
Cite
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked AutoEncoders
http://arxiv.org/pdf/2002.05709v3
- Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie
- 출간일: 2023년 1월 2일
- 인용횟수: 554회
Abstract
2020년대 초반 개선된 아키텍처와 더 나은 표현 학습 프레임워크에 의해 Vision Recognition은 빠르게 성장하였다.
그 중 2020년대 등장한 ConvNextv1은 ImageNet 데이터를 활용한 Supervised Learning을 사용하는 방식에 적합하게 만들어졌다.
최근에는 라벨이 필요없는 자기지도 학습(self-sumpervsied learning), 특히 Masked AutoEncoders(MAE)라는 방법이 주목받고 있다.
그러나 ConvNextv1에 자기지도 학습을 적용했을 때 성능이 좋지 못했다.
우리는 이를 해결하기 위해 ConvNextv2라는 새로운 모델을 제안한다.
self-supervsied learning을 위한 Fully convolutional masked auto-encoder frame-work와 feature map간의 표현력을 개선하기 위해 GRN(Global Response Normalization)이라는 기술을 추가해 성능을 끌어올렸다.
이 모델은 ImageNet classification, COCO detectionn, ADE20K segmentation 등 다양한 분야에서 우수한 성능을 보인다.
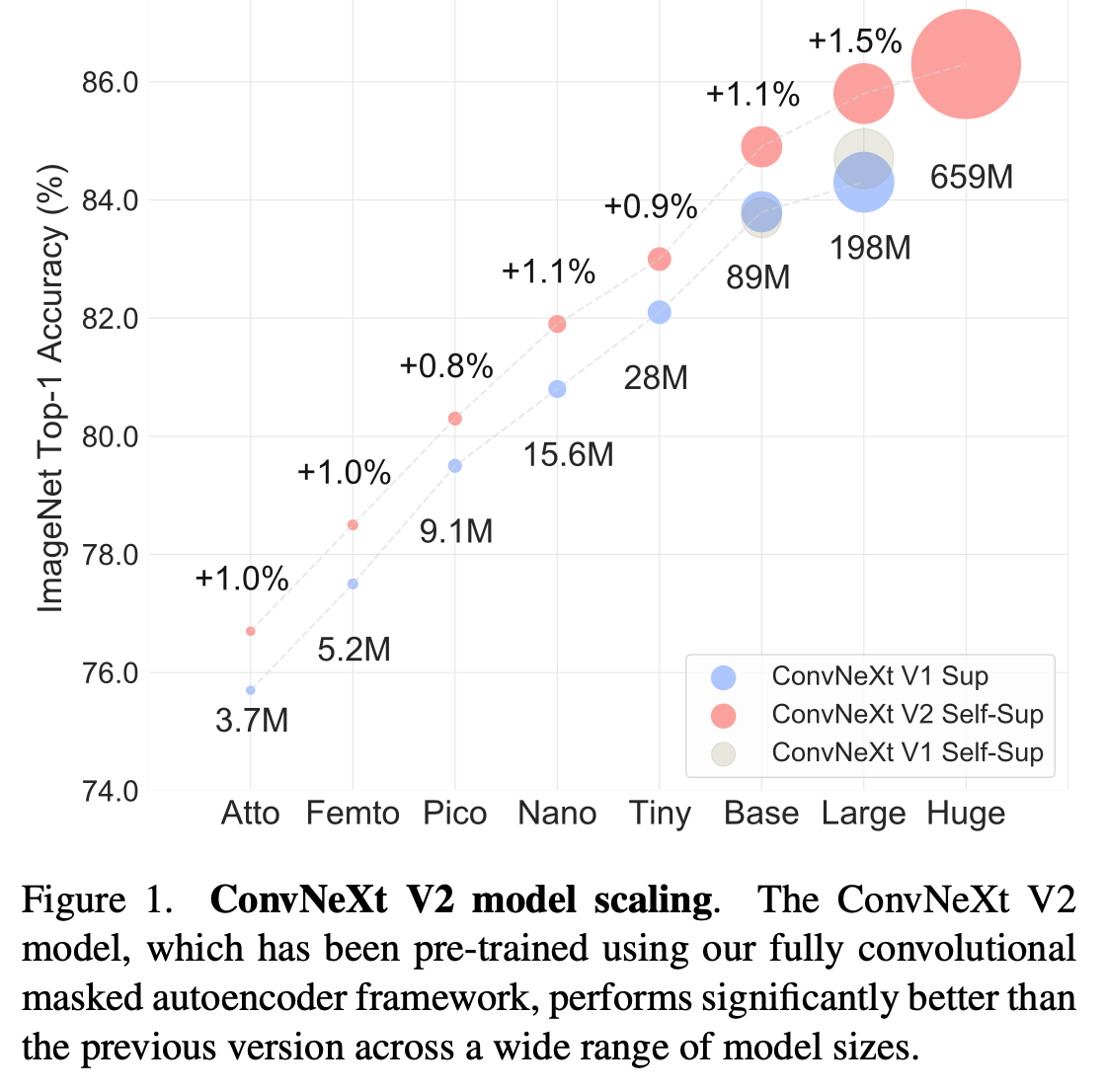
우리는 다양한 모델 크기를 지원한다. 3.7M(370만) 파라미터부터 650M(6억 5천마)파라미터까지 다양한 사전 학습 모델을 제공하며, 각각 ImageNet에서 최고 성능(76.7%-88.9% top-1 정확도)을 달성했다.
