
Cite
Hui Zhang1,2 Zheng Wang3 Zuxuan Wu1,2 Yu-Gang Jiang1,2; arXiv preprint arXiv:2303.08730
- https://arxiv.org/pdf/2407.09359
- 출간일: 2024. 07. 12
Abstract
Unsupervised Abnormal Detection에서 Generative Model 기반 접근법은 두 가지 주요 문제를 가지고 있습니다.
1. 미탐(False Negative)
- 문제: 이미지에 실제로 비정상적인 영역이 있어도, 그 영역이 미세한 결함일 경우, 모델이 이를 정상 영역으로 인식하여 복원된 이미지에서도 그대로 미세한 결함이 나타난다는 것입니다. 즉, 이상 영역을 가진 이미지를 그대로 재구성하게 되어, 모델이 이상을 탐지하지 못하는 상황이 발생합니다.
- 근거: U-Net 기반의 생성 모델은 입력 이미지를 압축하여 저차원 공간에 표현한 후 다시 복원하는 방식으로 작동합니다. 이 과정에서 작은 결함 같은 미세한 이상은 저차원 공간에서 충분히 표현되지 못하고 무시될 가능성이 큽니다.
2. 오탐(False Positive)
- 문제: 정상적인 이미지임에도 불구하고, 모델이 이미지를 정확하게 복원하지 못하고 대략적으로만 복원할 경우, 원본 이미지와 복원된 이미지 사이에 오차가 발생할 수 있습니다. 이 오차로 인해 모델은 정상 이미지를 비정상으로 잘못 판단하게 됩니다. 이를 Coarse Reconstruction이라고 하며, 이로 인해 모델의 성능이 저하되고 오탐이 발생합니다.
