
서론
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1-9,
"Going Deeper with Convolutions (Inception v1)” - 2015년도에 CVPR에 출간된 논문으로 GoogleLeNet이라고도 불리는 InceptionNet에 대해서 설명합니다.
목차
- Abstract
- Introduction, Related Work, Motivation and High Level Considerations
- Architectural Details
- Auxiliary Classifier
- Inception v1 Code Review
- Inception v2
- Grid Size Reduction
- Inception v3
- Tensor Factorization
Abstract
- 본 논문에서 제안하는 모델 구조는 computational budget은 일정하게 유지하면서 network의 depth와 width를 증가시켰다.
- 이 아키텍처의 주요 특징은 네트워크 안에서 컴퓨팅 리소스의 활용을 향상시켰다는 점이다.
- GooLeNet이라고도 불리우는 LSVRC14에서 우리가 제안한 모델은 22 layers가진 deep network로classification과 detection의 두 가지 관점에서 평가되었다.
Introduction, Related Work, Motivation and High Level Considerations
background Research
In the last three years, mainly due to the advances of deep learning, more concretely convolutional networks the quality of image recognition and object detection has been progressing at a dramatic pace.
- 최근 3년동안 깊고 넓은 네트워크 들이 등장하면서 급격한 딥러닝의 발전으로 Image recognition과 object detection 꾀나 높은 성능을 보여주었다.
Recent Research
One encouraging news is that most of this progress is not just the result of more powerful hardware, larger datasets and bigger models, but mainly a consequence of new ideas, algorithms and improved network architectures.
- 단순히 모델의 크기를 증가시키는 것보다는, 더 효율적이고 혁신적인 네트워크 구조를 설계하고 새로운 알고리즘을 개발하는 것이 격려되었다.
Bigger size typically means a larger number of parameters, which makes the enlarged network more prone to overfitting, especially if the number of labeled examples in the training set is limited.
- 따라서 Deep Neural Network의 성능을 향상시키기 위해 단순히 네트워크를 크게 만드는 것은 두 가지 문제가 있는데 첫 번째는 overfitting되는 경향이 있다.
This can become a major bottleneck, since the creation of high quality training sets can be tricky and expensive.
- 왜냐하면 일반적으로 Network의 크기가 커짐으로 Parameter 수가 증가하게 된다. Parameter가 많을 수록 Overfiting을 하지 않기 위해서 학습에 필요한 Dataset이 더 필요하다. 하지만 우리는 보통 학습에 사용되는 Dataset은 제한되어 있기 때문에 신경망의 크기를 늘리는 것이 쉽지 않다. 그리고 High quality의 Dataset을 구하는 것은 비용이 많이 든다.
Increasing network size is the dramatically increased use of computational resources.
- 두 번째는 네트워크의 크기를 키우는 것은 computational resources가 많이 든다는 점이다.(연산이 비효율적)
Propose
In this paper, we will focus on an efficient deep neural network architecture for computer vision, codenamed Inception.
- 따라서 효율적인 네트워크 구조를 설계하기 위해서
DNN의 크기는 키우되,Parameter 수를 줄이고연산을 효율적으로 하는 방법에 대해 제안한다.
The fundamental way of solving both issues would be by ultimately moving from fully connected to sparsely connected architectures, even inside the convolutions.
DNN의 크기는 키우면서overfitting을 해결하기 위해서는 네트워크 구조를 sparse하게 만드는 것이다.
On the downside, todays computing infrastructures are very inefficient when it comes to numerical calculation on non-uniform sparse data structures. numerical libraries that allow for extremely fast dense matrix multiplication, exploiting the minute details of the underlying CPU or GPU hardware.
- 그러나 sparse한 구조는 연산을 효율적으로 할 수 없다. 따라서
연산을 효율적으로 하기 위해서는 matrix를 dense하게 구성해야 한다.
Parameter 수를 줄이는 방법에 대해서는 1x1 convolution, Max-pooling을 이용하는 것이다.
By adding auxiliary classifiers connected to these intermediate layers, we would expect to encourage discrimination in the lower stages in the classifier, increase the gradient signal that gets propagated back, and provide additional regularization.
그리고 네트워크가 깊어질 수록 gradient vanishing문제가 생기게 되는데 깊은 layer까지 정보를 전달하기 위해 auxiliary layer를 사용한다.
그리고 네트워크가 깊어질 수록 gradient vanishing문제가 생기게 되는데 깊은 layer까지 정보를 전달하기 위해 auxiliary layer를 사용한다.
