
목차
- 이진 영상
- 0보단 1
- 전광판 채우기
- 장대 정상에 올라가기
- 워드 스퀘어
1. 이진 영상
문제
0과 1로 이루어진 이진 영상이 2차원 정수 배열 image 에 주어져 있다.
x, y 좌표에 위치한 값은 image[x][y] 에 저장되어 있다.
이 이진 영상에는 1로 표기된 검은색 영역이 단 하나 존재하며, 이 영역은 서로 연결되어있다.
연결되어 있다는 것의 의미는, 검은색 픽셀들은 상하좌우로 이동하여 모든 픽셀에 도달할 수 있다는 것이다.
예를 들어,
image = {{0, 0, 1, 1, 1},
{0, 0, 0, 1, 0},
{0, 1, 1, 1, 0}}위와 같이 이루어진 이진 영상은 검은색 픽셀들이 서로 상하좌우로 연결되어 있다.
위 이진 영상에서 임의의 검은색 픽셀의 좌표 하나가 x, y 가 주어졌을 때, 검은색 픽셀로 구성된 영역을 둘러싸는 직사각형의 최소 넓이를 구하시오.
단, 이 직사각형은 영상 좌표계에 똑바로 그려지며, 회전이 적용되지 않는다.
입력설명
0 < image.length <= 10000 < image[i].length <= 10000 < x <= image.length0 < y <= image[i].length
출력설명
검은 영역을 포함하는 최소의 직사각형의 넓이를 정수로 반환
매개변수 형식
image = {{0, 0, 1, 1, 1},
{0, 0, 0, 1, 0}
{0, 1, 1, 1, 0}}
x = 0
y = 2반환값 형식
12
입출력 예시 설명
아래 2로 표기한 직사각형을 그리면 된다.
02222
02222
02222풀이
이 문제를 x, y에서 부터 시작하여 1을 탐색해가면서 가장 작은 x, y좌표 그리고 가장 큰 x, y좌표를 구해 넓이를 구하는 방식으로 접근했다.
dfs로 풀어보고 bfs로도 풀어봤지만 효율성 검사 테스트 케이스에서 자꾸 실패한다.
# DFS 풀이
import collections
def solution(image, x, y):
if not image:
return -1
rows = len(image)
cols = len(image[0])
min_x = min_y = float('inf')
max_x = max_y = float('-inf')
def dfs(i, j):
nonlocal min_x
nonlocal min_y
nonlocal max_x
nonlocal max_y