- 근거: U-Net 기반의 생성 모델은 입력 이미지를 저차원 공간에 압축한 후 다시 복원합니다. 이때 복잡한 정상 패턴이 저차원으로 압축되면서 대략적으로만 복원될 수 있습니다. 이로 인해 정상적인 패턴에서 불필요한 복원 오차가 발생할 수 있습니다.
논문에서 제안한 해결 방법:
본 논문에서는 위 두 문제를 해결하기 위해, Diffusion Model을 기반으로한 다양한 이상 영역의 픽셀들을 노이즈 처리하여, 노이즈 된 이미지를 가지고 모델이 정상 영역(이미지)으로 복원하도록(Noise-to-Norm)합니다. 이를 통해 보다 정확한 복원(Reconstructed as Normal)이 가능해지며 오탐과 미탐을 줄이게 됩니다.
그리고 Diffusion Model의 느린 추론 속도를 개선합니다. Diffusion Model은 하나의 데이터를 생성하기 위해 노이즈 이미지로부터 interative하게 노이즈를 제거하는 과정을 거쳐야하기 때문에 수행시간이 느리다는 단점이 있습니다. 이를 해결하기 위해 One-step denosing(한 번에 노이즈를 제거하는)방법을 사용함으로써 속도를 향상 시켰다.
Introduction
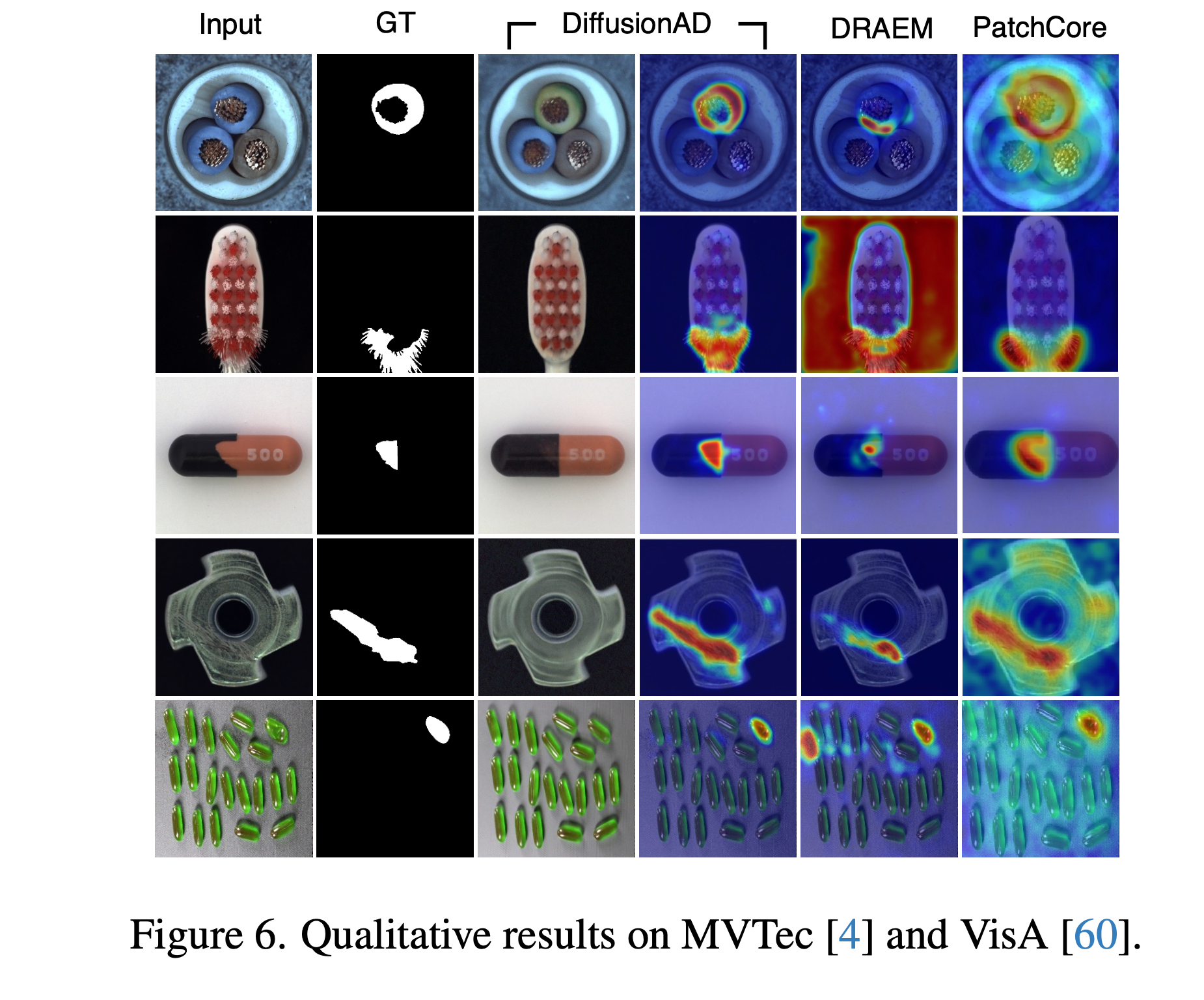
DRAEM과 Diffusion AD 비교
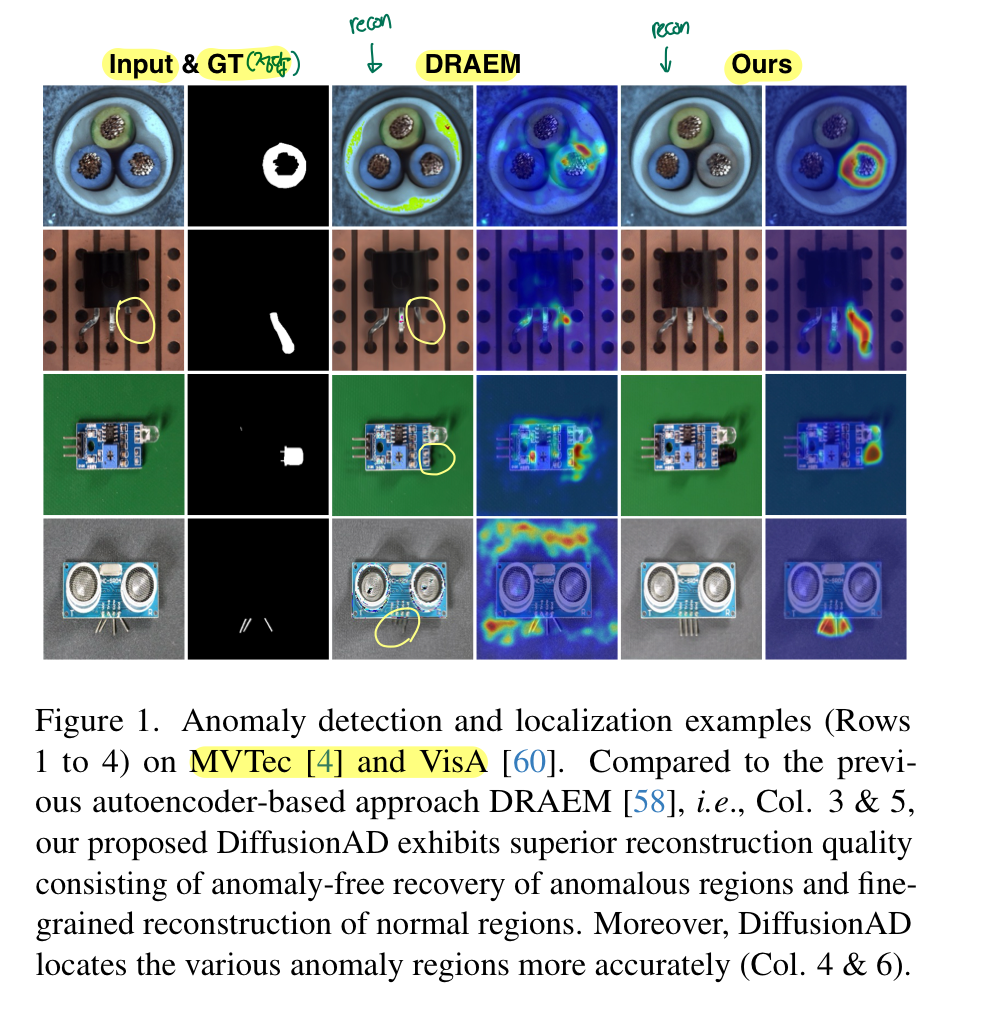
위 이미지는 MVTec, Vis A 데이터셋으로 구성되어졌으며 Input을 DREAM과 Diffusion AD이 재구성한 이미지 그리고 그리고 비정상 이미지를 재구성 했을 때 어디가 이상 영역인지를 보여주는 그림이다.