Introduction
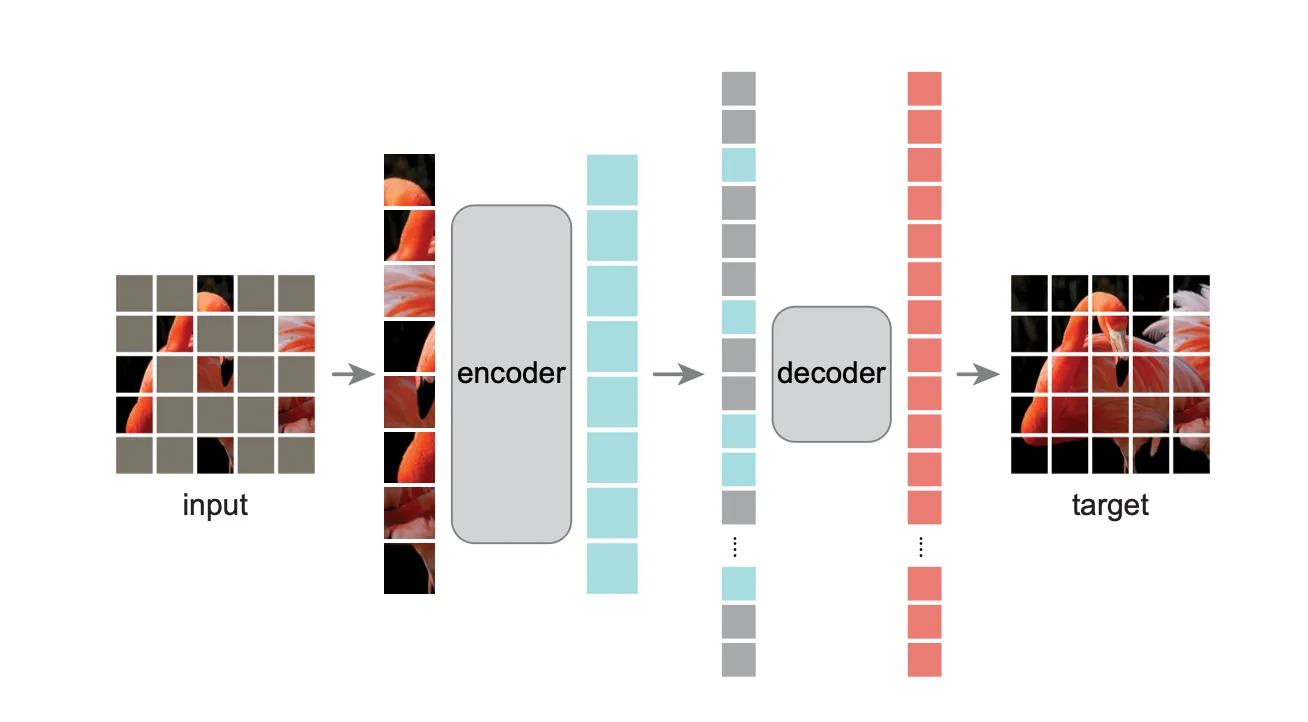
MAE는 Transformer 아키텍처를 위해 설계되었다.
Transformer의 시퀀스 처리 방식
- Self-Attention을 통해 각 패치(토큰)간의 관계를 학습
- 모든 패치 간의 상호작용을 계산하여 글로벌 패턴을 학습
ConvNext의 처리 방식
- Convolution Filter를 사용하여 조밀하게 이동하며 Local area를 처리
- 전체 이미지에서 지역적으로 조밀한 영역을 반복하여 locality를 중심으로 학습함
- 쉽게말해 CNN특성상 위치 정보보다는 이미지간의 섬세한 패턴과 특징을 중심으로 학습함
이러한 이미지의 위치적 정보를 중심으로 학습하는 Transfomer모델에 사용하던 MAE는 CNN에서 사용하기에 적합하지 못하다는 것이였다.