Architectural Details
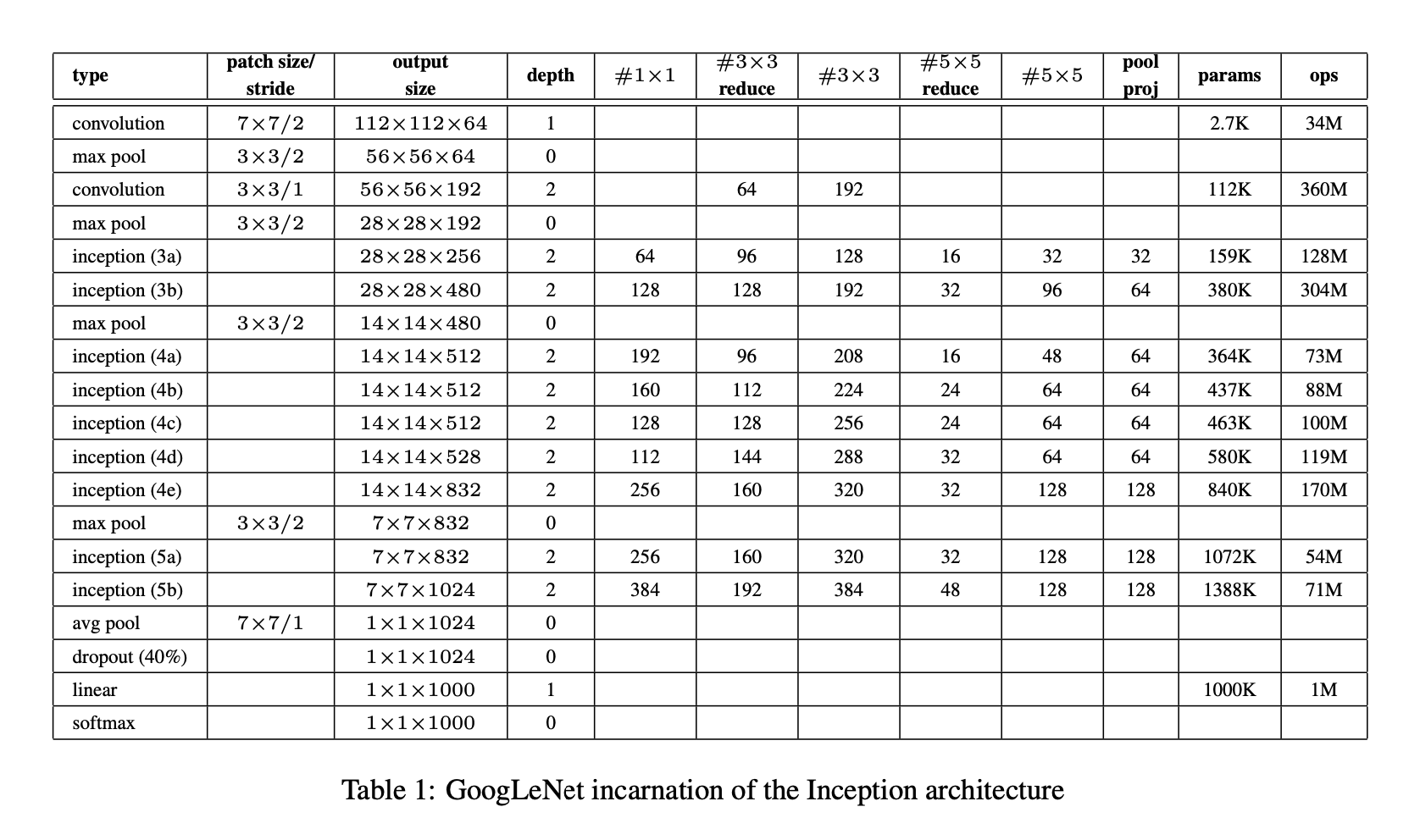
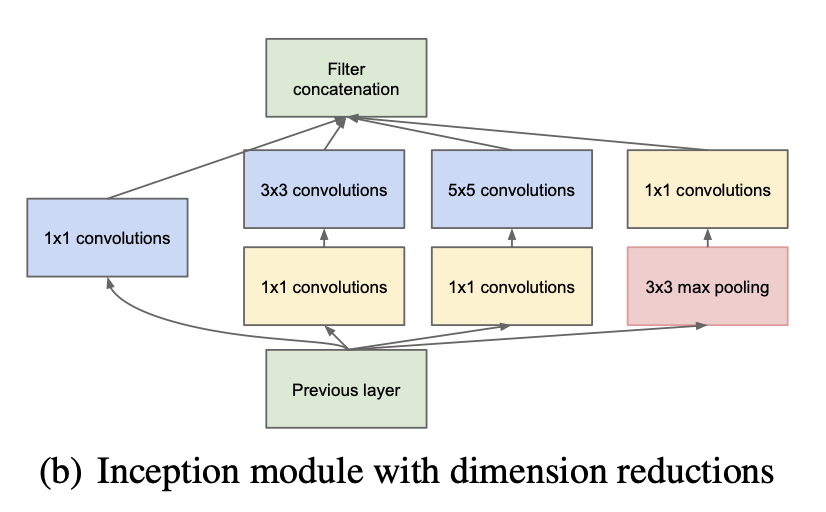
Inception Module v1
- 아래는 GoogLeNet에 포함되있는 Inception Module이다.
- Inception 모듈은 다양한 크기의 Convolution 필터를 사용하는데, 여기서 사용된 필터 크기는 1x1, 3x3, 5x5이며, 이외에도 3x3 Max Pooling을 사용한다.
- 이는 다양한 feature를 뽑기 위해
다양한 convolution filter를 병렬로 사용한다.- Input feature의 어떤 특징이 있다고 할 때, 그 특징들과 필터 간의 correlation이 어떻게 분포되어 있는지 모르기 때문에 다양한 필터를 사용한다.
MaxPooling은 invariant한 특성을 잡아낼 수 있기 때문에 사용하였다.- 본 논문에서는 다양한 feature를 뽑기 위해 여러 convolution filter를 병렬로 사용하는 것을
local sparse structue라고 설명한다.(네트워크의 크기를 키운다) - 그리고 convolution filter와 MaxPooling을 concatenation 연산으로 합쳐지는데, 이것을 논문에서는
dense matrix연산으로 표현했다. (효율적인 연산)
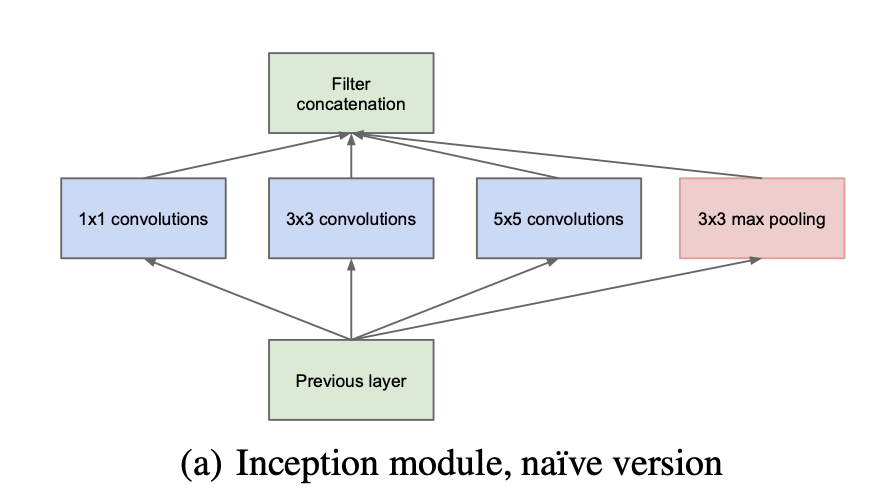
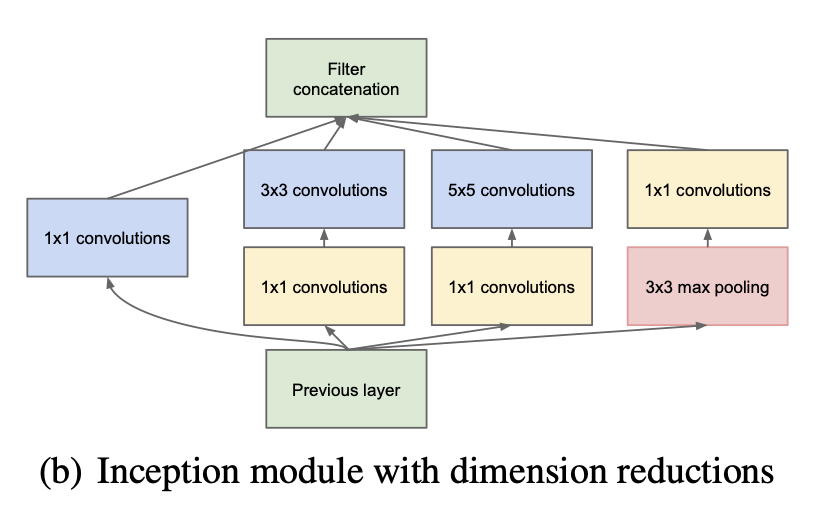
- 위에서 Inception navie version에 이어 아래 그림을 보면 Dimension reduction을 통해 Parameter 수를 더 줄여보고자 1x1 Convolution을 적용했고 또한 concatenation되는 채널의 수를 마음대로 조정할 수 있기 때문에 유용하다.
