
서론
이 장은 ARM에서 제공하는 Neon기술에 대해 설명한다.
그리고 라즈베리파이(ARM architecture)에서 ARM Neon으로 1부터 100까지 더하는 연산 코드에 대해 설명한다.
그리고 반복문을 통한 덧셈, 곱셈연산을 C와 Neon을 사용하여 속도를 측정한다.
목차
- ARM Neon
- Neon Instruction for C
- Allocate Vector from memory
- vld1_type, vld1q_type
- Neon Library
- Neon Compile & 실행 방법
- Neon Compile & 실행 방법
- C/Neon 덧셈 연산 성능 측정
- C/Neon 곱셈 연산 성능 측정
ARM Neon
ARM Neon 기술은 SIMD architecture Extension으로 하나의 명령어로 여러 번 수행해야 할 연산을 처리할 수 있다고 한다.
VFP Extention은 ARMv5에서 도입되어 부동소수점 연산을 높였는데 ARMv7부터는 VFP기술을 사용하지 않고 Neon기술을 사용한다고 한다.
VFP와 Neon은 Register Bank를 공유하며 Neon이 Vector Floating Point(VFP)보다 연산 속도가 빠르다고 한다.
64bit register를 일정한 간격인 16bit 4개로 쪼갤 수 있지만 32bit 2개나 8bit 8개로 다양하게 분할해 사용가능하다.
Neon Instruction for C
D Register, Q Register 표현방식
D Register(64bit), Q Register(128bit)
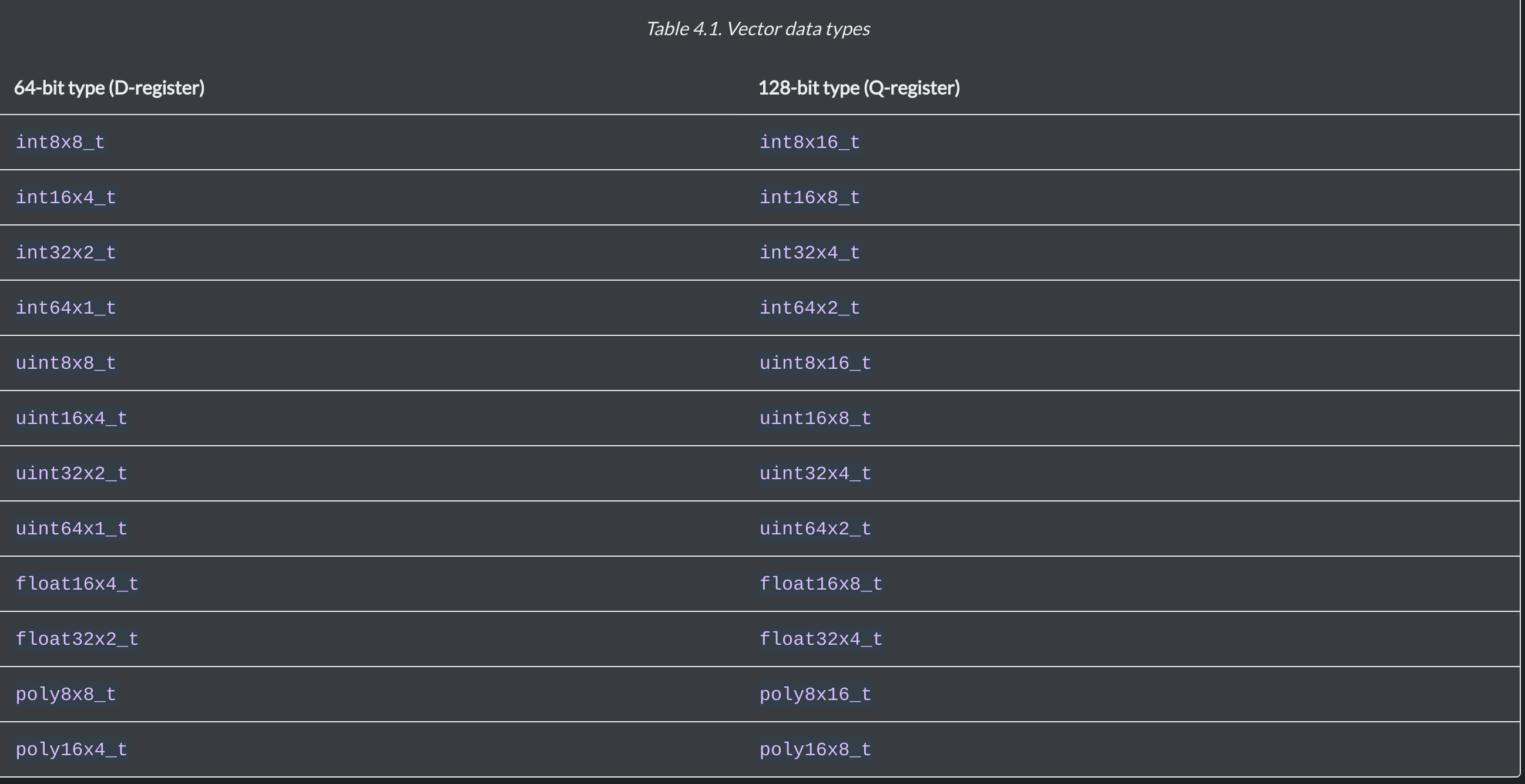
Neon Type 표현방식
uint8x16_t 의미 : unsigned 8bit lane이 16개가 있다. 총 128bit이므로 Q register에 저장됨
This is a vector containing unsigned 8-bit integers. There are 16 elements in the vector. Hence the vector must be in a 128-bit Q register.

int16x4_t 의미 : unsigned 16bit lane이 4개 있다. 총 64bit이므로 D register에 저장됨
This is a vector containing signed 16-bit integers. There are 4 elements in the vector. Hence the vector must be in a 64-bit D register.
