
서론
On premise 환경에서 Kubernetes를 사용해 Mnist model을 GPU에 올려 추론 결과까지 출력하는 것을 목표로 한다.
이때 클라이언트는 노드 포트를 사용해 서버에 접속하여 API 요청을 하고 결과를 얻는다.
동작 순서는 아래와 같다.
- 간단한 모델을 구한다.
- 로컬에서 Fast API를 가지고 모델을 GPU에 올리고 배포한다.
- 클라이언트에서 API요청을 통해 결과값을 가져오고 GPU를 모니터링 한다.
- 1 ~ 3번이 잘 진행되었다면 DockerFile을 만들어 이미지로 패키징한다.
- Private registry를 사용하여 이미지를 빌드 및 푸쉬한다.
- Deployment를 작성하고 서비스는 NodePort를 사용한다.
- K8s를 통해 모델을 배포한다.
- 배포된 노드에 접속하여 GPU를 모니터링한다.
Spec
(Node1) GPU: rtx2060 | Master & Worker
(Node2) GPU: rtx A5000 | Worker
(Node3) GPU: X | Worker
Pre-installation
K8s는 설치되어 있다고 가정한다.
- Nvidia Driver 설치
- Nvidia-smi로 CUDA Version확인
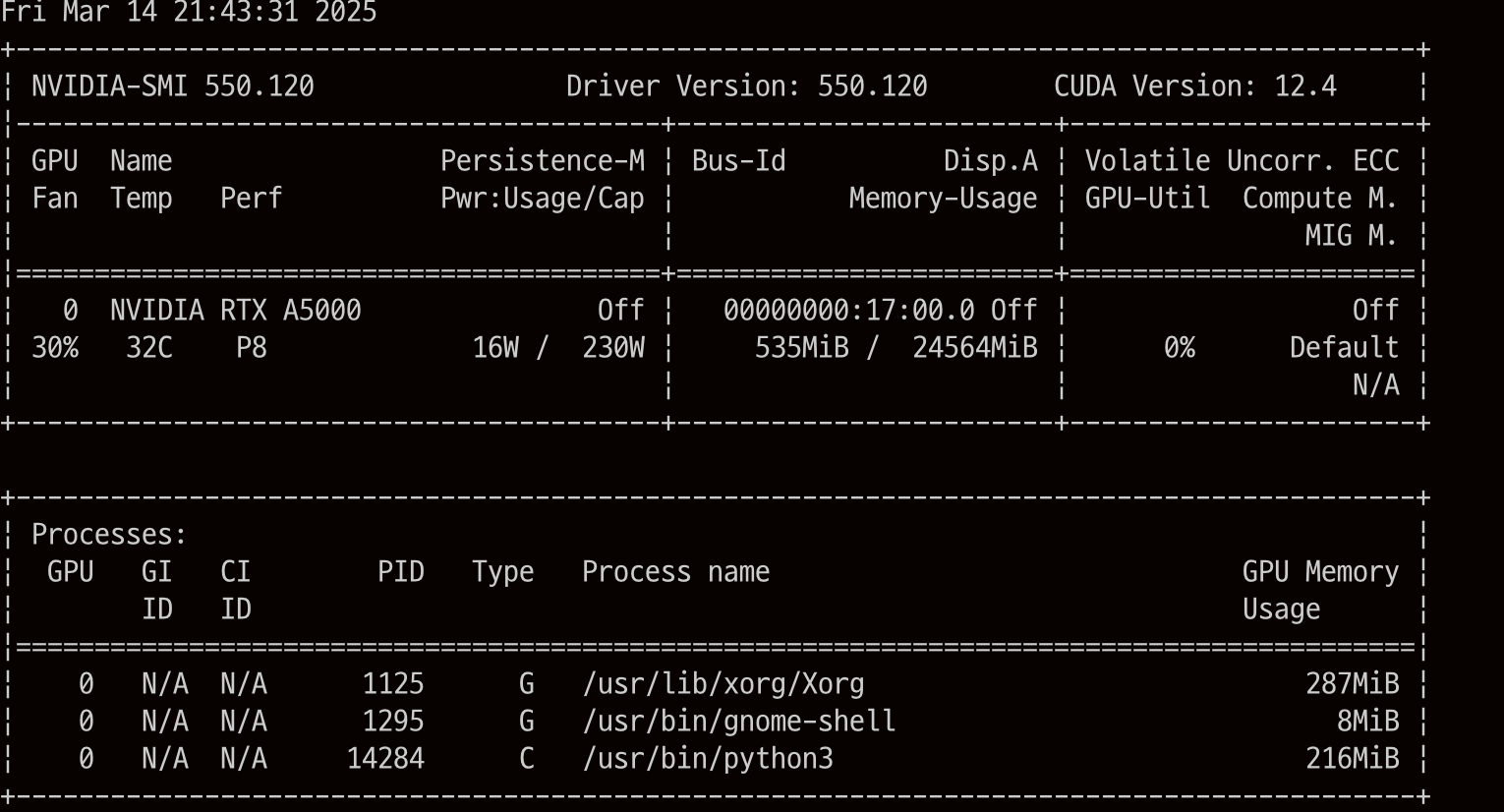
- K8s에 Nvidia GPU Plugin을 설치한다.
