
Confusion Matrix
- 양성이
정상음성이비정상이라 가정하겠다. - 여기서 중요한 것은 데이터가 들어왔을 때 그 데이터가 어떤 데이터인지 파악하는 것이 중요하다.
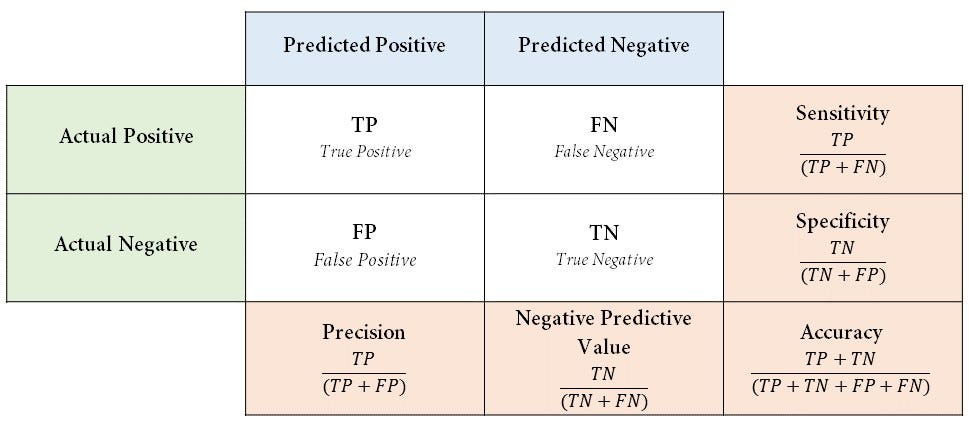
TN ( True Negative)
- 모델이 비정상(Negatvie)이라고 예측했는데 잘 맞춘(True) 경우이다.
- 어떤 데이터가 들어왔는데
- 모델이 비정상(Negative)이라고 예측했다.
- 그런데 잘 맞췄네(True)?
즉 비정상 데이터를 모델이 비정상이라고 예측했으니 잘 맞춘 경우인 것이다.
FP(False Positive)
모델이 양성(Positive)라고 예측했는데 틀린 경우다.
- 어떤 데이터가 들어왔는데
- 모델이 정상(Postive)이라고 예측했다.
- 그런데 틀렸네?(False)
즉 비정상 데이터가 들어왔는데 모델이 정상이라고 예측했으니 틀린 경우인 것이다.
FN(False Negative)
- 모델이 비정상(Negative)라고 예측했는데 틀린 경우다.
- 어떤 데이터가 들어왔는데
- 모델이 비정상(Negative)이라고 예측했다.
- 그런데 틀렸네?(False)
즉 정상 데이터가 들어왔는데 모델이 비정상이라고 예측했으니 틀린 경우인 것이다.
TP(True Positive)
모델이 정상(Positive)이라고 예측했는데 맞춘(True) 경우다.
- 어떤 데이터가 들어왔는데
- 모델이 정상(Positive)이라고 예측했다.
- 근데 잘 맞췄네?(True)
즉 정상 데이터가 들어왔는데 모델이 정상이라고 예측했으니 잘 맞춘 경우인 것이다.
Specificity(특이도)
- 실제 비정상을 모델이 비정상이라고 판단한 비율이다.
- 분자는 실제
비정상 데이터를 모델이 비정상이라고 잘 맞춘 경우가 와야한다(TN) - 분모는 실제
비정상 데이터 전체가 와야한다. - 즉, 실제
비정상 데이터를비정상 데이터라고 모델이 예측한 경우와 실제비정상 데이터를 모델이정상 데이터로 예측한 경우두 가지가 더해줘야 비정상 데이터의 전체 집합이 되는 것이다.
FPR(False Positive Rate)
- 실제 비정상 데이터를 모델이 정상으로 판단한 비율이다.(미검율)
- 분자는 비정상 데이터를 모델이 정상이라고 판단한 경우가 온다(FP)
- 분모는 비정상 데이터전체 집합이 와야함으로 기존 FP에
비정상 데이터를 모델이비정상 데이터라고 예측한 경우가 와야 한다.
