
서론
이 장은 Convolution의 연산방식과 Depthwise Convolution, Grouped Convolution의 특징에 대해 알아본다. 또한 Convolution을 바탕으로 다양한 모델들이 등장하게 되는데, VGG, AlexNet, MobileNetV1, 2, ResNet들의 특징을 간략하게 알아본다.
목차
- Convolution
- Depthwise Convolution
- Grouped Convolution
- Alex Net
- VGG Net
- InceptionV2
- MobileNetV1, V2
- ResNet
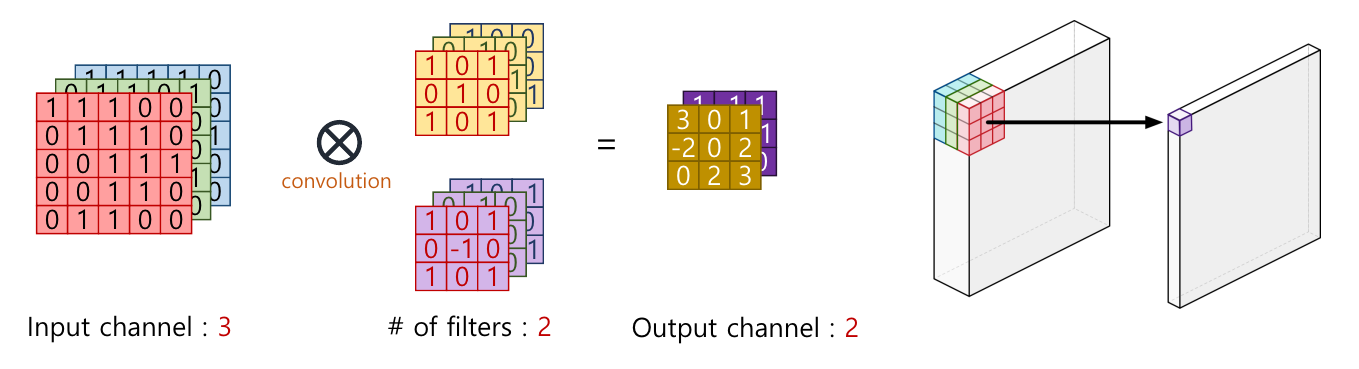
Convolution
- Input 채널의 갯수 = filter(kernel) 채널의 갯수
- 아래 그림에서 Input(이미지)의 채널의 수가 3이면 filter의 채널 수 3
- filter의 갯수(Number of filters) = output 채널 수
- 아래 그림에서 filter의 갯수는 2개이면 output 채널 수 2
- 아래 그림을 보면 Input feature와 커널들이 element-wise 곱으로 연산하여 최종적으로 한 개의 값으로 모두 더해짐
About Kernel
Weight sharing에 들어가기 전에 커널의 생성 방식에 대해서 예를 들어서 설명하겠습니다.
output_channel=1로 설정한 상태에서 일반적인 Convolution은 RGB 3개의 채널을 갖는 이미지가 들어왔을 때, 커널의 갯수는 1개가 됩니다.(# of kernel == output channel의 갯수) 그리고 1개의 커널에는 이미지가 3개의 채널을 가지고 있기 때문에 3개의 채널이 있는 커널 1개가 생성됩니다.
1개의 커널에 대한 각 채널들은 이미지가 가지고있는 각각의 채널에 대응됩니다.
이미지의 Red채널에 대응되는 1개의 커널에 있는 채널 1개, 이미지의 Green채널에 대응되는 1개의 커널에 있는 채널 1개, 이미지의 Blue채널에 대응되는 1개가 됩니다. 때문에 총 3개의 채널을 갖는 1개의 커널이 생성됩니다.
Convolution의 Weight Sharing 의미
이때 가중치 공유를 한다는 말은 1개의 채널에 대응되는 커널의 필터가 이미지를 stride값만큼 이동하여 처음부터 끝까지 훑습니다(convolution 연산). 이때 동일한 가중치로 convolution 연산이 진행됩니다 즉, 고정된 가중치로 훑는다는 뜻입니다. 그리고 이 커널에 대한 가중치는 forward때 변경되지 않고 backward에서 변경됩니다. 따라서 1개의 커널이 가지고 있는 각 채널에 대해서는 서로가 다 다른 가중치가 다른값을 가집니다.