Q-Register, D-Register에 대한 변수 선언
type\(a\)x\(b\)_t 에서 \(a\)와\(b\)의 곱이 64이면 D register가 되고
type\(a\)x\(b\)_t 에서 \(a\)와\(b\)의 곱이 128이면 Q register가 된다.
uint32x2_t vec64a, vec64b; // create two D-register variables
uint16x8_t vec128a, vec128b; // create two Q-register variablesMoving results back to normal C variables
(D-register) Neon방식으로 구현된 벡터를 일반적인 C format으로 변환하는 코드와
(Q-register) Neon방식으로 구현된 벡터를 일반적인 C format으로 변환하는 코드
To access a result from a NEON register, either store it to memory using VST, or move it back to ARM using a "get lane" type operation
vget_lane_type에서 type부분이 return 값
// D-register
uint32x2_t vec;
int result; //32bit
result = vget_lane_u32(vec, 0); // extract lane 0
// D-register
uint64x2_t vec;
int result; //64bit
result = vgetq_lane_u64(vec, 0); // extract lane 0
Accessing D registers from a Q register
Q-register의128bit 첫 번째 64bit 값을 가져오려면 low를 사용하고 두 번째 64bit값을 가져오려면 high를 사용한다. Q Register(128bit)의 값을 D Register(64bit)로 맵핑하는 코드다.
uint64x2_t vec128;
uint64_t = vec64a, vec64b;
vec64a = vget_low_u32(vec128); // split 128-bit vector
vec64b = vget_high_u32(vec128); // into 2x 64-bit vectorsAllocate Vector from memory
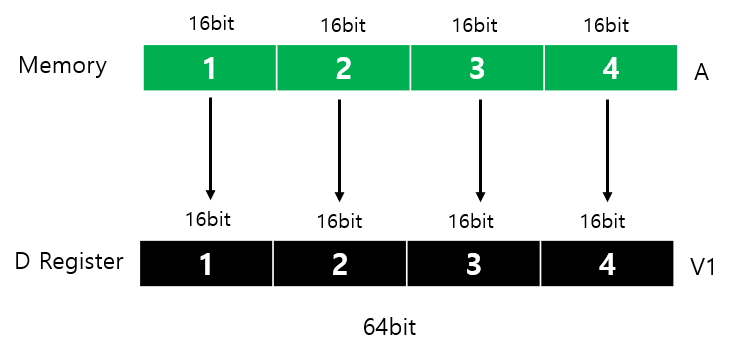
메모리에 할당된 값을 네온 벡터로 사용하기 위해 할당하는 방법을 설명한다.