- 아래 아키텍쳐의 장점은 연산량은 크게 늘리지 않으면서 네트워크의 크기를 늘릴 수 있다는 점이다.
- 위와 같은 여러개의 Inception Module을 이용하여 아래와 같이 네트워크를 구성한 것이 아래그림의
Inception v1(GoogLeNet)이다.
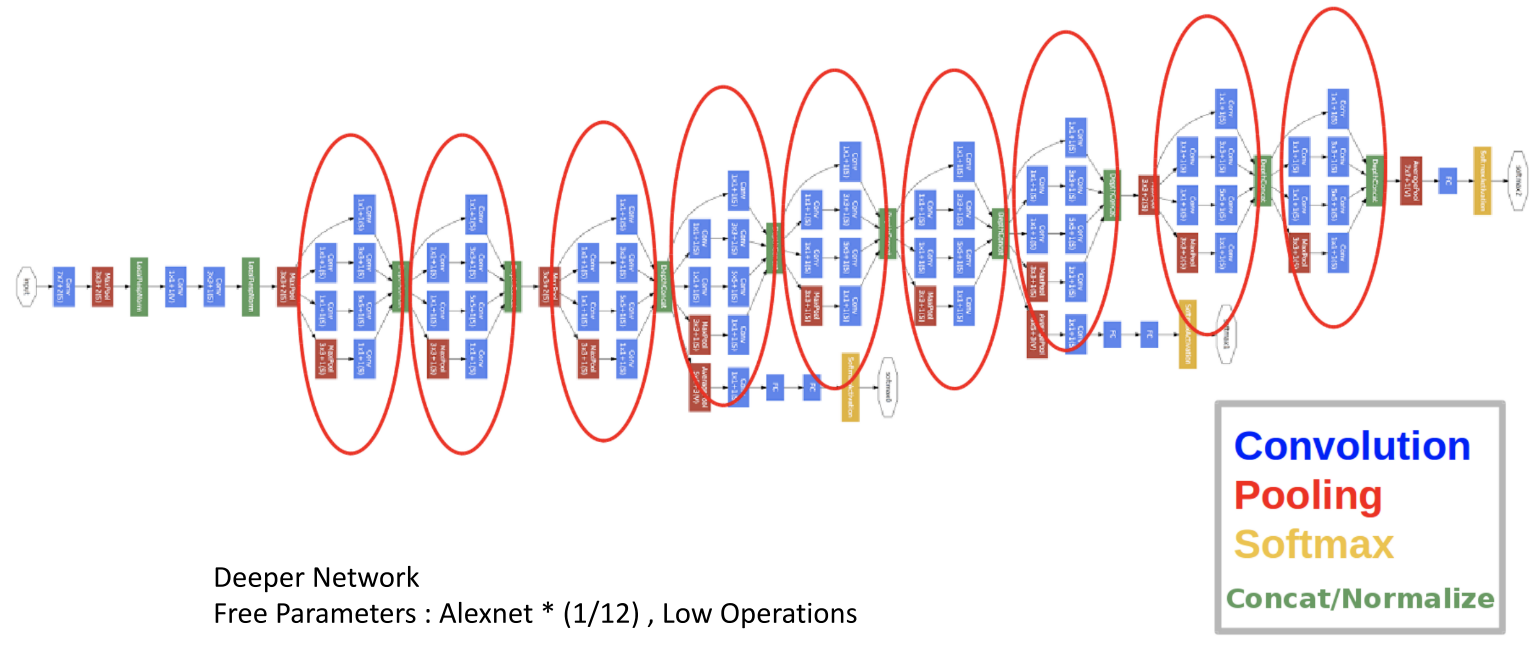
GoogLeNet
아래는 사진은 모델 구조이다.