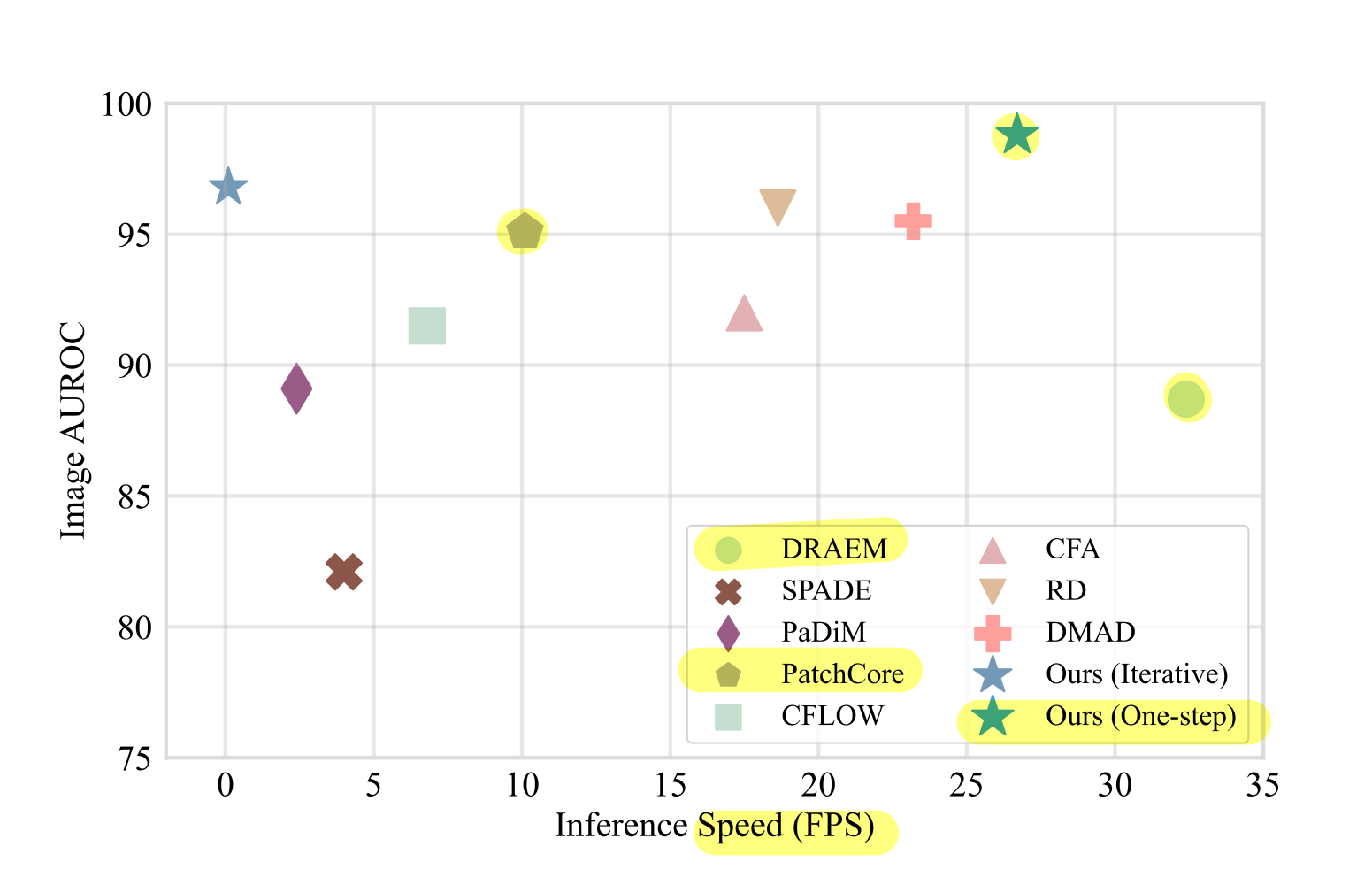
X축은 속도, Y축은 정확도를 나타냅니다.
본 논문에서 제한하는 모델은 DREAM보다는 느리지만 높은 정확도를 보이는걸 볼 수 있으며 PatchCore보다 2.5배가량 빠르며 정확도 또한 높은 것을 볼 수 있습니다.
Preliminary
Diffusion Model 이란?
이 모델은 데이터에 점진적으로 노이즈를 추가하는 과정(Forward Process)과, 추가된 노이즈를 제거하여 원본 데이터를 복원하는 과정(Reverse Process)으로 작동합니다.
Diffusion모델은 이미지를 생성하거나 복원하는데 사용되는 생성 모델(Generative Model)입니다.
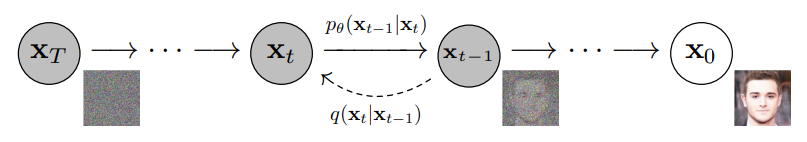
1. 노이즈 추가(Forward Process)
원본 데이터에 점진적으로 노이즈를 추가하여 데이터를 완전히 노이즈로 뒤덮인 상태로 만듭니다.이 과정에서 데이터는 원래의 형태와 특징(discriminative feature)을 점차적으로 잃어버리고, 최종적으로 완전한 노이즈 이미지가 됩니다.
2. 노이즈 제거(Reverse Process)
노이즈가 추가된 데이터에서 원래의 데이터를 복원하기 위해, 노이즈를 단계적으로 제거하는 과정을 반복합니다.모델은 각 단계에서 노이즈를 예측하고 이를 제거하여 점차 원본 이미지를 복원해 나갑니다.
3. 장점
고품질 데이터 생성: 반복적인 노이즈 제거 과정을 통해 매우 세밀하고 고해상도의 데이터를 생성해 낼 수 있습니다.
4. 단점
느린 처리 속도: 노이즈를 점진적으로 제거하는 과정이 반복되기 때문에, 데이터 생성과 복원이 느리게 진행됩니다.