This section describes how to create a vector using a NEON intrinsic. Contiguous data from a memory location can be loaded to a single vector or multiple vectors. The NEON intrinsic to do this isvld1_datatypeFor example to load a vector with four 16-bit unsigned data, use the NEON intrinsic vld1_u16.
(참고) unsigned short int → sizeof(unsigned short int) 2byte(16bit)다.
즉 각 1,2,3,4는 각 2byte(16bit)씩을 할당한다.
vld1_u16
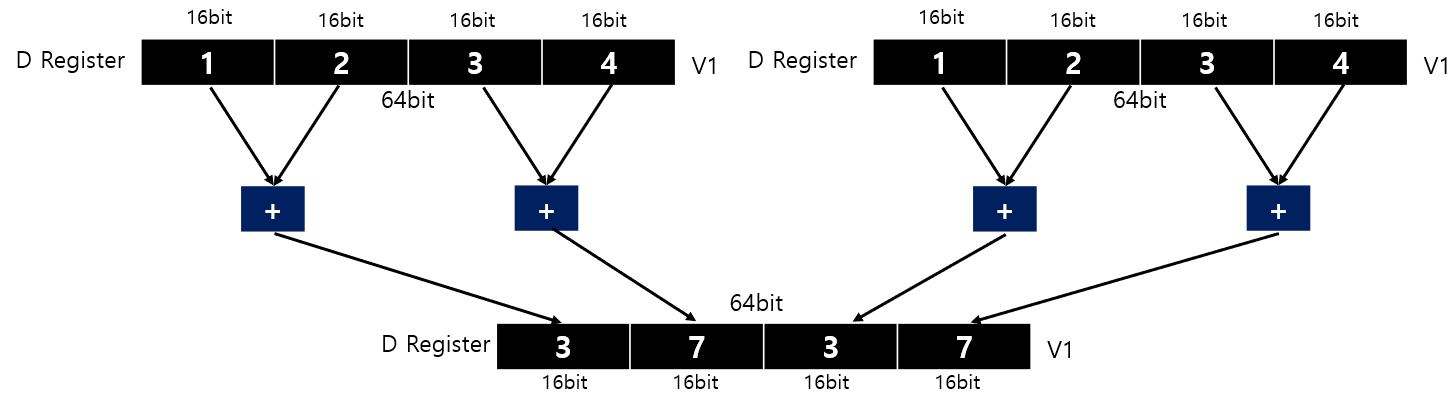
vadd_u16
https://developer.arm.com/documentation/dui0473/m/neon-instructions/vpadd
unsigned short int A[] = {1,2,3,4}; // array with 4 elements
int main(void)
{
uint16x4_t v1; // declare a vector of four (2byte)16-bit lanes(4칸짜리 배열)
uint32x2_t v2;
uint64x1_t v3;
int result;
v1 = vld1_u16(A); // load the array from memory into a vector
v1 = vadd_u16(v1,v1); // double each element in the vector
v2 = vpaddl_u16(v1);
v3 = vpaddl_u32(v2);