Recall
- 실제 정상인 데이터를 모델이 정상이라고 판단한 비율이다.
- 분자는 정상 데이터를 모델이 정상이라고 판단한 경우가 온다(TP)
- 분모는 정상 데이터에 대한 전체 집합이 와야 함으로 TP에
정상 데이터를 모델이비정상 데이터라고 예측한 경우가 와야 한다.(FN)
과검율
실제 정상 데이터를 비정상으로 판단한 비율로 본인은 과하게 검사한 비율로 이해했다.
- 분자는 실제 정상 데이터를 비정상으로 판단한 경우가 온다.
- 분모는 정상 데이터에 대한 전체 집합이 와야 함으로 TP에
정상 데이터를 모델이비정상 데이터라고 예측한 경우가 와야 한다.(FN)
Accuracy(정확도)
Precision
모델이 어떤 데이터를 정상(Positive)이라고 예측한 것 중에 실제 데이터가 정상(Positive)인 비율
- 예측한 것 중에서 얼마나 많이 맞았는가?
- F - score: Precision, Recall의 조화 평균으로 모델의 성능을 측정하는 하나의 지표로 정밀도와 재현율을 둘다 고려하였음
- \(F\text{-score}\)의 \(\beta\)1이 되는 식을 \(F_1\text{-score}\) 라고 한다.
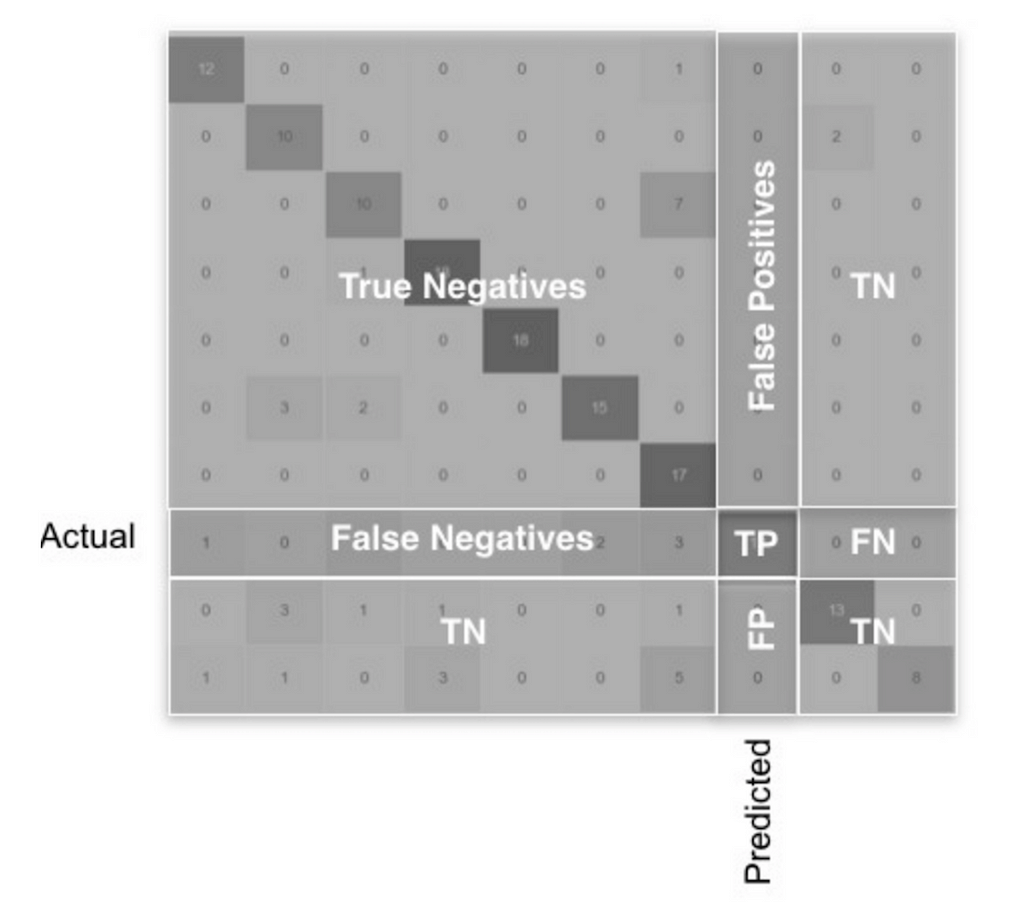
Example
- 아래 표는 음성의 비율이 10 : 90으로 불균형 클래스를 이루고 있다. (각 행을 다 더함)
- 위 표에서 정확도는 92%인데 실제 양성 케이스 10건중에서 음성으로 예측한 케이스가 무려 50%에 해당한다.

