
서론
이 장은 Open Ai에서 발표한 CLIP논문 에 대해 설명한다.
목차
- CLIP (contrastiv Language-Image Pre-Training)
- Training Details
- Inference(Zero-shot prediction)
- Inference(Prompt Engineering)
- Inference Code
CLIP (contrastiv Language-Image Pre-Training)
Data
- 이미지를 설명하는 텍스트를 결합한 image-text par를 입력으로 사용
- 논문에서는 4억개의(image, text) pair를 인터넷으로 부터 수집해 학습
Advantage of using Image-Text pair on Web Based
- Data set 크기를 무한히 키울 수 있음
- Web-Based image-text pair을 사용하여 별도의 라벨링 작업이 필요없음
- Vision representation만을 학습하는게 아니라 Language representation을 함께 학습하여 Downstream task에서 일반화된 특징 학습이 가능
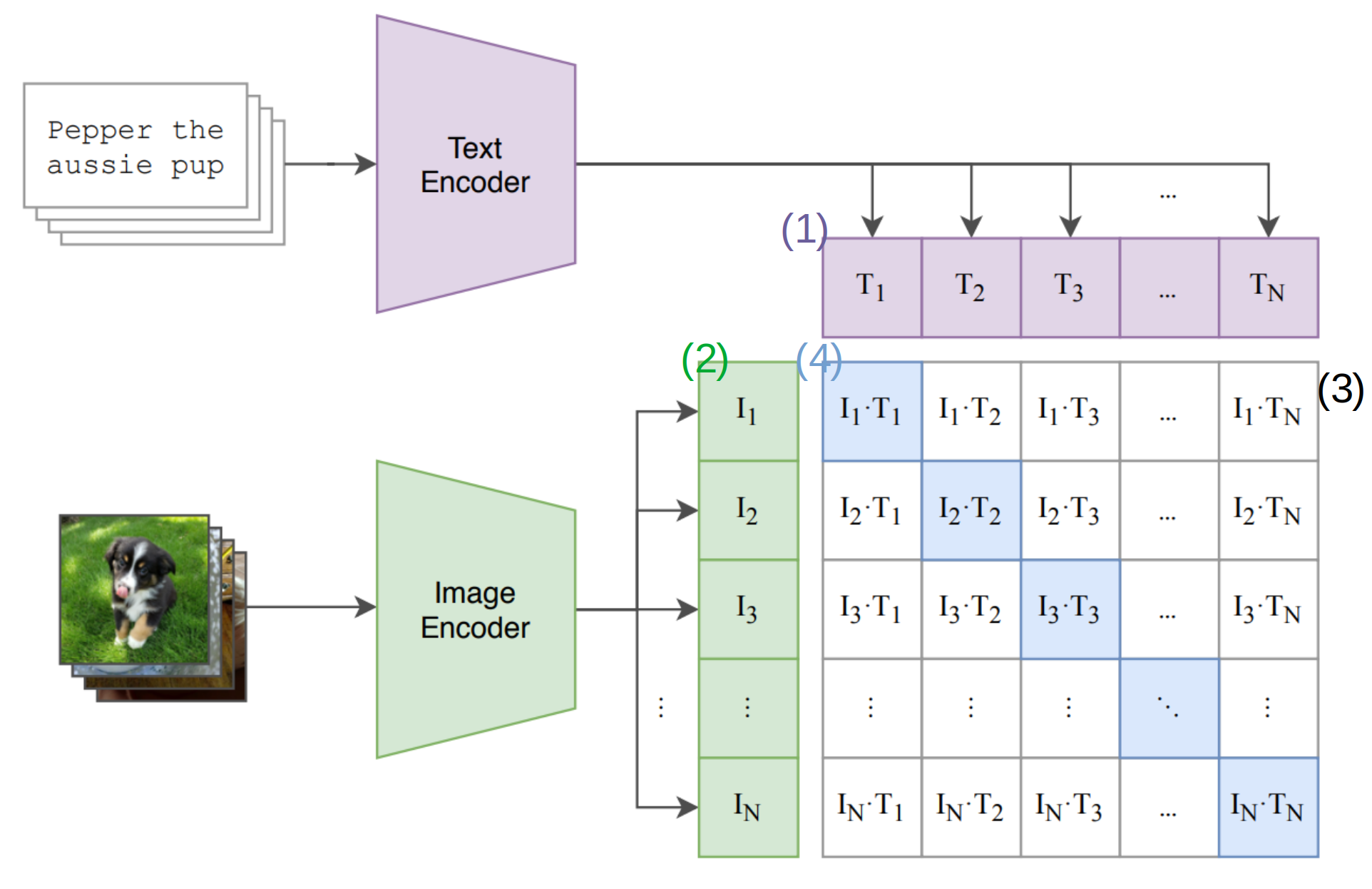
Contrastive Pre-Training Method
- Text Mini-Batch → Text Encoder → Text Representation
- Image Mini-Batch →Image Encoder → Image Representation
- Text, Image Representation을 Dot Product를 통해 (N x N)Matrix가 생성됨
- Positive Pair(Diagonal of Matrix)의 cosine similarity를 Maximize하고
\(N^2 -N\)개 Negative Pair의 cosine similarity Minimize하는 방향으로 학습
- cosine similarity를 optimize하기 위해 Cross Entropy Loss 사용
Training Details
Image Encoder : 5 ResNets and 3 Vision Transformers.