result = (int)vget_lane_u64(v3, 0);
return 0;
}vpaddl_u16
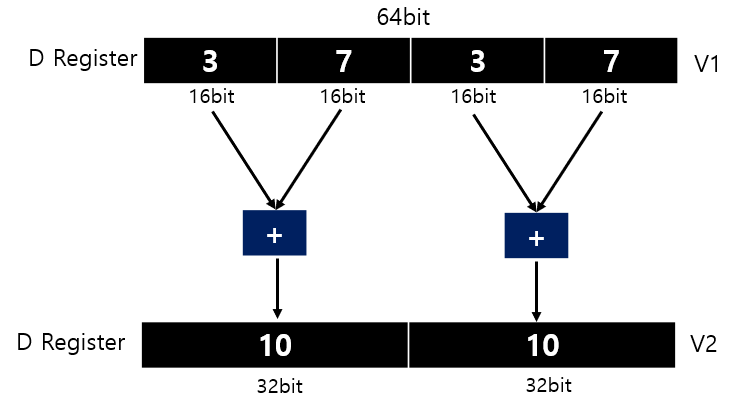
https://developer.arm.com/documentation/dui0473/m/neon-instructions/vpaddl
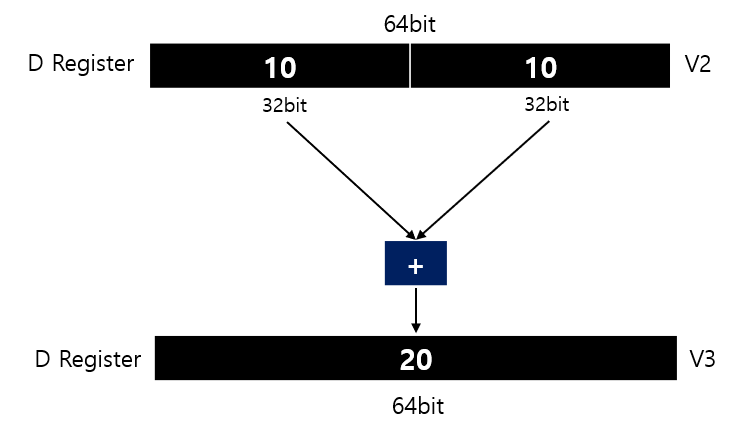
vpaddl_u32
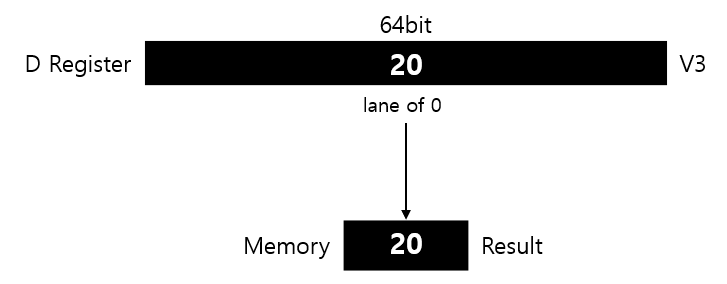
vget_lane_u64
vld1_type, vld1q_type
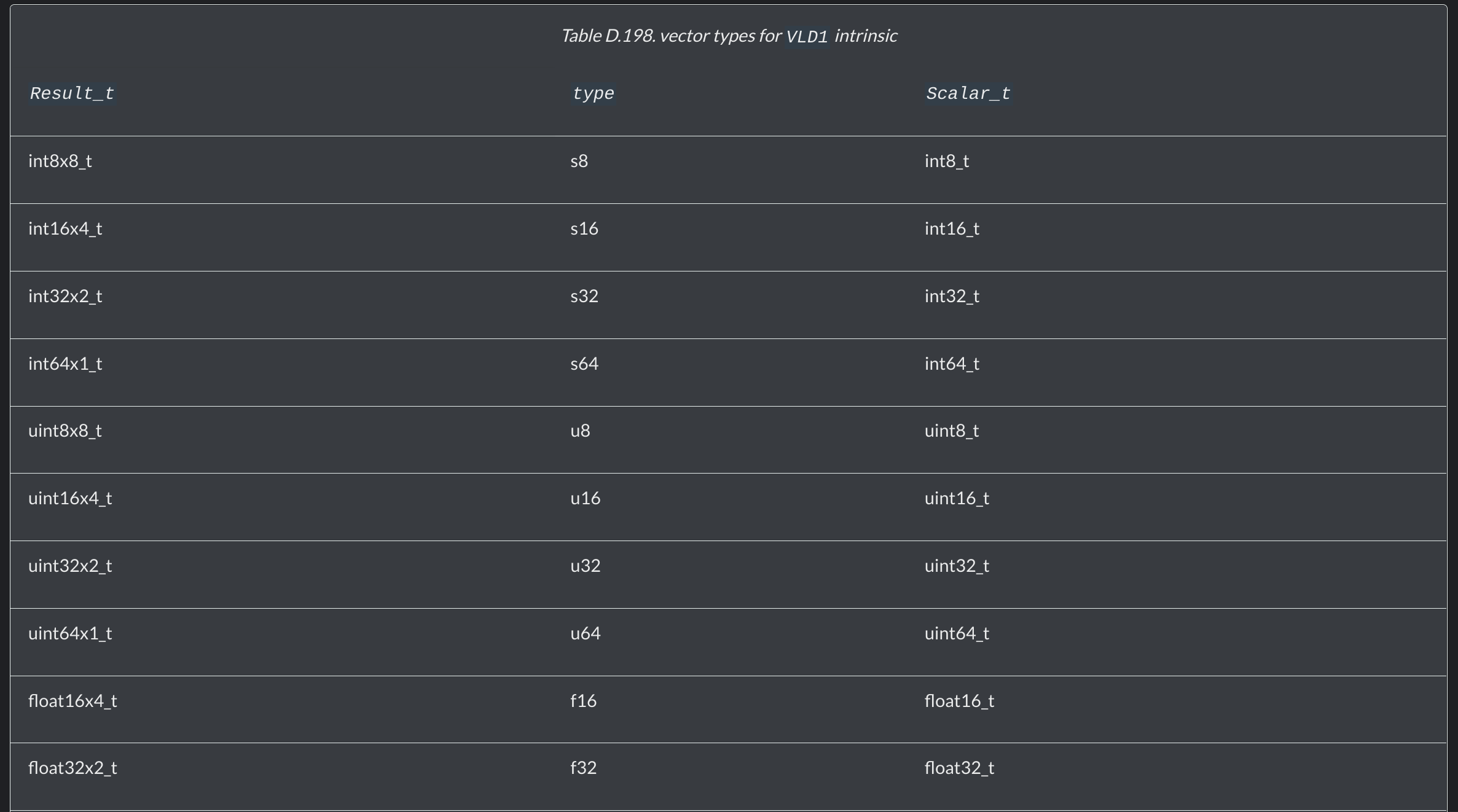
어떤 값(Scalar) N을 벡터로 할당해주는 변수 Return type을 잘 고려해야 한다.
Result_t vld1_type(Scalar_t* N)
Result_t vld1q_type(Scalar_t* N)vld1의 return값은 64bit, vld1q는 128bit다.
ex1) 메모리에 있는 값(N)의 타입이 int8일 경우 → vld1_s8(s8은 signed int 8)
return값은 64bit여야 함으로 int8x8_t
ex2)메모리에 있는 값(N)의 타입이 uint16일 경우 → vld1_u16(unsigned int 16)
Neon Library
Neon Compile & 실행 방법
matrix.c, exe_matrix_o3는 파일이름으로 본인에 파일이름을 넣어준다.
$ gcc -g -o3 matrix.c -o exe_matrix_o3
$ ./exe_matrix_o3Neon 1에서 100까지 더하기 코드 예제
/* neon_example.c - Neon intrinsics example program */