- 해석해보면 실제로는 100명 중에서 10명의 환자는 양성(정상)이고 90명의 환자는 음성(비정상)중에서 정상인 환자를 기준으로 보면 실제로는 정상인 10명 환자 중 5명의 환자는 음성(비정상)이라고 한 것이다.
- 암 진단을 예시로 보면 실제 암환자를 분류하는 Task로 볼때 실제 10명 중 5명이 암이라고 정확히 진 단 받았지만 나머지 5명은 암이 아니라고 잘못 진단 받은 것이다.
- 또한 실제 암이 아닌 환자 90명 중 87명은 암이 아니라고 정확하게 진단 받았지만 3명은 암이 아니라고 잘못 진단 받은 것이다.
- 따라서 이는 92%의 정확도를 가진 모델이라고 보기 어렵다.
- 이 때 F1 score를 보기 위해 Recall과 Precision 을 구해보자.
- F1 score는 아래와 같다.
- F1 score는 전체 예측한 것 중에 실제 예측을 잘 한 것과 전체 실제중에서 실제 예측을 잘한 것에 대한 평균이라는 것이다.
Multiclassification Confusion Matrix
Example
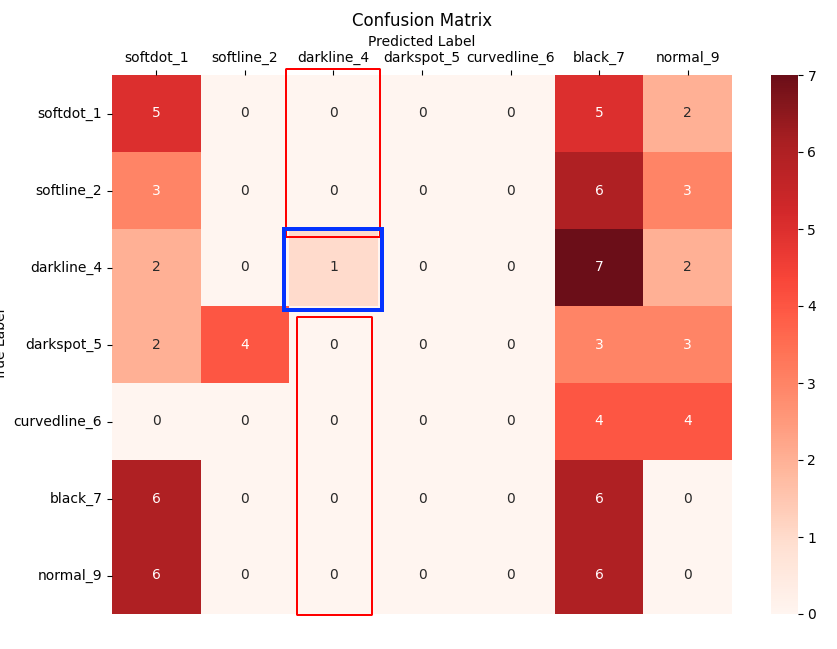
다음과 같은 Confusion Matrix가 있다고 가정하고 darkline_4라고 되어있는 것이 정상(Postive)이고 나머지를 비정상(Negative)라고 할 때 darkline_4의 과검율과 FPR(미검율)을 구해보겠다
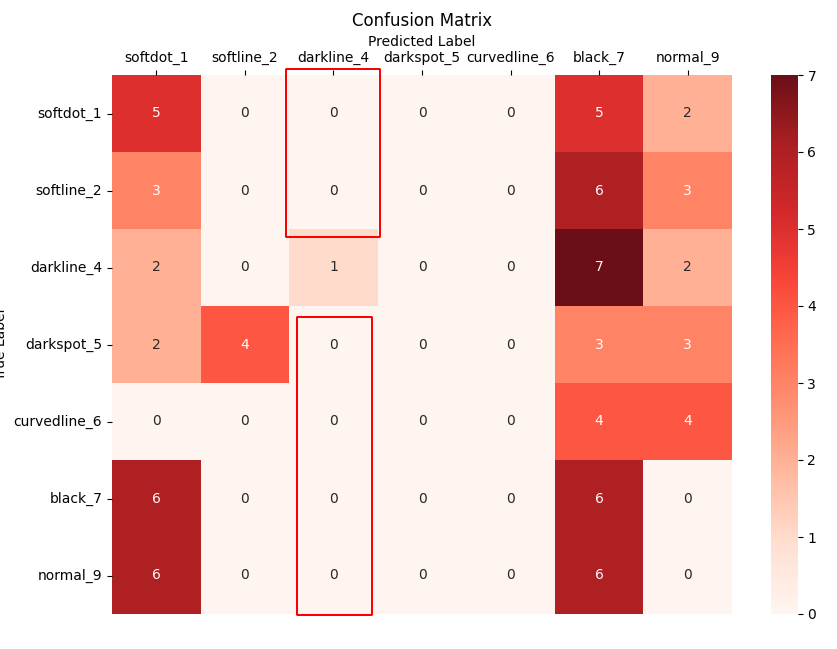
과검율(1-Recall)
과검율의 의미는 과하게 검출했다는 의미로 실제 정상인 데이터를 비정상 데이터로 검출한 비율을 말한다.
그럼 분모는 실제 정상 데이터에 대한 전체 집합이 와야 하며 분자는 실제 정상인 데이터를 비정상 데이터로 검출한 갯수 (FN)가 와야한다.
따라서 분모는 실제 정상인 데이터를 정상이라고 예측한 갯수(TP) + 실제 정상인 데이터를 비정상이라고 예측한 갯수(FN)
즉 분자에 해당하는 FN은 아래 파란색 박스의 값을 더한 것이 된다.
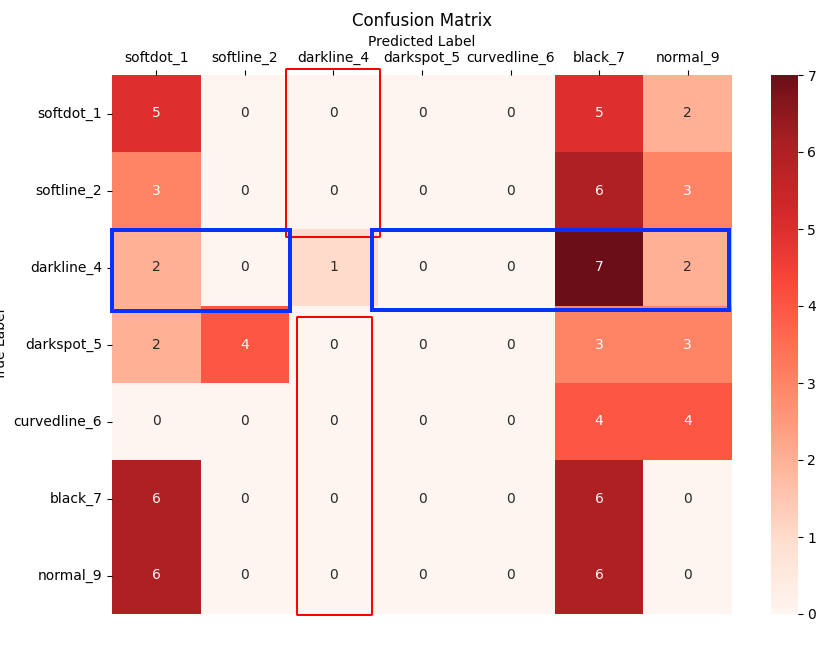
그럼 분모에 해당하는 TP는 아래 파란색 박스가 된다.