- ONNXRuntime-GPU을 설치한다.
- 설치방법:
pip3 install onnxruntime-gpu==1.19.2 - CUDA 버전과 종속성을 확인: https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html
- 설치방법:
- Cuda toolkit을 설치한다. (
- CuDNN을 설치한다.
- 설치방법: https://developer.nvidia.com/cudnn-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_network
- 설치 후 환경변수 설정
export PATH=/usr/local/cuda-12.4/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
Serving
DockerFile Packaging
- FastAPI를 활용한 ONNX Runtime 배포 코드 작성
Code
from fastapi import FastAPI, File, UploadFile import onnxruntime as ort import numpy as np import cv2 from PIL import Image import io import logging import time import os import logging log_dir = "logs" if not os.path.exists(log_dir): os.makedirs(log_dir, exist_ok=True) os.chmod(log_dir, 0o777) log_file = os.path.join(log_dir, "server.log") logging.basicConfig( level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s", handlers=[ logging.FileHandler(log_file, mode="a"), logging.StreamHandler() ], ) logger = logging.getLogger(__name__) app = FastAPI() providers = [] onnx_model_path = "./mnist-12.onnx" # ONNX model load for gpu logger.info(f"Loading ONNX model from {onnx_model_path}") available_providers = ort.get_available_providers() providers = ["CUDAExecutionProvider"] logger.info(f"ONNX model loaded successfully with providers: {providers}") session = ort.InferenceSession(onnx_model_path, providers=providers) # MNIST preprocess def preprocess_image(image_bytes): logger.info("Preprocessing input image...") start_time = time.time() image = Image.open(io.BytesIO(image_bytes)).convert("L") image = image.resize((28, 28)) image_np = np.array(image, dtype=np.float32) / 255.0 image_np = image_np.reshape(1, 1, 28, 28) # (b, c, h, w) elapsed_time = time.time() - start_time logger.info(f"Preprocessing completed in {elapsed_time:.4f} seconds.") return image_np @app.get("/health") async def health_check(): return {"status": "healthy"} @app.post("/predict/") async def predict(file: UploadFile = File(...)): logger.info(f"Received file: {file.filename}") image_bytes = await file.read() input_tensor = preprocess_image(image_bytes) # inference input_name = session.get_inputs()[0].name output_name = session.get_outputs()[0].name logger.info("Running inference on the model...") start_time = time.time() outputs = session.run([output_name], {input_name: input_tensor}) inference_time = time.time() - start_time logger.info(f"Inference completed in {inference_time:.4f} seconds.") prediction = np.argmax(outputs[0]) logger.info(f"Predicted class: {prediction}") return {"prediction": int(prediction), "inference_time": round(inference_time, 4)} if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000) requirments.txt작성Code
fastapi uvicorn onnxruntime-gpu==1.19.2 pillow numpy opencv-python python-multipart- DockerFIle 작성
Code
# CUDA 12.4 + Python 3.10 기반 이미지 사용 FROM nvidia/cuda:12.4.0-runtime-ubuntu22.04 WORKDIR /app RUN apt-get update && apt-get install -y \ python3.10 \ python3-pip \ libgl1 \ libglib2.0-0 \ wget RUN ln -s /usr/bin/python3.10 /usr/bin/python COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY mnist.py . COPY mnist-12.onnx . RUN mkdir -p logs && chmod 777 logs RUN wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb && \ dpkg -i cuda-keyring_1.1-1_all.deb && \ apt-get update && \ apt-get -y install cuda-toolkit-12-8 && \ apt-get -y install cudnn ENV CUDA_VISIBLE_DEVICES=0 ENV PATH=/usr/local/cuda-12.4/bin:$PATH ENV LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH EXPOSE 8000 CMD ["uvicorn", "mnist:app", "--host", "0.0.0.0", "--port", "8000"] - Docker Private Registry 구축
Code
sudo docker run -d -p 5000:5000 --restart=always --name registry registry:2 - DockerFile 배포
Code
docker build -t mnist-serving:0.5 . sudo docker tag mnist-serving:0.6 localhost:5000/mnist-serving: 0.6 sudo docker push localhost:5000/mnist-serving:0.6
K8s
- Deployments.yaml (Replicaset: 2)
Code
# mnist-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: mnist-serving spec: replicas: 2 selector: matchLabels: app: mnist-serving template: metadata: labels: app: mnist-serving spec: containers: - name: mnist-container image: 192.168.0.32:5000/mnist-serving:0.6 imagePullPolicy: Always ports: - containerPort: 8000 resources: limits: memory: "512Mi" cpu: "500m" nvidia.com/gpu: 1 volumeMounts: - name: logs-volume mountPath: /app/logs tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule volumes: - name: logs-volume hostPath: path: /var/log/mnist-serving type: DirectoryOrCreate - Service.yaml
Code
# mnist_service.yaml apiVersion: v1 kind: Service metadata: name: mnist-service spec: type: NodePort selector: app: mnist-serving ports: - protocol: TCP port: 80 targetPort: 8000 nodePort: 30080 - 실행확인하면 두개의 노드에 잘 배포된 것을 볼 수 있다.