이를 해결하기 위해
- Sparse Convolution 도입
- Transformer Decoder를 ConvNext Block으로 대체
- GRN 레이어 추가
Preliminary
MAE
- 이미지를 패치 형태로 분할하고 random하게 패치들을 Masking
- Encoder에서는 unmask되지 않은 visible patch만 사용하여 특징들을 학습
- Decoder에서는 Encoder에서 학습한 특징들과 마스크된 패치들이 입력으로 들어가 원래 이미지를 복원
- Decoder에서 마스킹된 이미지 위치 정보를 주기 위해 Positional Embeding 사용

Sparse Convolution
- 희소 데이터를 효율적으로 처리하기 위한 합성곱 연산
- Point Cloud와 같은 점 구름데이터 처럼 대부분의 공간은 비어있고 몇몇 중요한 데이터 포인트만 학습하도록 하는 기법.
- 따라서 데이터가 있는 위치를 탐지하고 해당 위치(Active Sites)에서만 Convolution 연산 수행
- 자율주행에서 물체 감지 또는 3D CT등에서 대부분의 공간이 비어있는 데이터를 처리하는데 적합
Method(FCMAE)
- Fully Convolutional Masked AutoEncoder framework
- 기존 Transformer에서 사용하던 MAE를 Convolution에서 사용하기 위해 고안된 프레임워크를 의미
- Masking,
Masking
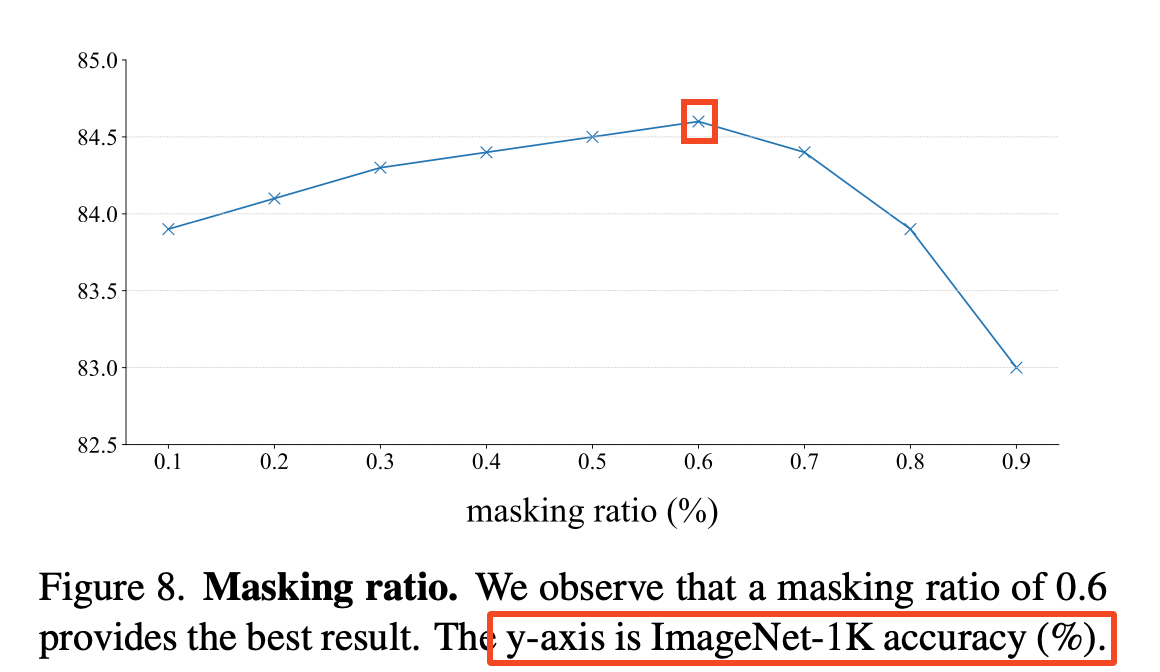
- 32x32패치에서 60%를 무작위로 마스킹(최적의 값)