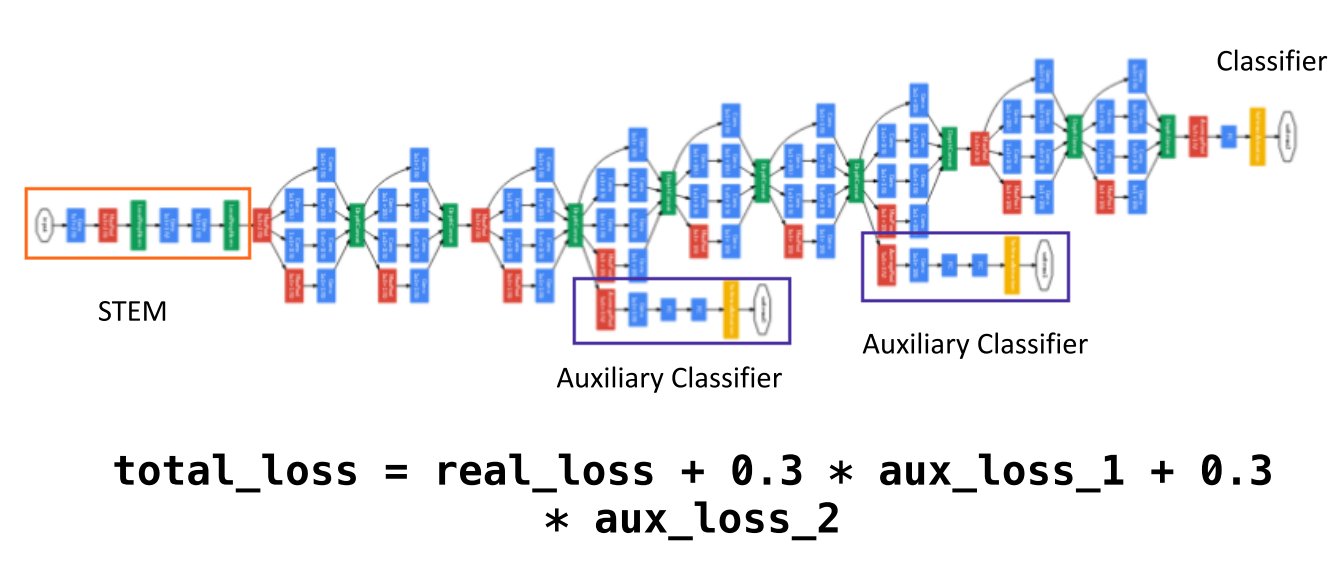
Auxiliary Classifier
- 깊어진 layer에서 발생하는 vanishing gradient 문제를 개선하기 위하여 적용된 트릭이다
- 중간 중간에 Loss를 계산할 수 있는 layer를 추가적으로 만들어서 최종 loss에 반영하게 된다.
- 아래 그림을 보면 실제 output에 의해 계산된 loss가 100%라면
auxiliary loss에는 30%의 가중치만 준 것을 알 수 있다. - 여기서 사용된
auxiliary loss는 training 할 때에만 사용되고 inference할 때에는 사용되지 않는다.
Inception v1 Code Review
아래 사진은 inceptionModule 이다.
먼저 위 그림에서 다양한 필터 크기를 갖는 convolution을 클래스의 함수형태로 정의한다.
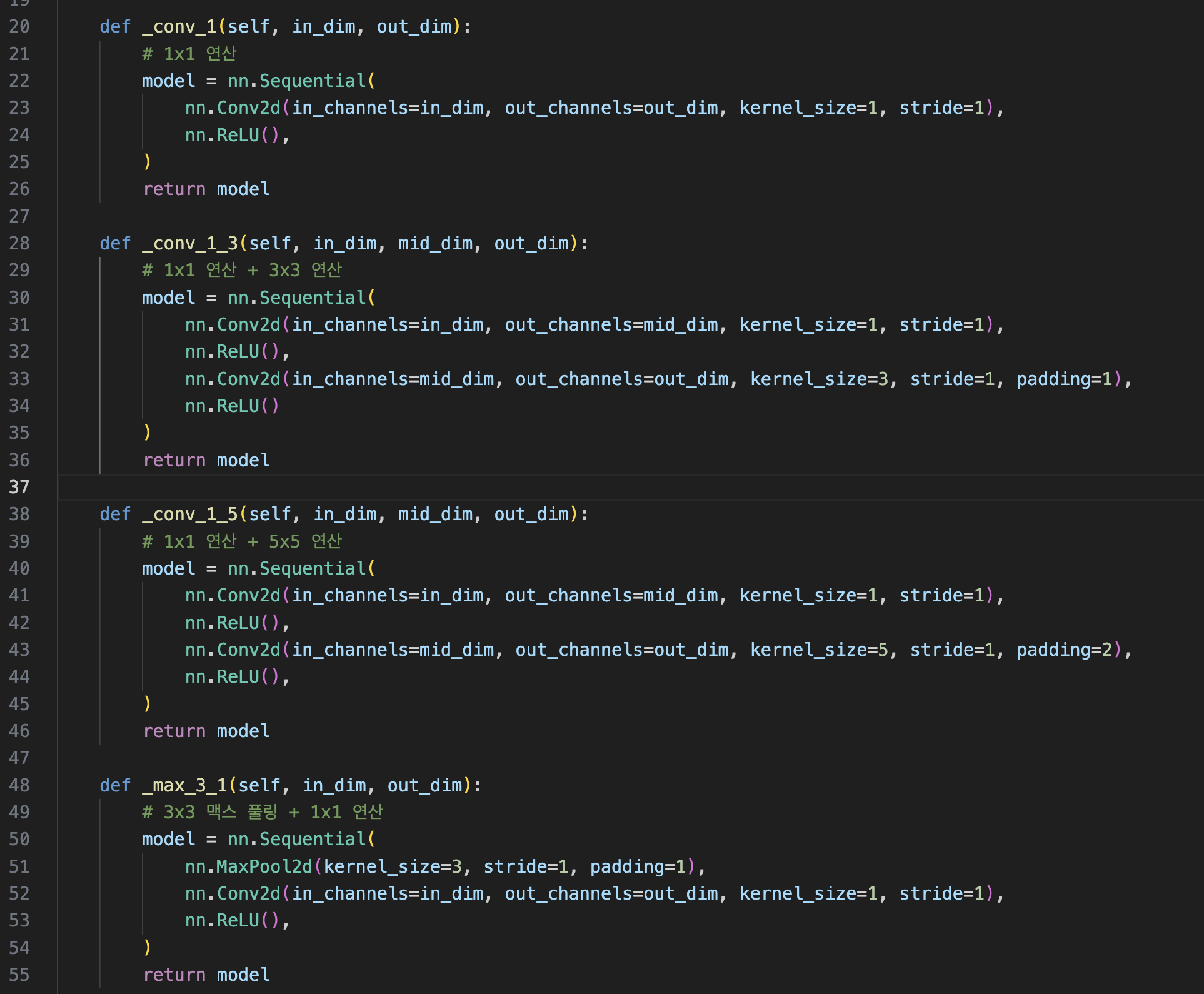
아래는 위 함수들을 가지고 초기화하는 클래스로 아래와 같은 패턴으로 구성되어 있으며 conv의 첫 번째 인자는 input channels이고 두 번째 인자는 output channels이다.
