
서론
이 장은 CNN의 특성인 Translation Equivariance와 Translation Invariance에 대해 설명한다.
목차
Translation Equivariance/ Invariance
Translation Equivariance
- 함수의 입력이 바뀌면 출력도 바뀐다.
- 즉 입력의 위치가 변하면 출력도 동일하게 위치가 변한채로 나온다는 뜻이다.
Translation Invariance
- 함수의 입력이 바뀌어도 출력은 그대로 유지되어 바뀌지 않는다.
- 위치적 정보를 담고 있지 않는다. 입력의 위치가 변해도 출력은 변하지 않는다는 의미로, 강아지 사진에 강아지가 어느 위치에 있건 상관없이 그냥 강아지라는 출력을 하게 된다는 의미다.
- Max-Pooling은 여러 픽셀 중 최대값을 가진 픽셀 하나를 출력하기에 서로다른 [1, 0, 0], [0, 0, 1] 두 입력을 넣어도 동일한 1을 출력 → 입력이 바뀌어도 출력이 바뀌지 않음
- 즉, 이는 이미지안에 있는 물체가 있기만 하면되지 물체의 위치가 중요하지 않음(Invariant한 특징)
- Convolution연산의 Equivariance특성에 parameter공유를 추가했을 때 Invariance를 갖는다
- parameter를 공유하지 않으면 위치마다 다른 필터를 사용한다.
- 그러면 이미지 상/하단에 위치한 두 마리의 토끼가 있다하자
- 하단에 있는 토끼만 네트워크가 학습 했다면 이미지 상단에 위치하는 토끼의 경우 처음 보는 특성으로 판단한다 → 토끼로 인식하지 못하여 토끼가 나와야 하는데 다른 값이 출력될 수 있다.
- 이는 입력과 상관없이 출력이 같야하는 invariant특징을 갖지 못한다.
- parameter를 공유하지 않으면 위치마다 다른 필터를 사용한다.
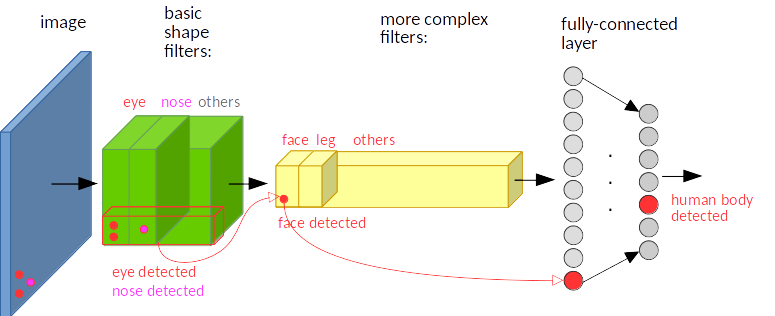
Example 1
- Figure 1. 을 보면 이미지 왼쪽 하단에 eye, nose채널이 각각 필터에 할당되어진다. 그리고 이것들이 노란색으로 칠해진 더 깊은 conv layer를 통해 Activation Function으로 부터 face채널 왼쪽 하단에서 큰 값으로 출력 된다.
- 입력에서의 특징 위치와 동일한 위치에서 출력(노란색 Conv) → Translation Equivariant
- 그러나 FC Layer를 지나고 softmax로 가장 높은 확률의 값을 출력하는 부분에서는 특징의 위치와 상관없이 human body를 출력한다.
- 이는 입력에 위치에 상관없이 human body 출력 → Translation invariant
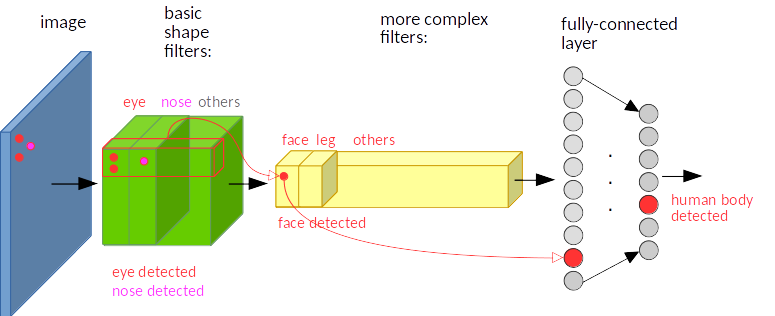
Example 2.
- Figure 1. 과 비슷하나 eye, nose특징이 왼쪽 상단에 존재하는 것만 다르다.
- CNN자체를 label의 확률을 출력하는 하나의 커다란 합성함수로 봐보자
- 이미지의 서로 다른 위치에 있는 특징을 입력으로 넣으면 conv연산은 translation equivarance하기에 feature map에서 서로 다른 위치에 배치시킨다.
- 즉, 여기까지는 Invariant하지 않는다.
- 그러나 Conv layer를 지나 FC레이어와 softmax를 거친 결과는 특징의 위치와 상관없이 무조건 특징이 포함된 라벨의 확률 값을 출력한다.
- 여기서 Invariant 해진다.
- Convolution 연산의 equivariance한 특성과 parameter를 공유하는 덕분에 CNN 자체가 Translation Invariance 특성을 갖게 된다.
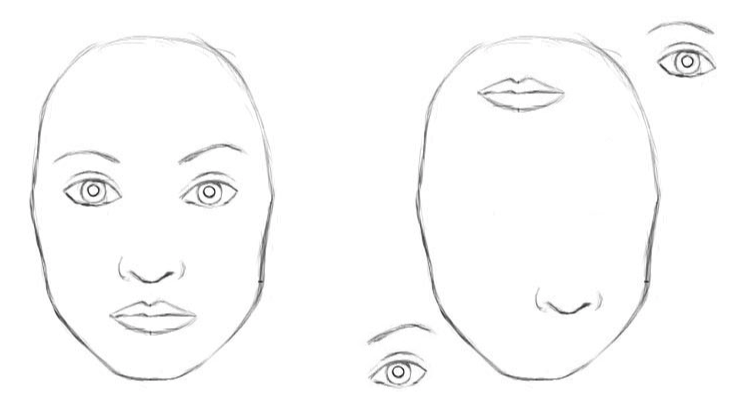
Translation Invariance의 단점
- 각 특징들의 위치 정보가 중요한 경우 Translation Invariance를 막는 CNN 구조들이 필요하다.
- Figure 3. 처럼 얼굴 안에 있는 안 눈, 코 입이 있는 사진을 학습할 때 눈이 아래에 있는 경우에 대해 얼굴로 판단하면 안 된다.
- 이런 경우 Locally connected Layer는 일반적인 Convolution 연산과 동일하지만 parameter를 공유하지 않음
- 각 위치마다 다른 필터를 사용하기 때문에 동일한 특징이라도 위치에 따라 다른 필터들이 학습
- 이미지의 위치 정보가 포함됨으로 결과적으로 Translation Invariance특성을 버리게 됨
- Max-pooling을 사용하면 small Translation Invariance특성을 유지할 수 있음
- 아래 이미지는 극단적인 예시이며 깊은 CNN의 구조일 수록 눈, 코 입 따로만 특징을 배워 결단을 내리지 않고 더 큰 형태에 대한 특징을 뽑아냄 → CNN구조를 어떻게 하느냐에 따라 아래 케이스는 충분히 해결 가능
[참조]
https://seongkyun.github.io/study/2019/10/27/cnn_stationarity/
Comment