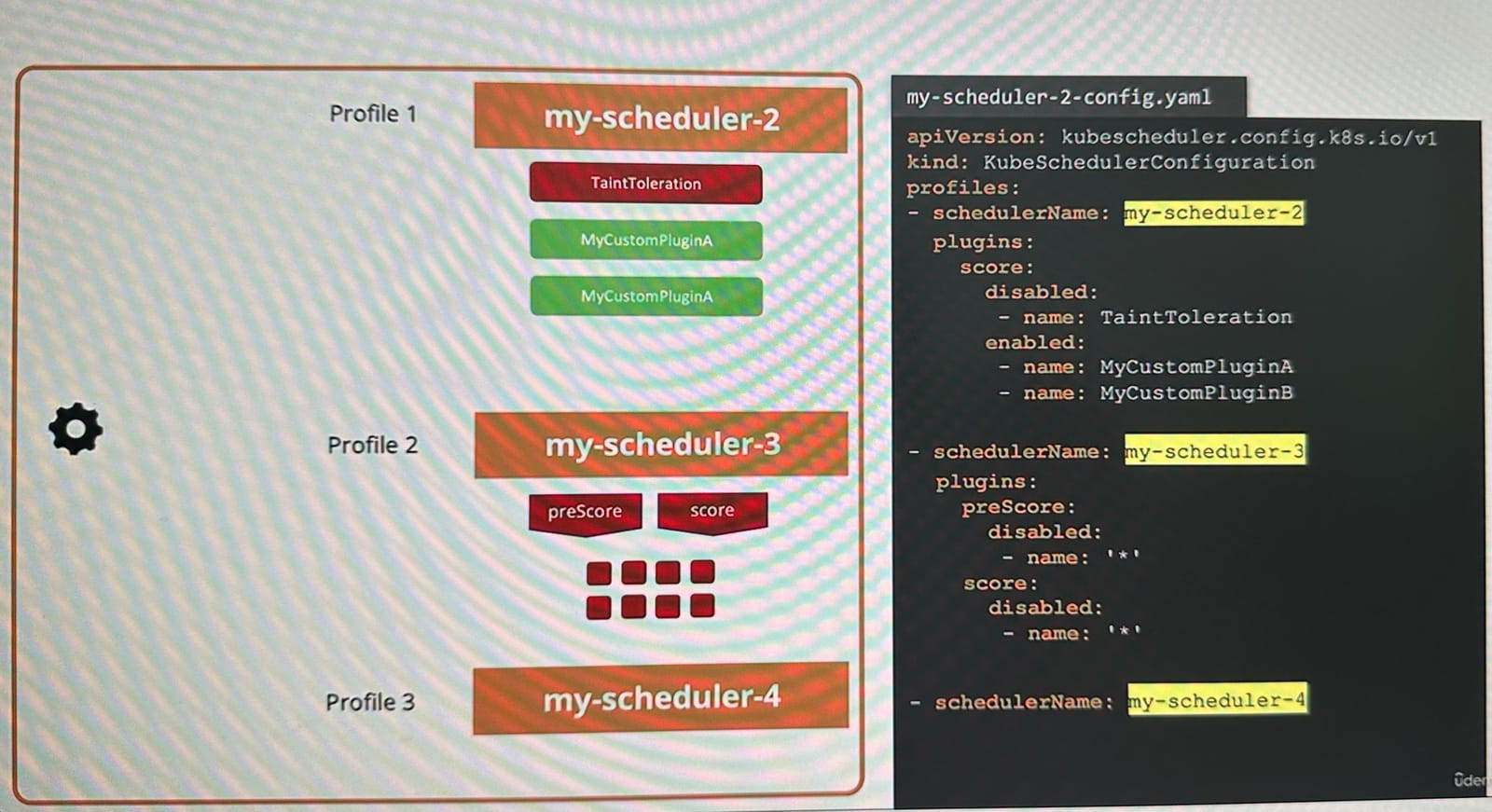
다중 스케줄러를 아래 처럼 구성하게 되면 하나의 실행파일안에서 여러 스케줄러를 관리할 수 있게 된다.
예를들어 my-scheduler-2 프로파일에서는 TaintToleration 플러그인은 비활성화하고 사용자 정의 플러그인을 활성화 할 수 있다.
my-scheduler-3 프로파일의 경우에는, preScore와 score 단계에 있는 모든 플러그인들을 비활성화할 수도 있다.
Comment