kubectl apply -f mnist_deployment.yaml
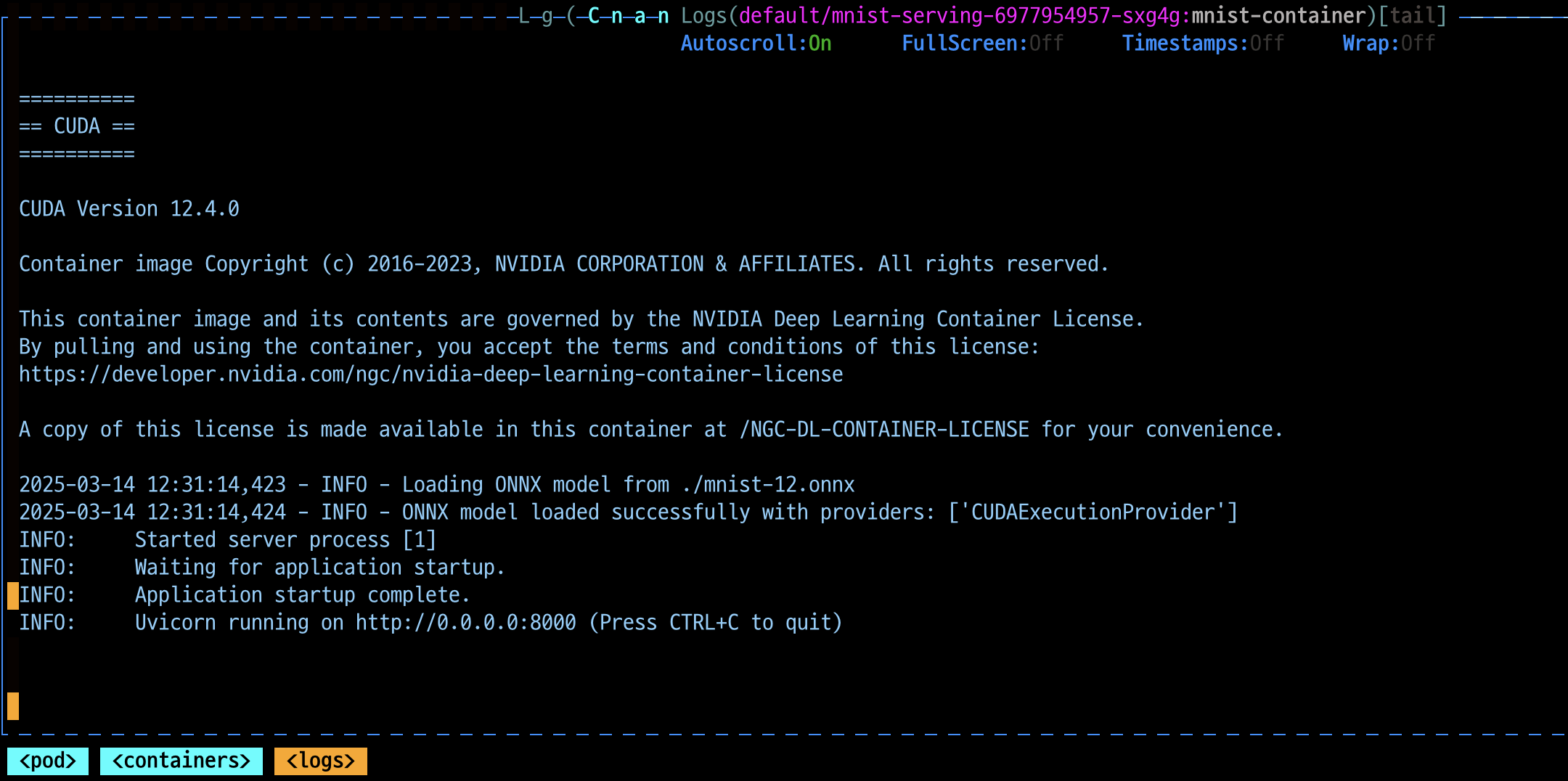
- 노드하나에 쉘로 접속해서 GPU사용율을 확인해 GPU를 사용하는지 확인
Comment