Text Encoder : Transformer (Vaswani et al., 2017) with the architecture modifications described in Radford et al. (2019).

Inference(Zero-shot prediction)
Pretraining이 끝나면 따로 Downstream task를 진행하기 위해 fine tuning을 하지 않아도 Dot product를 통해 zero-shot prediction이 가능하다.
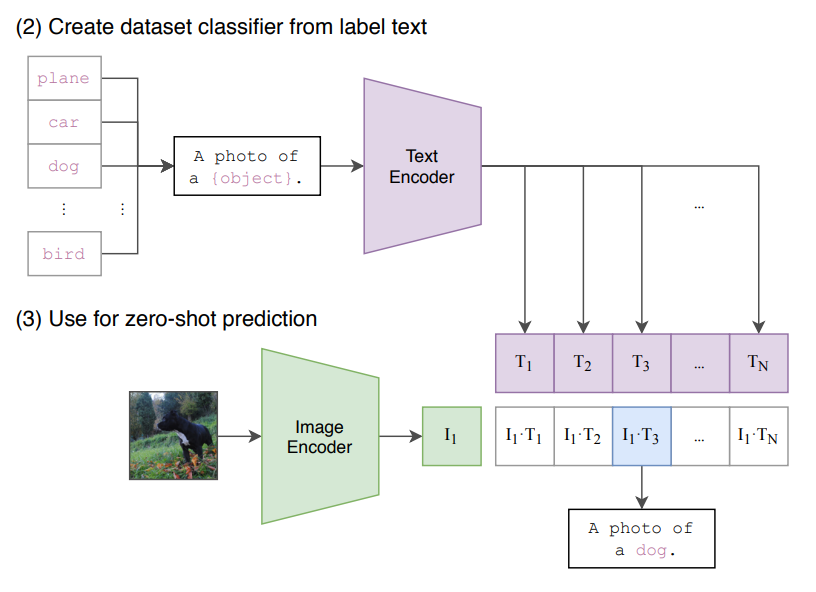
Inference(Prompt Engineering)
별도로 labeling작업을 통해 학습시킨 것이 아닌 Web-Based image-text pair로 학습시켰기 때문에 단어들이 대부분 문장구조이다.
- 추론할 때 단어를 문장 형태로 고쳐서 사용