#include <stdint.h>
#include <stdio.h>
#include <assert.h>
#include <arm_neon.h>
#include <time.h>
//array에 1부터100을 초기화
void fill_array(int16_t *array, int size){
int i;
for (i = 0; i < size; i++){
array[i] = i;
}
}
int sum_array(int16_t *array, int size){
int16x4_t acc = vdup_n_s16(0); // 각 16비트로 이루어진 4칸짜리 벡터를 0으로 초기화 하라는 뜻이다.
int32x2_t acc1; // 32비트로 이루어진 2칸짜리 벡터 선언
int64x1_t acc2; // 64비트로 이루어진 1칸짜리 벡터 선언
assert((size % 4) == 0); //할당받는 벡터가 4칸짜리 임으로 배열의 크기가 4배수여야 한다.
for (; size != 0; size -= 4){
int16x4_t vec;
//return_t타입은 64bit여야하며 array(*N)타입이 16bit임으로 vec타입이 int16x4_
vec = vld1_s16(array);
//array의 타입이 int16_t임으로 +1마다 16비트(4바이트)씩 움직인다.
array += 4;
//int16x4_t acc벡터와 int16x4_t vec벡터가 곱해진다
acc = vmul_s16(acc, vec);
}
//int16x4_t acc벡터를 int32x2_t vec벡터에 할당
acc1 = vpaddl_s16(acc);
//int32x2_t vec벡터를 int64x1_t vec벡터에 할당
acc2 = vpaddl_s32(acc1);
//int64x1_t vec의 lane 0번째 값을 가져온다.