Proposed Method
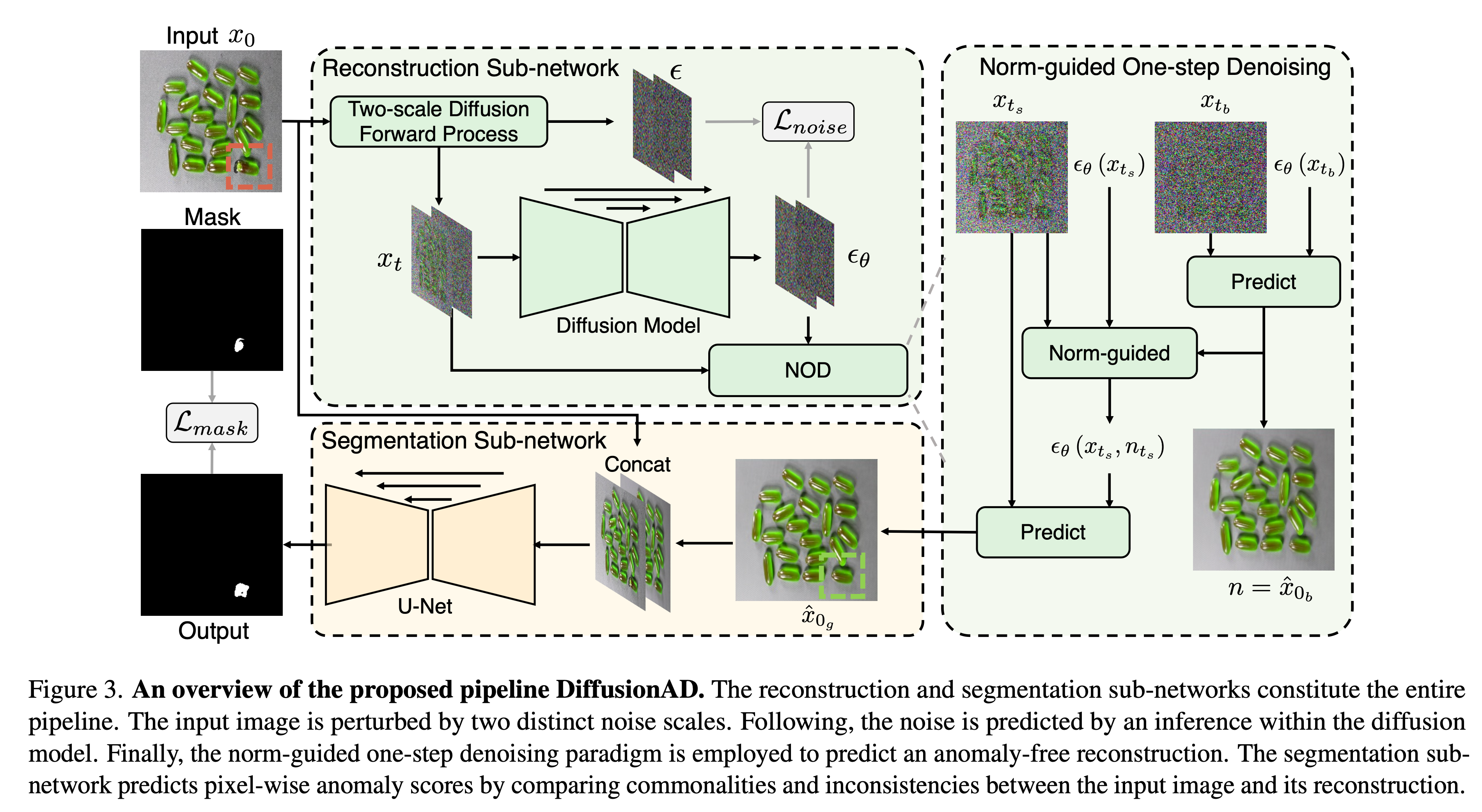
위 이미지는 논문에서 제안하는 전체 모델의 개요입니다.
Reconstruction Sub-network
Diffusion모델을 기반으로 작동하며, noise-to-norm(노이즈를 정상 상태로 변환)방법을 사용합니다.
먼저, Diffusion 모델의 forward process를 통해 원본 이미지(\(x_0\))에 임의의 시간 \(t\)에 대해서 노이즈를 추가합니다. 이렇게 노이즈가 섞인 이미지 \(x_t\)를 만드는 역할을 합니다.
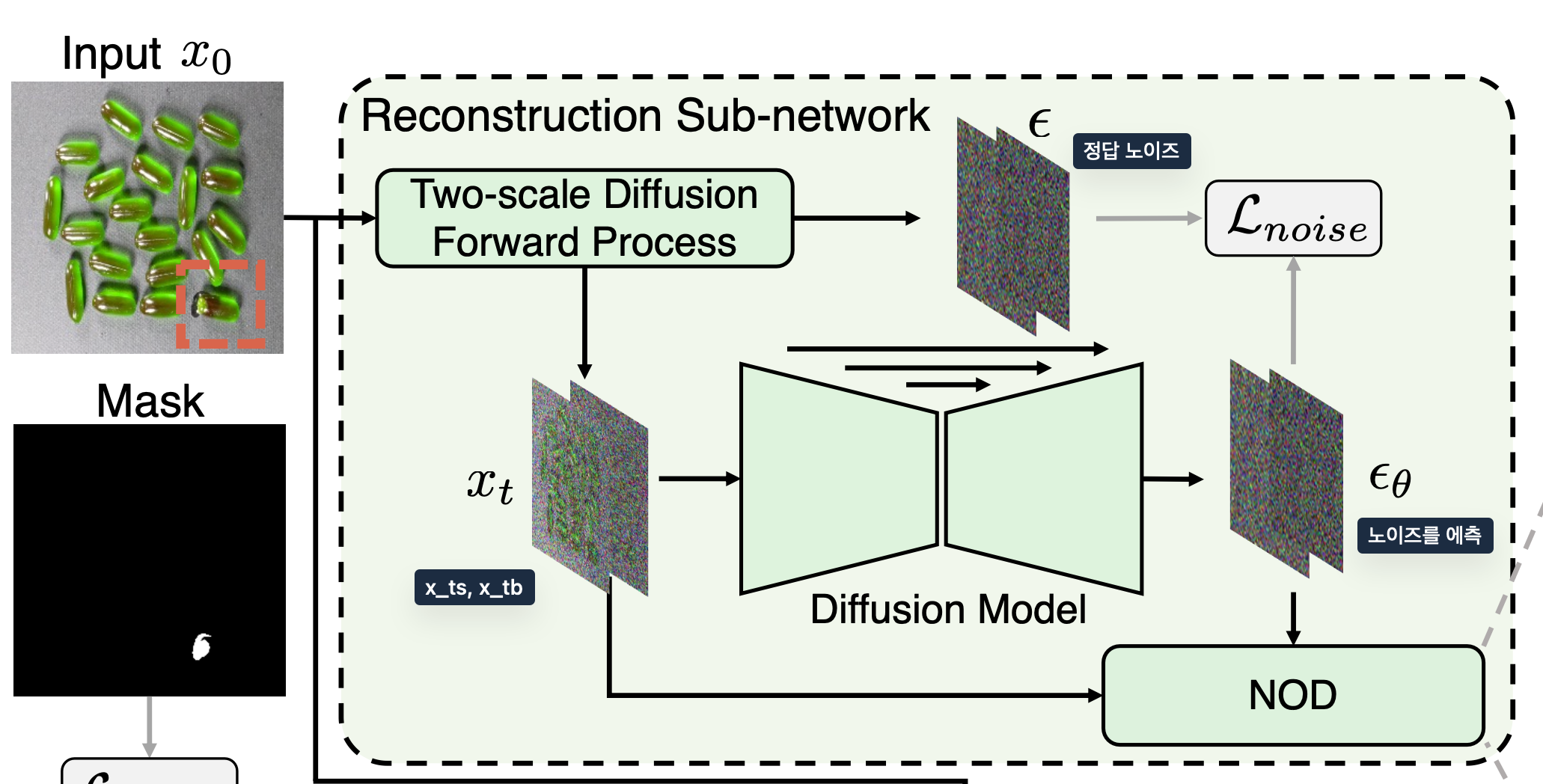
위 이미지에서는 Two-scale Diffusion Forward Process를 통해 서로다른 시간 \(t_s, t_b\) 에서의 노이즈를 추가한 이미지를 생성합니다.