(in_dim, out_dim_1)
- 1x1conv 입력과 최종 출력
(in_dim, mid_dim_3, out_dim_3)
- 1x1conv(in_dim, mid_dim_3)
- 3x3conv(mid_dim_3, out_dim3)
(in_dim, mid_dim_5, out_dim_5)
- 1x1conv(in_dim, mid_dim_5)
- 5x5conv(mid_dim_5, out_dim_5)
(in_dim, pool)
- maxpool → 1x1conv(in_dim, pool)

이 후 inception Module을 GoogLeNet에서 사용된다.
GoogLeNet에서는 초기 앞단의 Conv2d→MaxPool→Conv2d→MaxPool→inception Module … 을 사용한다. 따라서 만약 (224, 224, 3)이미지가 들어온다면 아래 초기 conv block을 지나 (-1, 192, 28, 28)가 inception Module의 input으로 사용된다.
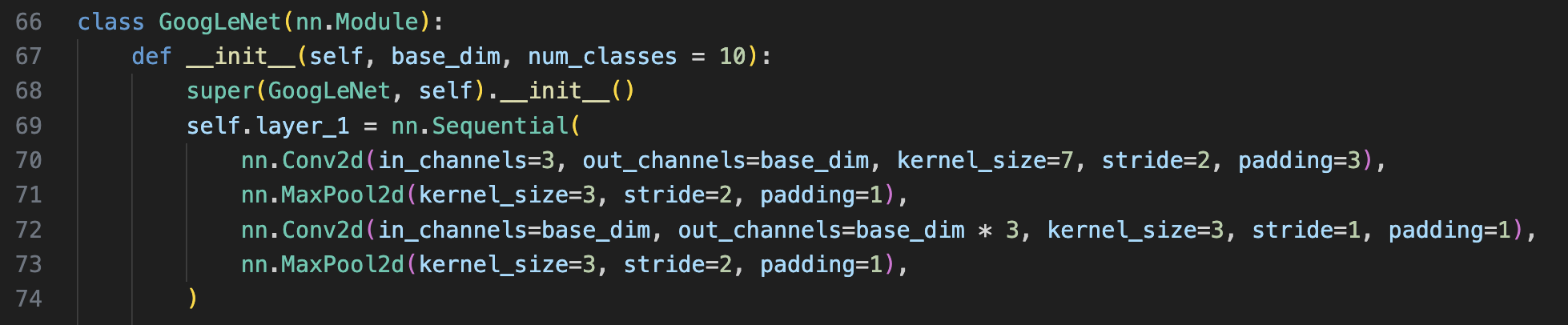
처음 base_dim은 64로 시작하며 inceptin Module이 끝나면 Dropout layer를 거쳐 classification을 위한 linear layer를 추가한다.
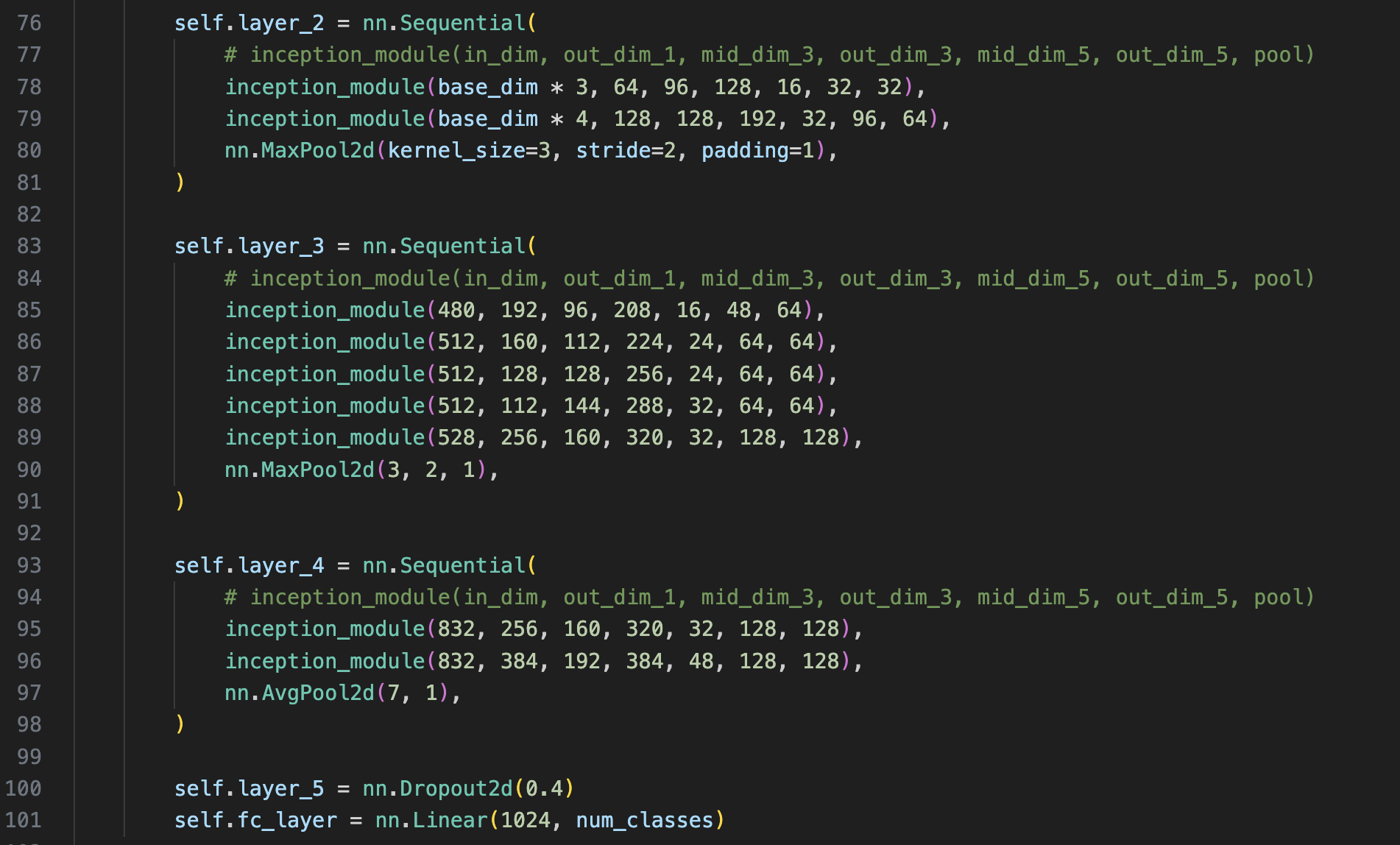
파란색 박스: 1x1conv
노란색 박스: 1x1conv → 3x3conv
핑크색 박스: 1x1conv → 5x5conv
주황색 박스: 3x3Maxpool → 1x1conv
로 구성되어 있으며 위 박스들에는 input으로 전부 동일하게 [-1, 192, 28, 28] 이 들어간다.