Convolution의 Weight Sharing 이점
- 하나의 이미지에 특정 영역에 있는 feature를 잘 찾는다는 것은 이 feature를 잘 찾는 weight, bias가 잘 학습되었다는 것을 의미
- 한 장의 이미지에 하나의 feature만 있는 것이 아닌 여러 개의 feature가 있고 입이라는 feature를 찾아내는 detector가 잘 학습되어졌다고 가정
- weight를 sharing하지 않는다면 각 region 또는 pixel마다 다른 weight값을 사용해야 한다는 것이 되므로 이는 연산량이 엄청나게 증가
- 같은 입(mouse)이라 하더라도 학습된 weight들이 다 다름으로 우리가 볼 때는 같은 입이지만 모델의 관점에서는 서로 다른 객체라고 출력하는 문제도 발생
Weight Sharing Besides restricting ourselves to only local connections, there is one other optimization we can make: if we wanted to detect a feature (say, a horizontal edge), we can use the same detector on the bottom-left corner of an image and on the top right of the image. That is, if we know how to detect a local feature in one region of the image, then we know how to detect that feature in all other regions of the image. In neural networks, "knowing how to detect a local feature" means having the appropriate weights and biases connecting the input neurons to some hidden neuron. We can therefore reuse the same weights everywhere else in the image. This is the idea behind weight sharing: we will share the same parameters across different locations in an image.
https://www.cs.toronto.edu/~lczhang/360/lec/w04/convnet.html
Depthwise Convolution
코드(Pytorch): nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, groups=32)
위의 코드가 주어졌을때에 대해서 알아보겠다.
특징
- input_channel과 output_channel의 크기가 같다.
- groups라는 인자는 32개의 입력채널에 대해 32개의 그룹으로 나누어서 계산하라의 의미 → 1개의 그룹당 1개의 채널가지고 있으라는 의미가 된다. 각 그룹당 1개의 커널이 맵핑되어 32개의 출력채널이 이뤄진다.
Grouped Convolution
코드(Pytorch): nn.Conv2d(in_channels=32, out_channels=16, kernel_size=3, stride=1, padding=1, groups=16)
위의 코드가 주어졌을때에 대해서 알아보겠다.
특징
- 다음과 같은 코드는 Grouped Convolution이라 불린다.
- 만약 group이 16이면 32개의 입력채널에 대해 16개의 그륩으로 나누어 계산하라의 의미 → 1개의 그륩당 2개의 채널을 가지고 있으며 2개의 채널에 대해 2개의 채널을 가진 1개의 커널을 적용한다.
- 그룹된 2개의 채널중에서 첫번째 채널은 2채널로 구성된 커널 1개가 각각 독립적으로 Convolution연산을 진행한다.(첫번째 채널은 2개의 채널로 구성된 커널이 가진 첫번째 채널과 연산되고 두번째 채널은 2개의 채널로 구성된 커널이 가진 두번째 채널과 연산된다.)
- 그리고 각 연산이 끝나면 2개의 feature map 이 나오는데 이를 최종적으로 더해주어 1개의 feature map을 출력한다.
코드(Pytorch): nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, groups=16)
- 만약 출력 채널이 32인 경우에 대해서 grouped conv을 봐보자.
- group이 16임으로 1개의 그륩당 2개의 채널을 가지고 있는데, 2개의 채널을 1개의 커널로 연산을 할 경우 output이 1개만 나오게 된다. 즉, group이 16개임으로 output feature map의 갯수가 16개가 되어 out_channels=32의 요구에 충족되지가 않는다.
- 따라서 1개의 그륩에있는 2개의 채널을 2개의 커널로 연산하여 2개의 output을 낸다고 보면된다.
Alex Net
- 병렬처리를 통한 Conv layer를 구성해 계산하는 것에 의의
VGG Net
- 어떤 크기의 필터를 사용하는 것이 좋은가에 대한 솔루션을 제공한다.
- Stride가 1일 때, 3차례의 3x3 Conv 필터링을 반복한 특징맵은 한 픽셀이 원본 이미지의 7x7 Receptive field의 효과를 볼 수 있다.
- 따라서 3x3 크기의 필터를 여러번 사용하는 것은 5x5 또는 7x7 크기의 필터와 같은 receptive field를 갖기 때문에 3x3필터만 쓰면 된다.