- 첫 번째 스케일(\(t_s\)): 작은 노이즈 스케일이 적용된 시간 단계입니다. 이 단계에서 원본 이미지에 상대적으로 적은 노이즈가 추가되며, 이는 미세한 디테일을 더 잘 보존하는 역할을 합니다.
- 두 번째 스케일(\(t_b\)): 큰 노이즈 스케일이 적용된 시간 단계입니다. 이 단계에서는 더 많은 노이즈가 이미지에 추가되며, 이는 더 큰 결함이나 이상을 효과적으로 처리할 수 있도록 합니다.
시간 \(t\)가 증가함에 따라 \(x_0\)는 점진적으로 원래의 특징을 잃어가며, 결국 노이즈 형태의 이미지로 바뀌게 됩니다.
특히, 이상 영역이 있는 이미지의 경우, forward process를 통해 이상 픽셀들이 본래의 특징을 잃고 단순한 노이즈로 인식하게 됩니다.
모델은 이러한 노이즈가 포함된 이미지를 점진적으로 이상이 없는 원본 이미지로 복원하도록 시도합니다.
이러한 방법을 통해 다양한 이상영역을 전부 노이즈로 취급해 노이즈로 부터 원본이미지를 생성함으로 일반화 능력이 향상되며 복잡한 패턴에 대해서도 높은 퀄리티로 복원이 가능해 집니다.
One-Step Denosing
reconstructive sub-network에서는 Diffusion모델을 활용한다고 언급했습니다.
Diffusion 모델은 노이즈를 제거하는 과정에서 많은 연산량과 자원을 필요로 합니다.
학습 단계에서는 반복적인(Iterative) 노이즈 제거 방식을 사용하지만, 추론(Inference) 단계에서는 이 방법이 많은 자원과 시간이 요구됩니다. 이를 해결하기 위해 One-step denoising 방식을 적용합니다.
One-step denoising을 사용하면 Diffusion 모델의 느린 추론 속도 문제를 해결할 수 있습니다.
이 과정에서 모든 이미지에 대해 두 가지 다른 노이즈 스케일을 적용합니다. 작은 결함 영역에는 작은 노이즈 스케일을, 큰 결함 영역에는 큰 노이즈 스케일을 사용합니다.
작은 노이즈를 적용한 시간은 \(t_s\), 큰 노이즈를 적용한 시간은 \(t_b\)로 설정합니다. (\(t_b > t_s)\)
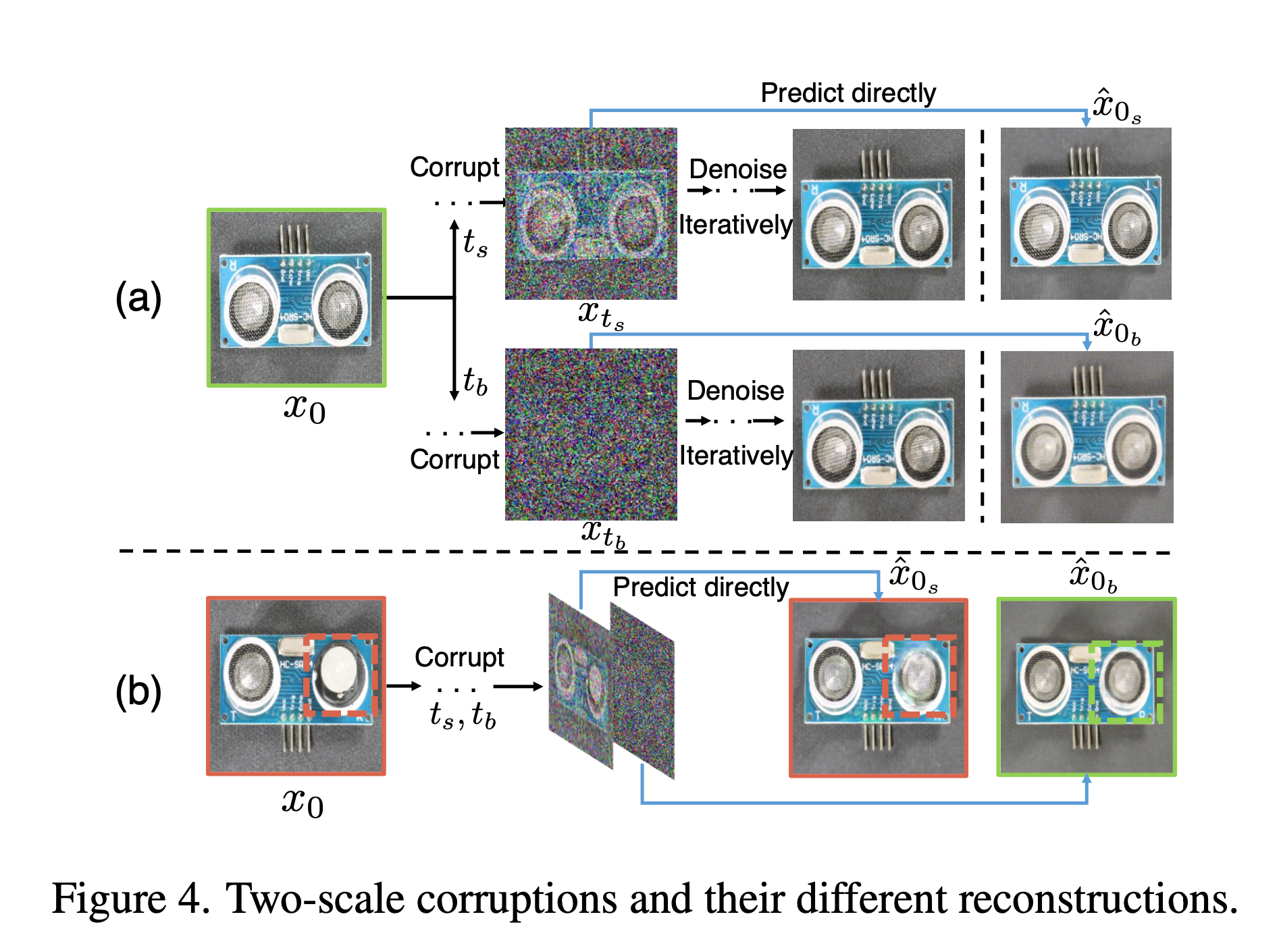
(b) 이미지를 보면, One-step denoising을 적용했을 때, 상대적으로 노이즈가 적게 적용된 \(t_s\)시점에서 생성된 \(\hat{x}_{0s}\)는 (a)에서 반복적으로 denoising한 결과와 유사하게 고품질의 이미지(Fine-grained recosntruction)를 생성한 것을 확인할 수 있습니다.