- Downsampling의 마지막 단계에서 진행
- 최소한의 데이터 증강을 사용하며 Random resized cropping을 진행
Encoder Design
- Transformer계열에서는 마스킹된 배치를 아이에 제거하고 visible한 패치만 인코더의 입력으로 줌
- 그러나 CNN기반의 ConvNext는 2D이미지를 그대로 유지하며 처리하는 방식으로 마스킹된 패치를 제거하면 이미지의 구조가 깨져버림
- 따라서 마스킹된 영역도 같이 끼워줄 수 밖에 없는데 단순히 마스킹된 패치의 주변 정보만으로 복사하거나 쉽게 예측해서 푸는 문제가 발생함(shortcut 문제)
- 이를 해결하기 위해 Sparse Convolution을 사용
- 마스킹된 데이터를 회소 데이터(Sparse Data)로 간주하여 마스킹된 영역은 비어있고 visible patch만 남아있는 sparse한 데이터라고 생각
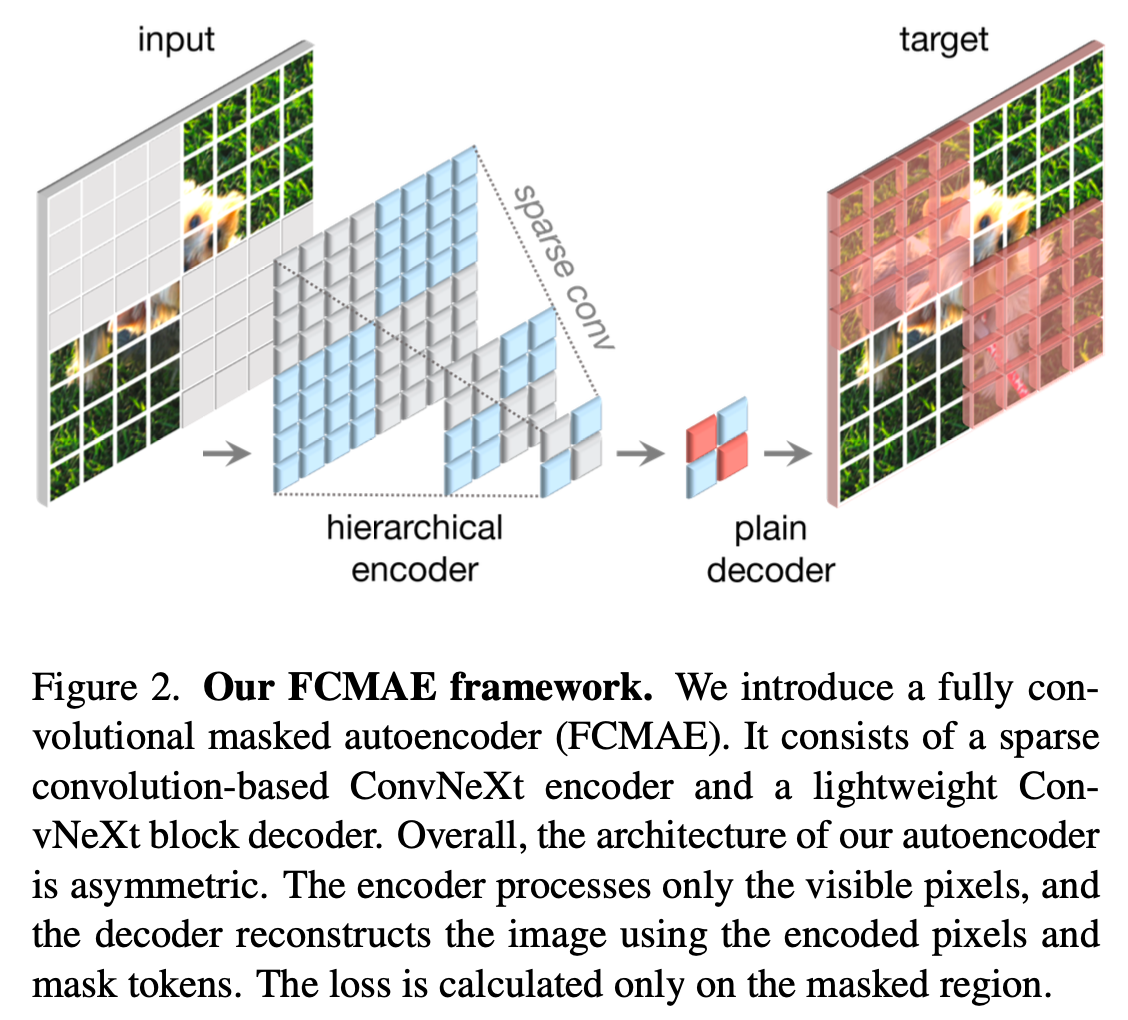
- 학습단계: ConvNext의 Normal Convolution을 Sparse Convolution으로 바꿔서 사용
- 추론단계: 학습이 끝나면 Sparse Convolution을 Normal Convolution으로 다시 바꿈
Decoder Design
- 기존 ConvNext의 블록을 디코더로 사용
- 인코더는 계층적 구조를 가짐으로 크고 복잡한 구조로 설계되어 decoder는 가볍게 설계
- 이러한 구조적 차이로 비대칭(asymmetric architecture)를 가짐

Comment