return (int)vget_lane_s64(acc2, 0);
}
/* main function */
int main(){
int16_t my_array[100];
fill_array(my_array, 100);
printf("Sum was %d\n", sum_array(my_array, 100));
return 0;
}C/Neon 덧셈 연산 성능 측정
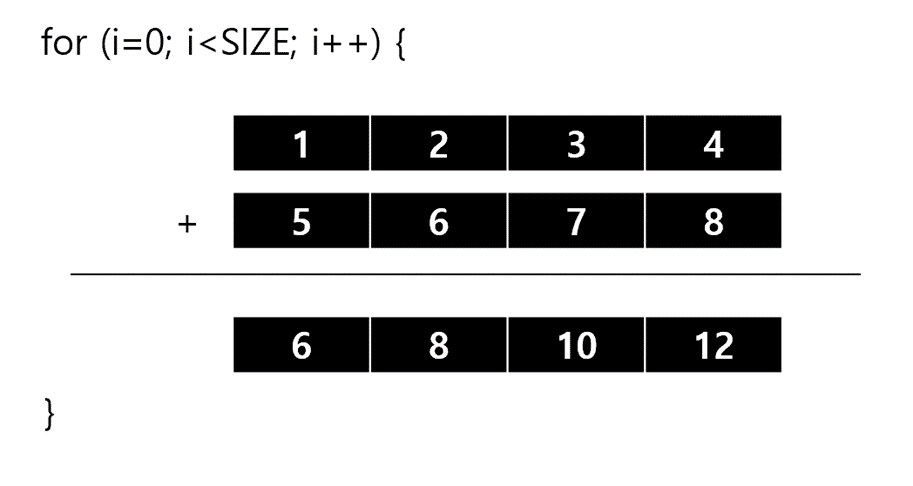
동작방식
SIZE = 100,000,000 (1억)
#include <assert.h>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <time.h>
#include <arm_neon.h>
#include <unistd.h>
#define SIZE 100000000
#define RAND_MAX 4
void fill_array(int16_t *array1, int16_t *array2, int size){
srand(time(NULL));
int i;
for (i = 0; i < size; i++){
array1[i] = (int)rand()%RAND_MAX;
array2[i] = (int)rand()%RAND_MAX;
}
}
void printvec(int16x4_t printarr, int size){
printf("Neon:");
for(int i=0; i<size; i++){
printf("%d\t", printarr[i]);
}
printf("\n");
}
void sum_array(int16_t *array1, int16_t * array2){
clock_t start, end;
int16x4_t acc;
int16x4_t vec1, vec2;
acc = vdup_n_s16(0);
start = clock();
for (int i = 0; i< SIZE; i++){
vec1 = vld1_s16(array1);
vec2 = vld1_s16(array2);
acc = vadd_s16(vec1, vec2);
}
end = clock();
printf("Neon time : %fs\n",(float)(end-start)/CLOCKS_PER_SEC);
}
void vadd(int16_t* arr1, int16_t* arr2){
clock_t start, end;
start = clock();
int arr[4];
for(int i=0; i<SIZE;i++){
for(int j=0; j<4; j++){
arr[j] = arr1[j]+arr2[j];
}
}
end = clock();
printf("C_Time : %.3lfs\n",(double)(end-start)/CLOCKS_PER_SEC);
}
int main(){
int16_t my_array1[4];
int16_t my_array2[4];
fill_array(my_array1, my_array2, 4); //array 초기화
sum_array(my_array1, my_array2); //C 연산
vadd(my_array1,my_array2); //Neon 연산
return 0;