반면, 노이즈가 많이 적용된 \(t_b\)시점에서 생성된 이미지는 오히려 반복적으로 denoising 한 결과(a)보다 품질이 떨어지는 것을 볼 수 있습니다. 이는 \(t\)가 증가할수록 이미지 품질이 더 저하된다는 것을 의미합니다.
작은 결함 영역
- 작은 결함영역에 대해서는 작은 노이즈 스케일을 사용하면 이미지의 정교한 부분의 의미를 잘 보존하면서 세밀한 디테일을 살릴 수 있기 때문입니다.
- 그러나 큰 결함영역에 대해서는 작은 노이즈 스케일을 사용하면 노이즈 주입이 충분하지 않아서 이상 영역이 완전히 제거되지 않게 됩니다. 즉, 결함영역이 다 노이즈로 가려지지 못하게 됩니다. 이 때문에 재구성한 이미지에 이상영역이 그대로 나타나게 됩니다.
큰 결함 영역
- 따라서 큰 결함 영역에 대해서 처리하려면 더 큰(많은) 노이즈 스케일링을 사용해야 합니다.
- 이는 노이즈가 더 많이 주입되어 큰 결함영역을 잘 가리게되어 효과적으로 이미지를 재구축(Anomaly Regions를 잘 복구) 할 수 있습니다.
- 그러나 이렇게 큰 노이즈를 한번에 제거하려고 하면 이미지에 왜곡(coarse-reconstruction)이 발생합니다.
- 이는 interative하게 노이즈를 제거하지 않고 한 번(one-step)에 제거 하려고 하기 때문입니다.
- 이러한 문제를 해결하기 위해 Norm-guided Denosing 방법을 사용합니다
Norm-guided Denosing
이를 설명하기 위해 먼저 기호에 정리하겠습니다.
- \(x_{ts}\): 원본 이미지에 대해 노이즈 스케일을 적게 사용한 이미지
- \(x_{tb}\): 원본 이미지에 대해 노이즈 스케일을 많이 사용한 이미지
- \(\epsilon_{\theta}(x_{ts})\): 이미지를 복원하기 위해 노이즈 스케일이 적게 사용한 이미지의 예측 노이즈
- \(\epsilon_{\theta}(x_{tb})\): 이미지를 복원하기 위해 노이즈 스케일을 많이 사용한 이미지의 예측 노이즈
- \(\hat{x}_{0s}\): 작은 노이즈(\(t_s\)) 스케일이 적용된 이미지를 복원한 이미지
- \(\hat{x}_{0b}\): 큰 노이즈(\(t_b\)) 스케일을 적용한 이미지를 복원한 이미지
- \(\hat{x}_{0g}\): reconstructed-subnetwork에서 최종적으로 복원한 이미지