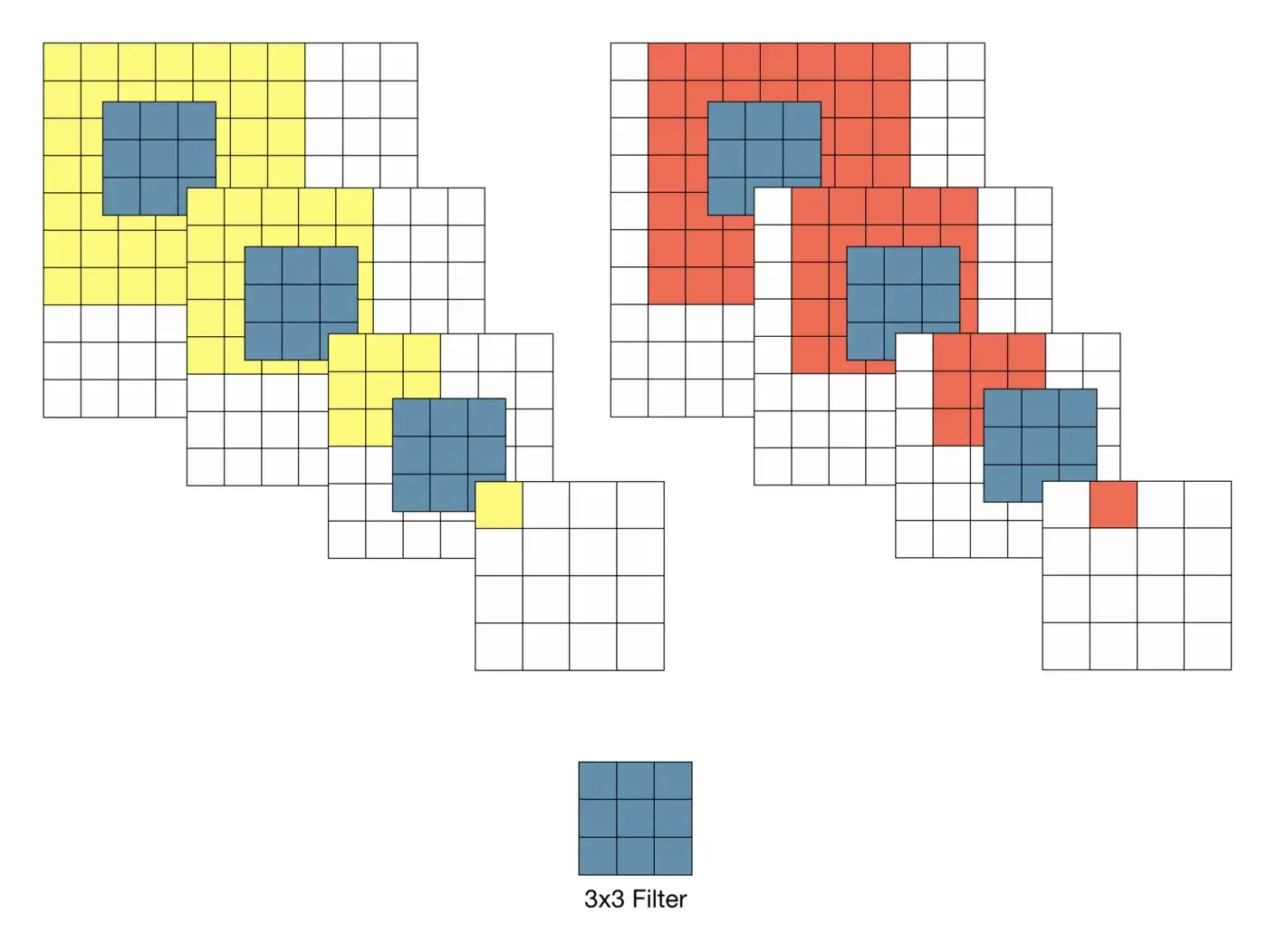
- Using (3x3) filter Example 1
- step1. (10x10xC)image → (3x3xC) filter 1개 (padding=0, stride=1) → (8x8) output
- step2. (8x8) input → (3x3) filter 1개 → (6x6) output
- step3. (6x6) input → (3x3) filter 1개 → (4x4) output
- Using (7x7) filter Example 2
- step1. (10x10xC)image → (7x7xC)filter 1개 (padding=0, stride=1) → (4x4) output
- Using (3x3) filter Example 1
- 3x3 필터를 여러번 사용하는 것은 더 큰 필터를 조금 사용하는 것 보다 더 Non-linearity가 많아지는 장점이 있다.
- 위 예시(Example 1)보면 3x3 Convolution Layer를 3번 지나게 됨으로 Relu 연산이 3번 일어남
- 그러나 Example 2는 Conv Layer를 1번만 지남으로 Relu 연산이 1번 일어남
- 파라미터 수의 감소 → regularization(일반화) 증가
- (7x7xC) vs 3x(3x3xC) = 49 vs 27
- Parameter가 많으면 input에 대해서 모델이 sensitive하게 반응하게 된다.(과적합)
In short, large weights lead to amplifications of the differences between similar inputs, making the network sensitive, and hence overfitting, to its training data. In contrast, small weights reduce the differences between similar inputs, and hence provides improved generalization.
Comment