이후 concat하는 부분이 있음으로 각 박스의 최종 출력 채널을 다 더해주며 된다.
64 + 128 + 32 + 32 = 256 channels가 되는 것을 볼 수 있다.
다음은 GoogLeNet의 foward함수인데

layer_4 Sequential layer에 AvgPool2d(7, 1)을 적용하게 되는데, [2, 1024, 7, 7]이 kernel=7이고 stride=1인 풀링을 거쳐 [2, 1024, 7, 7]가 [2, 1024, 1, 1]이 된다. layer_5는 dropout임으로 3의 출력도 동일하다.
out.view(out.size(0), -1) 를 통해서 [2, 1024]로 변경된다.
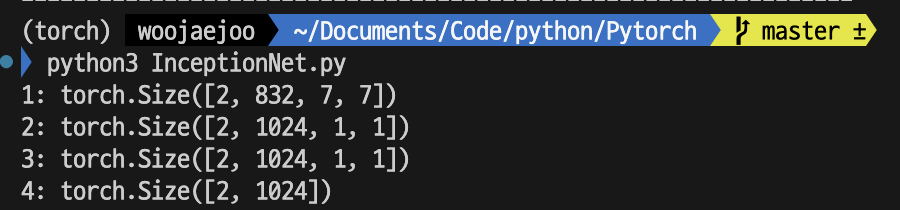
그리고 1024를 input으로하고 class_num을 output으로 하는 classification layer를 적용한다.
torch.summary 결과도 똑같은 것을 확인할 수 있다.

Inception v2
위에서 살펴본 Inception module은 Inception v1(GoogLeNet)에 해당하는 딥러닝 네트워크이다.
이후에 Tensor Factorization등의 최적화 기법들을 적용해 개선한 버전이 v2, v3 버전이다.
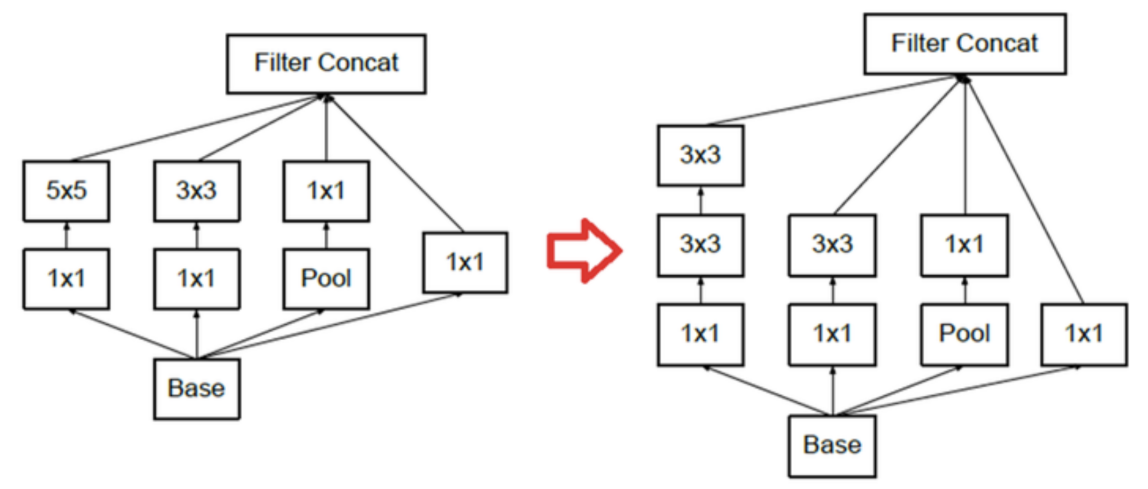
기존 navie Inception Module을 오른 쪽과 같이 변경한 구조를 Inception Module A 라고 한다.
그리고 해당 Module은 Inceptionv2에서 사용된다.