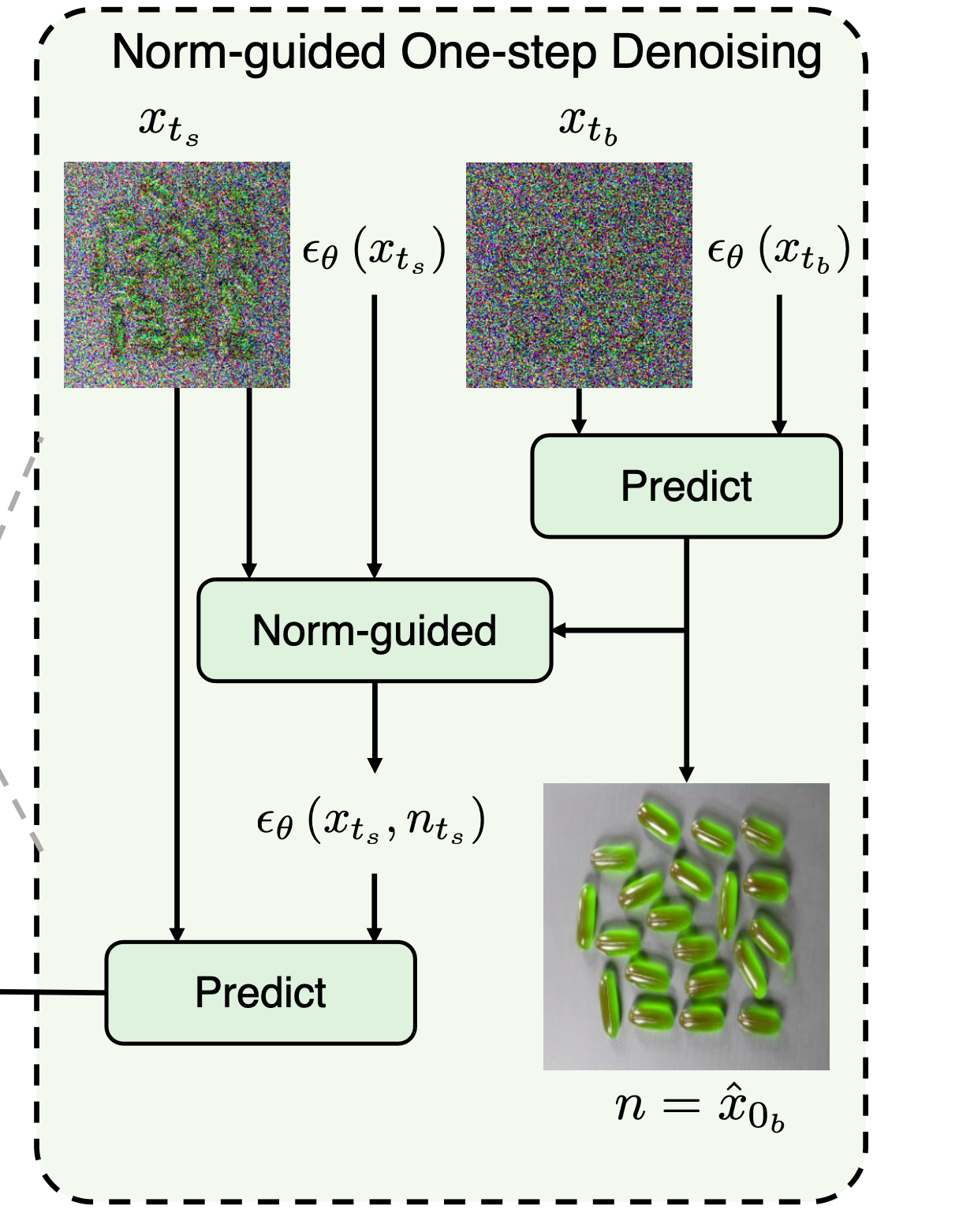
- \(x_{0b}\)와 예측된 노이즈 \(\epsilon_{\theta}(x_{tb})\)를 사용해 이미지를 복원합니다. 이 복원된 이미지를 \(\hat{x}_{0b}\)라 하고, 이를 간단히 \(n\)이라고 표현합니다.
- 생성된 \(n\)은 작은 노이즈 스케일로 복원될 이미지 \(\hat{x}_{0s}\)을 잘 생성하도록 가이드하는 역할을 합니다.
- 그 다음, \(n\)에 \(t_s\)에서 예측된 노이즈 \(\epsilon_{\theta}(x_{ts})\)를 추가하여 이미지를 변형합니다. 이를 \(n_{ts}\)라고 표현합니다.
- \(x_{ts}\)와 \(n_{ts}\)두 이미지를 활용하여 최종적으로 고퀄리티의 이미지를 생성합니다.
- \(\epsilon_{\theta}(x_{ts}, n_{ts})\)는 두 이미지 간의 관계(차이)를 고려하여, 이를 바탕으로 노이즈를 예측하기 때문에 더 정교한 노이즈 제거를 가능하게 합니다.
- 마지막으로 이렇게 생성된 이미지는 입력 이미지와 채널 단위로 결합되어, 정상과 비정상을 판단하게 됩니다.
Segmentation Sub-network
- U-Net 아키텍처 기반를 활용합니다.
- 원본 이미지(\(x_0\))와 Reconstruction Sub-network를 통해 얻은(\(\hat{x}_{0g}\))을 가까운 이미지를 채널 단위로 연결(channel-wise concatenation)하여 모델은 두 입력간의 불일치(inconsistencies)와 공통점(commonalities)을 활용해 픽셀 단위(pixel-wise)로 이상 점수(anomaly score)를 예측하도록 학습합니다.
Anomaly Synthetic Strategy
일반적으로 이상 감지 모델을 훈련할 때, 실제 이상 데이터가 많이 부족하거나 아예 없는 경우가 많습니다.
이를 해결하기 위해 가짜 이상(pseudo-anomalies)을 학습중에 실시간으로 생성해 활용합니다.
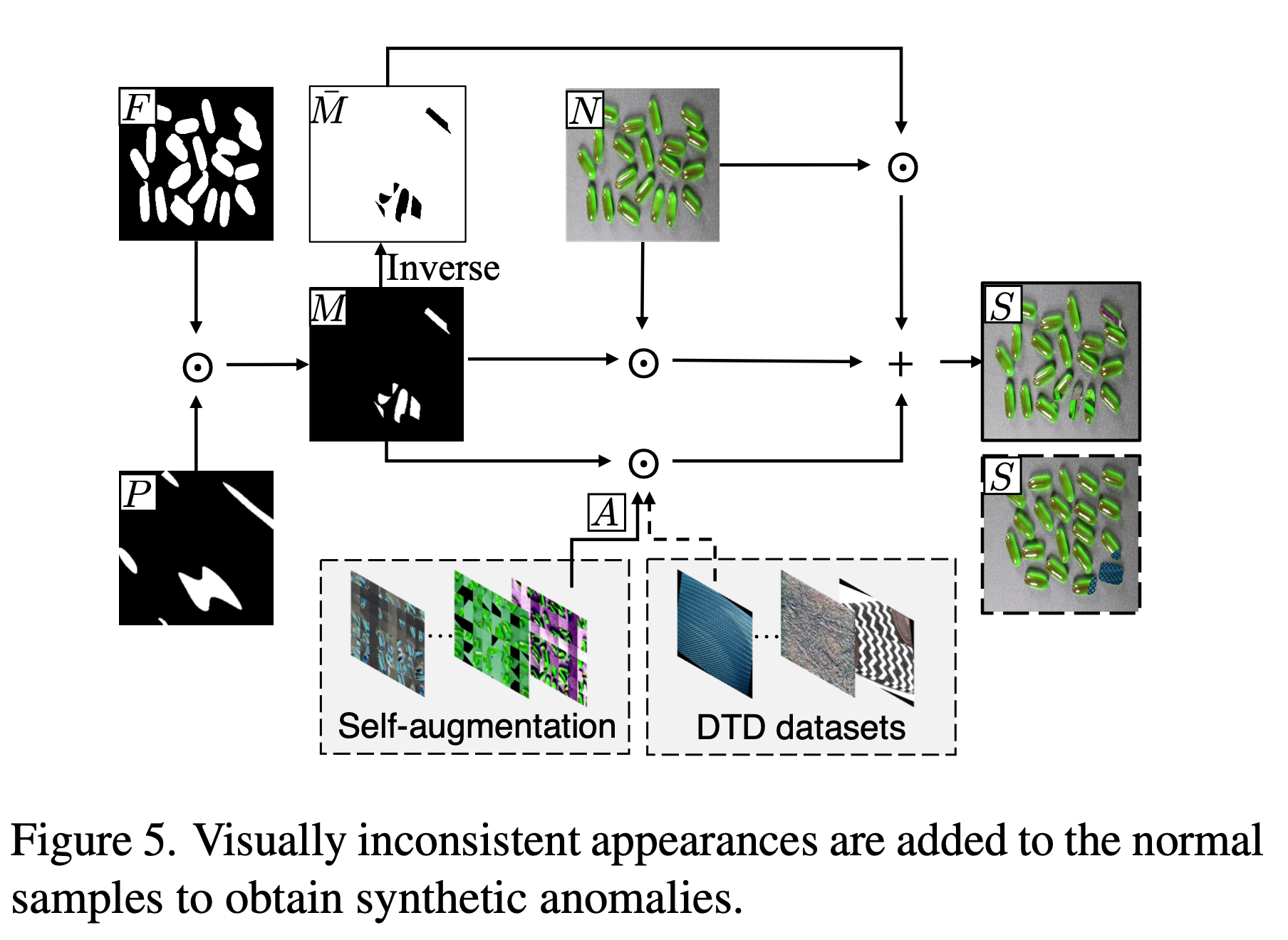
- 이상 영역의 위치를 지정하기 위해 불규칙하게 생성된 Perlin Noise P와 이미지의 오브젝트(object foreground) F와 element-wise product하여 Noise Mask M을 구합니다.