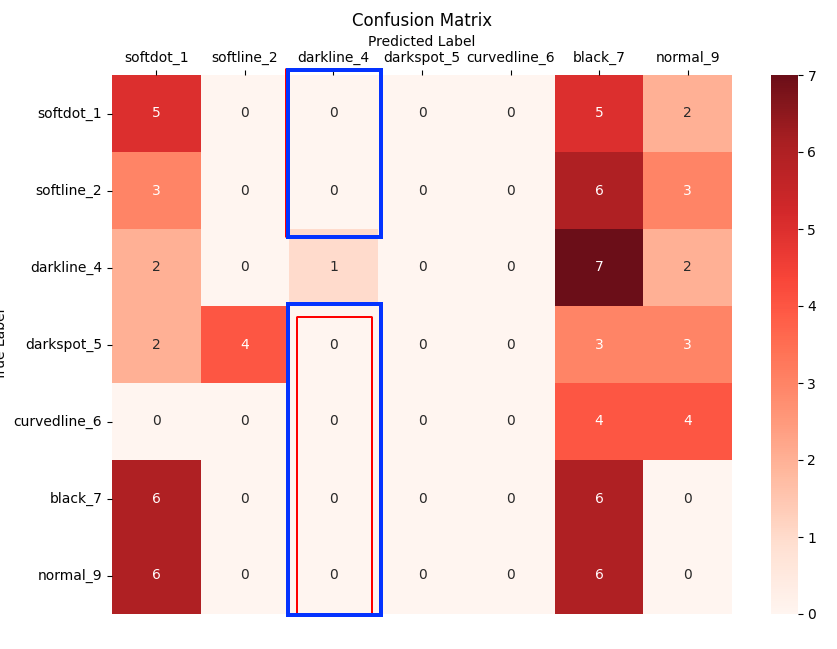
FPR(미검율)
미검율은 실제 비정상 데이터를 모델이 정상 데이터로 예측한 것을 말한다.
따라서 분자에는 실제 비정상 데이터를 모델이 정상 데이터로 예측한 것인(FP)가 분자로 온다.
분모에는 실제 비정상 데이터 전체 집합이 와야 함으로 기존 FP 더하기 비정상 데이터를 모델이 비정상으로 예측한 것인(TN)이 와야한다.
FP는 아래 파란색 박스와 같다.
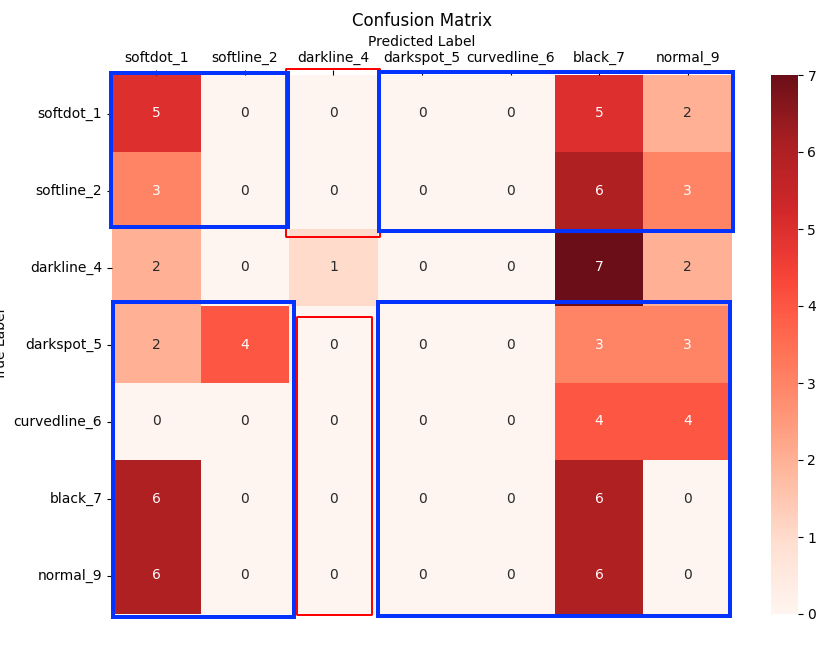
TN은 아래 파란색 박스와 같다.
Comment