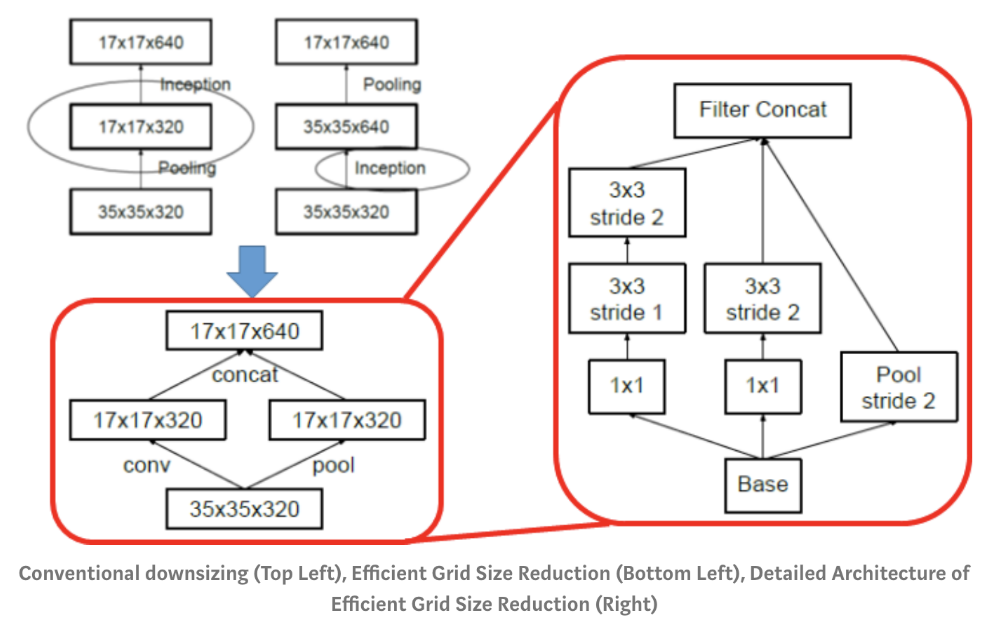
Grid Size Reduction
- Resolution을 줄이기 위한 방법으로는 크게 2가지가 있는데 Convolution 연산 시 stride를 2 이상으로 가져가거나, Pooling을 하는 것이다.
- 이 때, Convolution 연산의
stride를 적용하여resolution을 줄이게 되면연산량이 다소 많아지게 되고 반면Pooling을 이용하여 resolution을줄이면Representational Bottleneck이라는 문제가 발생하는 데 말 그대로 resolution이 갑자기 확 줄어들어서 정보를 잃게 되는 것을 말합니다. - 그래서 Convolution 연산의 stride 적용과 MaxPooling을 병렬적으로 하는 방법을 적용하는
Grid Size Reduction방법이Inception Module v1부터 전체적으로 반영이 되어있다.
Inception v3
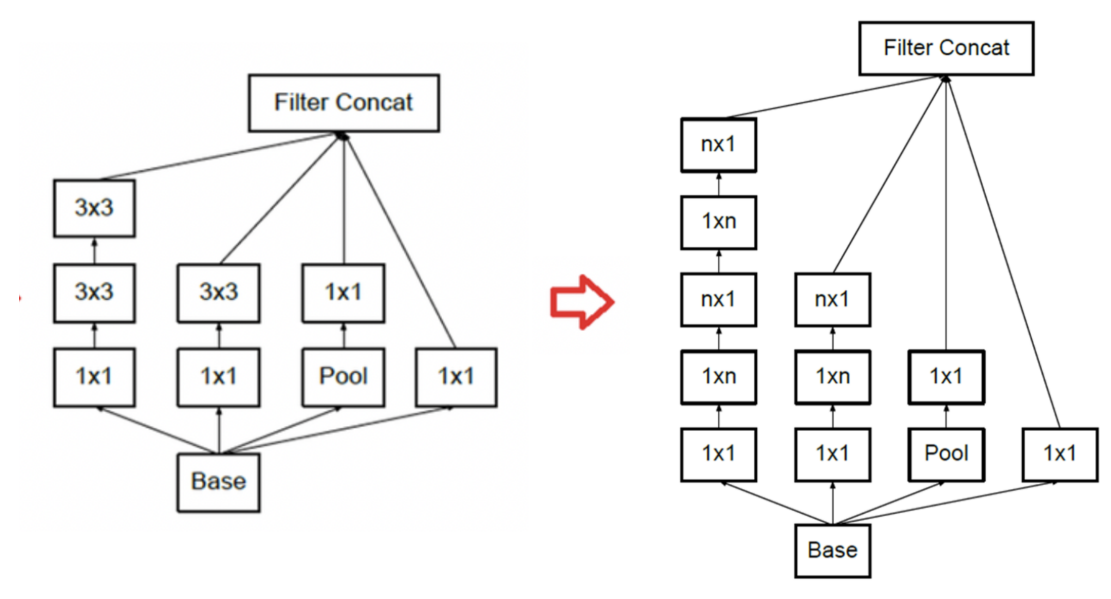
- Tensor factorization을 이용해
1xn,nx1convolution을 적용하여 최적화 한 것을Inception Module B라고 하며 Inception v3에 적용된다. - 이 모듈은
Inception Module A에 비해 연산량을 33% 절감하였다고 논문에서 설명한다. 예를 들어n에 3을 대입하면 개선 전/후가 대응이 되는 것을 볼 수 있다. - Tensor factorization은 아래에서 자세히 설명한다.
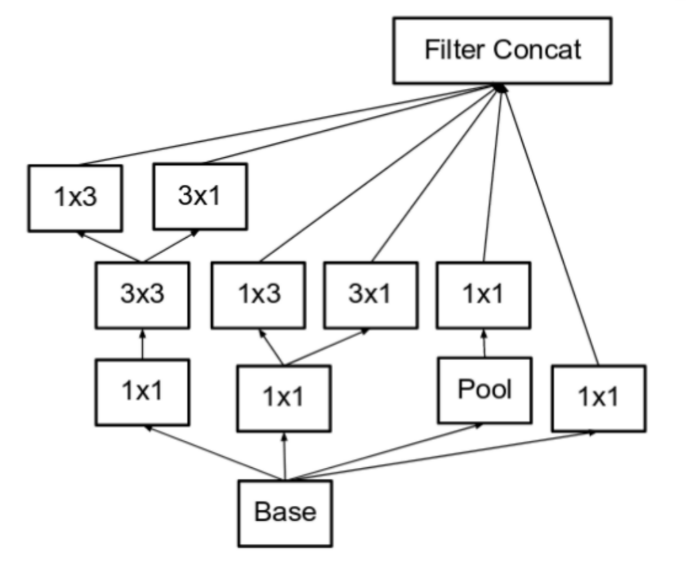
아래는 Inception Module C인데 직전에 언급한 Representational Bottleneck 문제를 완화하기 위해서 좀 더 깊게가 아닌 좀더 넓게 concatenation 하는 방법으로 만들어진 모듈이다.
- 모듈 내부에서 Convolution + stride나 Pooling이 깊게 적용되면 Representational Bottleneck문제가 더 악화되니 옆으로 쌓아보려는 시도이다. 아래 Module은
Inception v3에서 output 단에 사용되었습니다.