- Texture Dataset에 대해서는 이미지의 오브젝트가 없음으로 무작위로 영역(Random part)을 F로 설정하여 Noise Mask M을 구합니다.
- 이상 영역의 패턴(A)을 주기 위해 self-augmentation과 DTD Dataset에서 뽑은 샘플을 사용한다.
- M과 A 그리고 정상 샘플(N)을 활용해 합성 이상 샘플(S)을 만든다.
Experiments
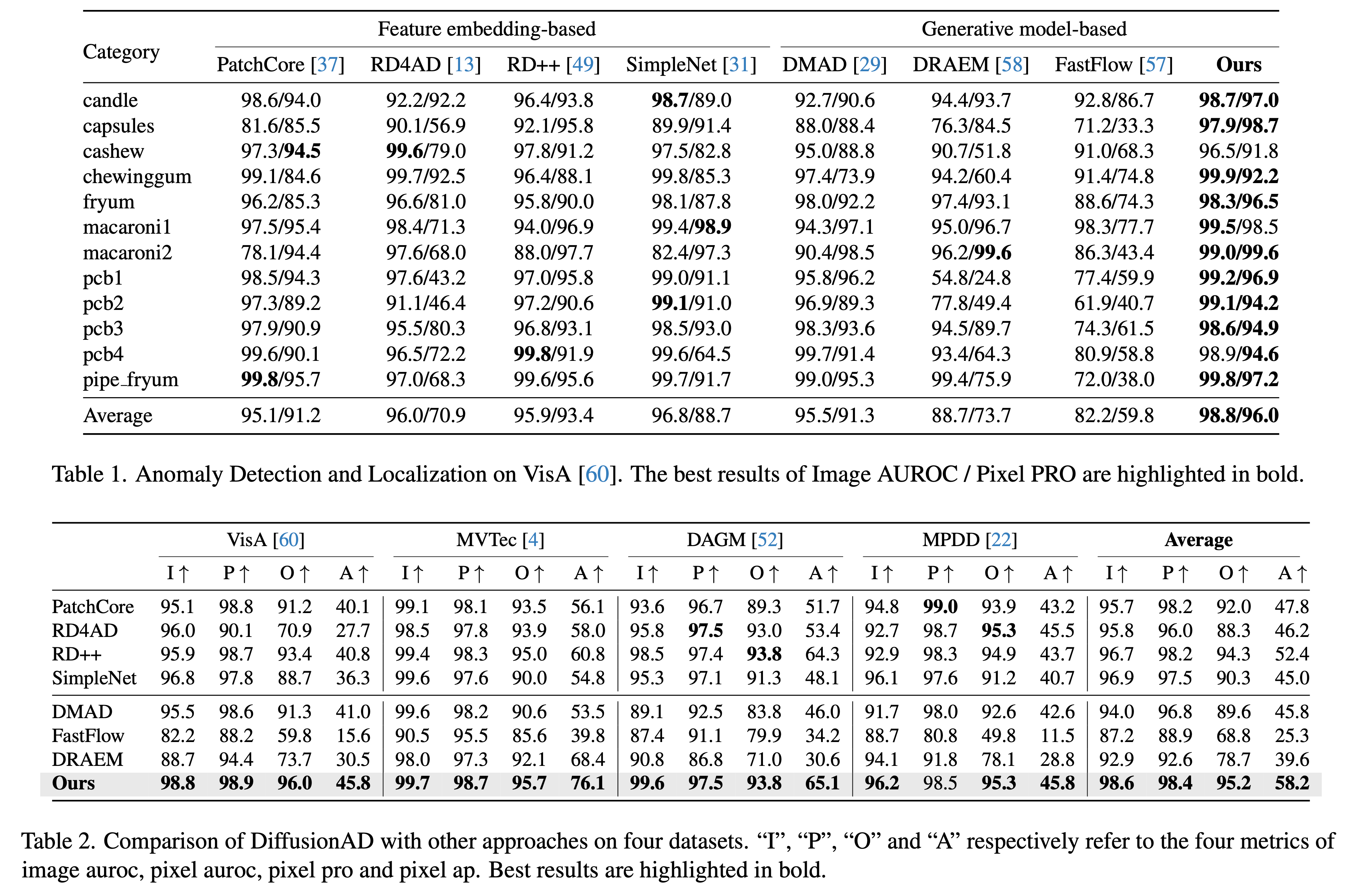

[ref]
Comment