- 동음이의어 문제를 해결하기 위함
- A photo of a {label}
- Customizing prompt text to each task
- A photo of a {label}, a type of pet
- Ensemble of different context prompts :
- A photo of a big {label} + A photo of a small {label}
- 동음이의어 문제를 해결하기 위함
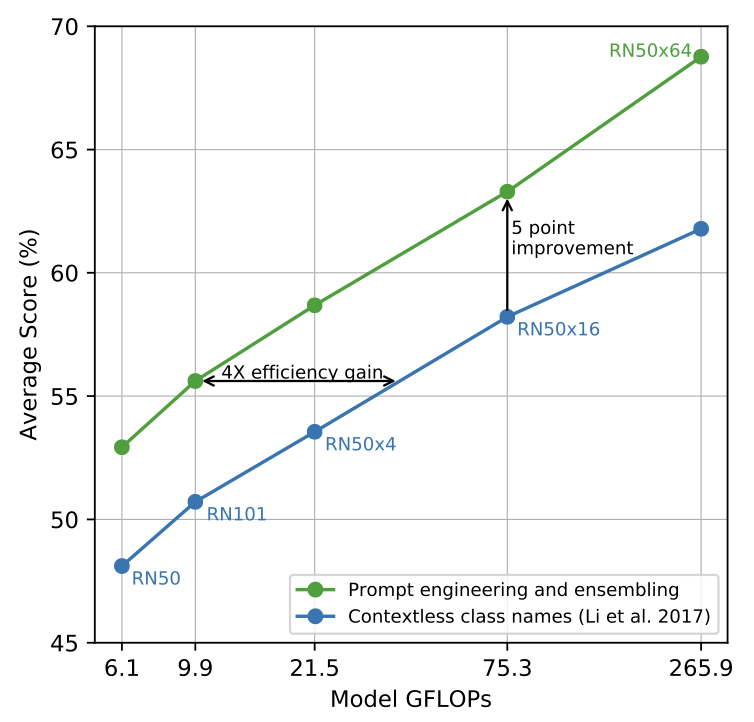
아래 표는 Prompt Engineering을 적용한 것과 하지 않은 것의 정확도 지표다
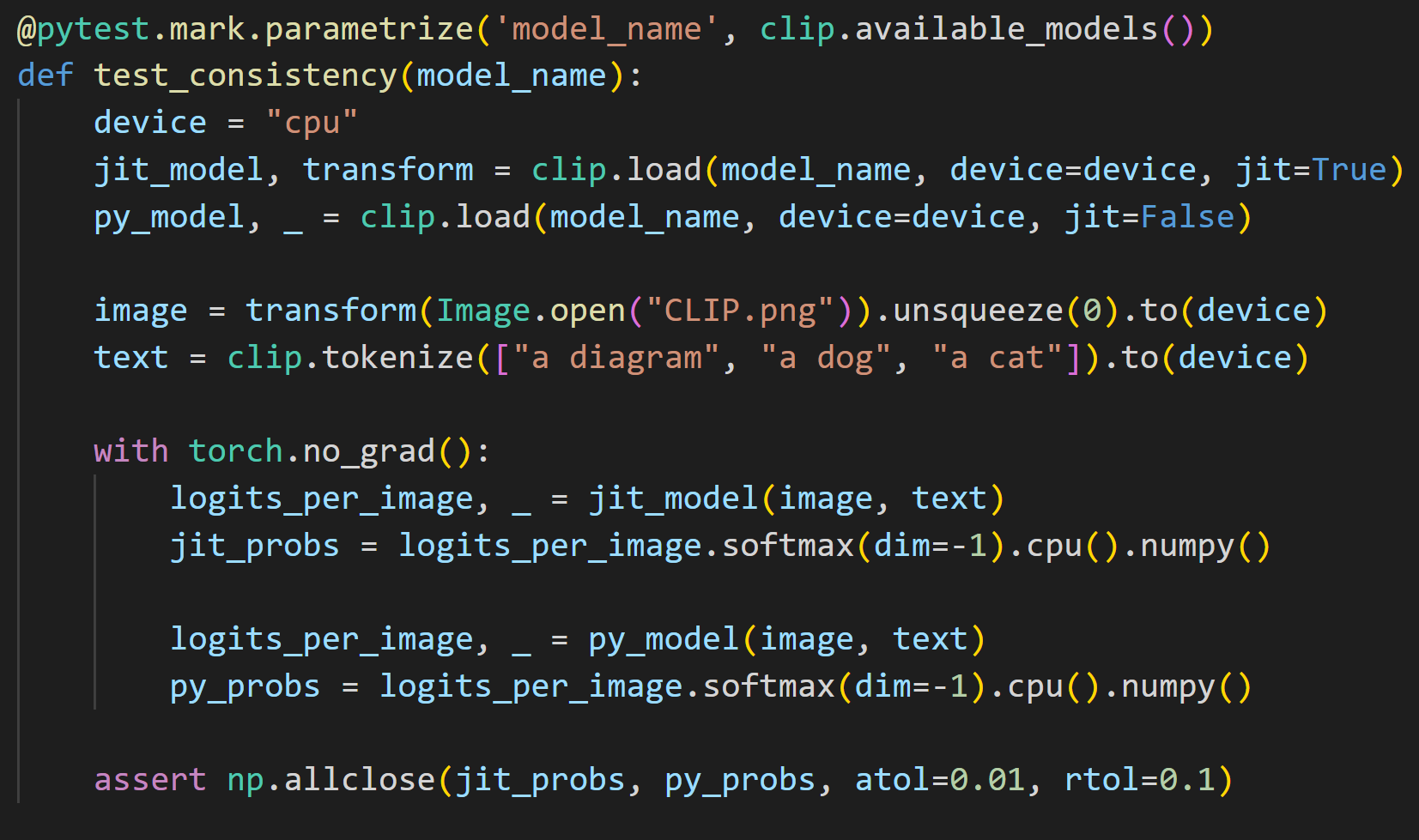
Inference Code
아래는 실질적으로 모델에서 추론하는 코드다.
[참조]
https://github.com/openai/CLIP
Comment