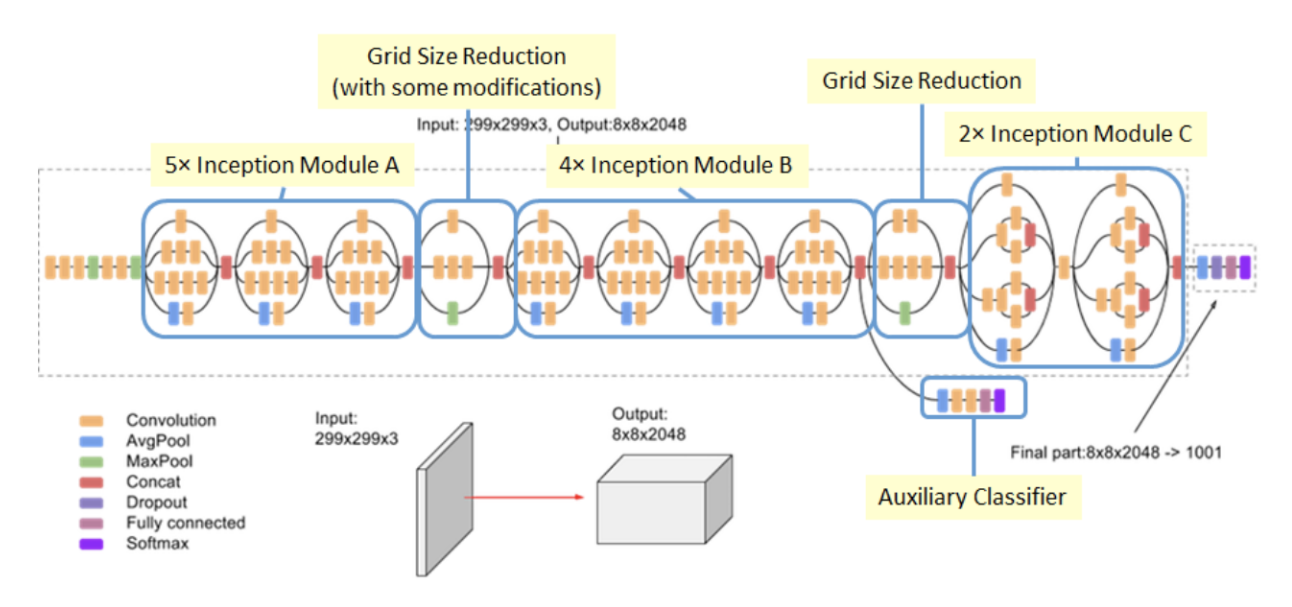
아래 네트워크 아키텍쳐가 Inception v3다. 앞에서 설명한 Inception Module A, B, C 그리고 Grid Size Reduction이 적용된 형태이다. 처음에 살펴본 Inception v1 GoogLeNet에서 적용된 Auxiliary classifier는 2개였다가 1개로 축소된 것을 볼 수 있는데 해당 layer의 효과가 크게 좋지 않았기 때문이라고 유추할 수 있다.
Tensor Factorization
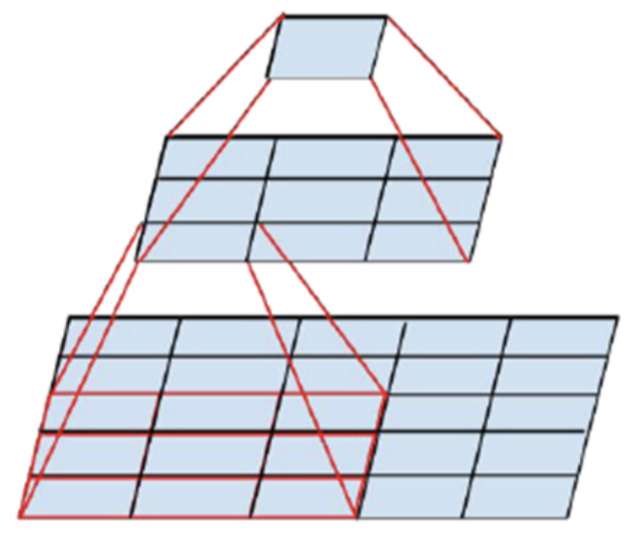
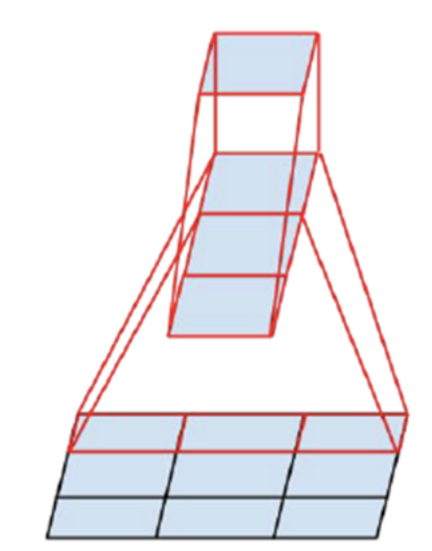
Tensor factorization은 행렬을 곱하기 전 상태의 파라미터를 저장함으로써 행렬의 곱 이후에 늘어나는 파라미터의 갯수에 대비하여 파라미터 수를 적게 저장하는 방법이다.
이를 CNN에 적용하면 하나의 큰 필터를 사용하는 것보다 작은 필터 여러개를 사용하는 것이 연산량에 있어서 더 효율적이다 라는 것이다. 아래 예시를 보자
- 3x3 kernel을 이용해서 1x1 output feature를 만드는 것보다 1x3 → 3x1 의 커널을 사용하는 것이 연산량이 더 적다.
- (3x3) =
9vs (3x1) + (1x3) =6
- (3x3) =
- 실제 계산을 해보자. 아래는 output feature에 따른 계산 공식이다
- 3x3 Input Image가 들어오고 3x3커널을 사용해 1x1 output feature를 만드는 결과는 아래와 같다.
- 3x1 커널을 사용 후 1x3커널을 사용해 1x1 output feature를 만드는 결과는 아래와 같다.
- 이 후 1x3커널을 사용하면 아래처럼 된다.
Comment