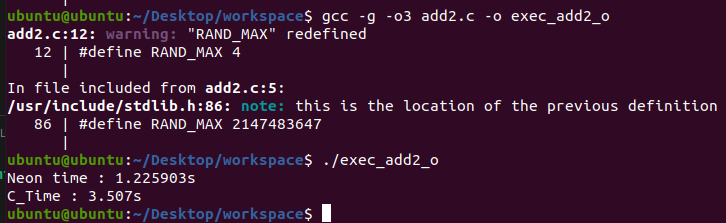
}| 사용 기술 | 소요 시간(second) |
| Neon | 1.225second |
| C | 3.507second |
C/Neon 곱셈 연산 성능 측정
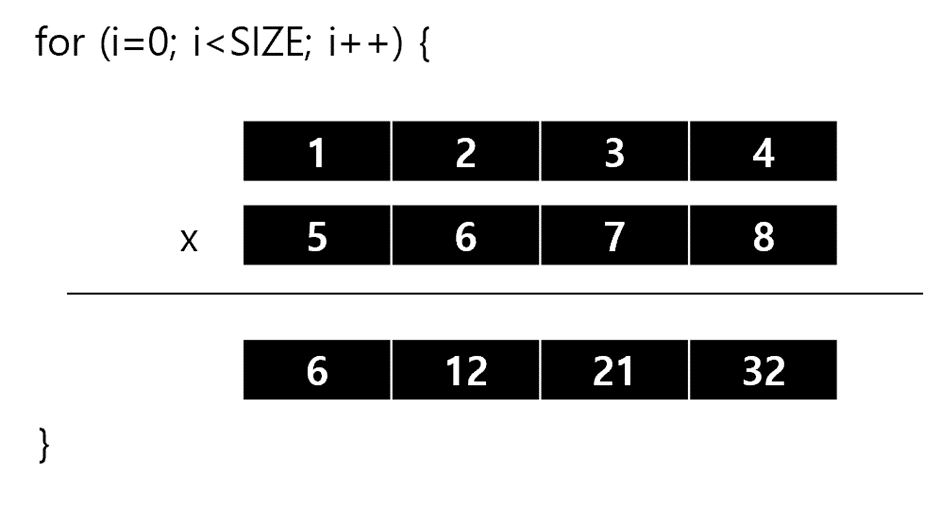
동작방식
SIZE = 100,000,000 (1억)
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <time.h>
#include <arm_neon.h>
#include <assert.h>
#define SIZE 10000000
#define RAND_MAX 4
void FillArray(int16_t *array, int16_t *array2, int size){
int i;
for (i = 0; i < size; i++){
array[i] = (int)rand()/RAND_MAX + 1;
array2[i] = (int)rand()/RAND_MAX + 1;
}
}
void PrintVector(int16x4_t C){
for (int i=0; i<4; i++){
printf("%d\t",C[i]);
}
printf("\n");
}
void PrintVectorC(int* C){
for (int i=0; i<4; i++){
printf("%d\t",C[i]);
}
printf("\n");
}
void MultiplyC(int16_t* A, int16_t *B){
clock_t start ,end;
int C[4] = {1,1,1,1};
start = clock();
for (int i=0; i<SIZE;i++){
for(int i=0; i<4; i++){
C[i] = A[i] * B[i];
}
}
end = clock();
printf("C_Time : %.3lfs\n",(double)(end-start)/CLOCKS_PER_SEC);
}
void MultiArray(int16_t *array1,int16_t *array2 ){
clock_t start, end;
int16x4_t vec1;
int16x4_t vec2;
int16x4_t acc = vdup_n_s16(1);
start = clock();
for(int i=0; i<SIZE; i++){
vec1 = vld1_s16(array1);
vec2 = vld1_s16(array2);
acc = vmul_s16(vec1, vec2);
}
end = clock();
printf("Neon time : %.3lfs\n",(float)(end-start)/CLOCKS_PER_SEC);
}
int main(){
srand(time(NULL));
int16_t A[4];
int16_t B[4];
FillArray(A,B,4);
MultiArray(A,B);
MultiplyC(A,B);
return 0;
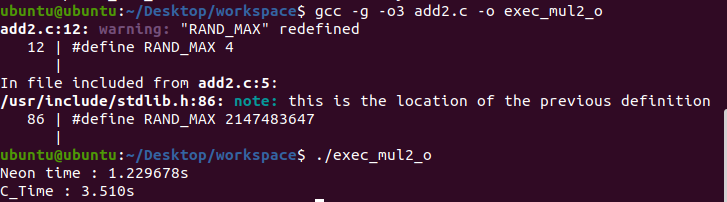
}| 사용 기술 | 소요 시간(second) |
| Neon | 1.229second |
| C | 3.510second |
Comment