if i < 0 or i >= rows or j < 0 or j >= cols or image[i][j] != 1:
return
min_x = min(min_x, i)
max_x = max(max_x, i)
min_y = min(min_y, j)
max_y = max(max_y, j)
image[i][j] = 0
dfs(i+1, j)
dfs(i-1, j)
dfs(i, j+1)
dfs(i, j-1)
dfs(x, y)
return (max_x - min_x + 1) * (max_y - min_y + 1)
# BFS 풀이
import collections
def solution(image, x, y):
if not image:
return -1
rows = len(image)
cols = len(image[0])
image[x][y] = 0
q = collections.deque()
q.append((x, y))
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
min_x = min_y = float('inf')
max_x = max_y = float('-inf')
while q:
x, y = q.popleft()
for dx, dy in directions:
nx = x + dx
ny = y + dy
if 0 <= nx < rows and 0 <= ny < cols and image[nx][ny] == 1:
image[nx][ny] = 0
q.append((nx, ny))
min_x = min(min_x, nx)
max_x = max(max_x, nx)
min_y = min(min_y, ny)
max_y = max(max_y, ny)
w = abs(max_x - min_x) + 1
h = abs(max_y - min_y) + 1
return w * h 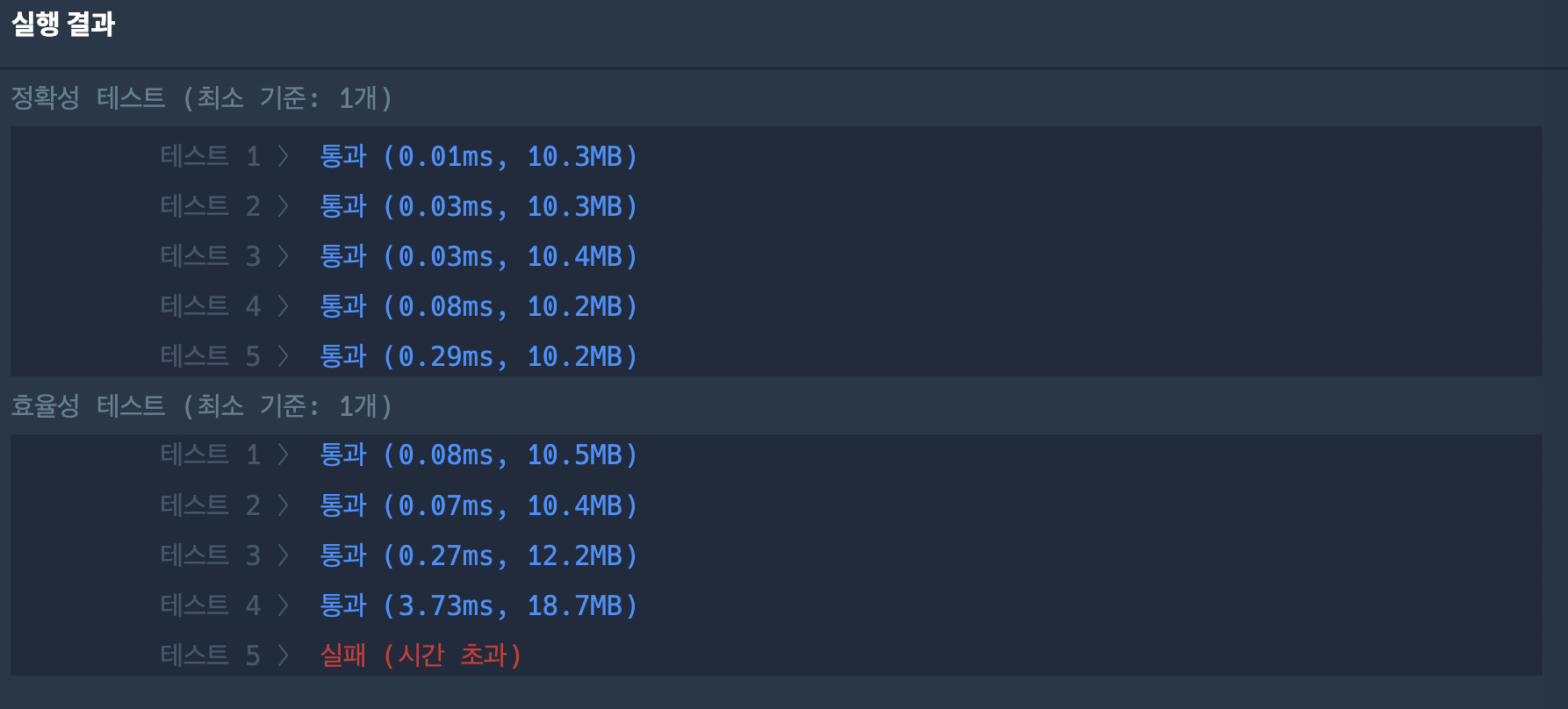
BFS/DFS가 아닌 다른 방법으로 풀이해보자.
우리는 가장 작은 좌측 상단좌표와 가장 큰 우측 하단 좌표를 구하면 된다.
이를 찾기 위해 이진 탐색을 사용한다. 예를들어 아래와 같은 image가 있고 x, y를 (2, 3)을 주었다 생각해보자.
가장 작은 x좌표를 찾기 위해 0부터 2사이에서 이진 탐색으로 최초 1의 위치를 찾는다.
0 0 0 1
0 1 1 1
0 1 1 1
0 0 1 1
0 0 0 0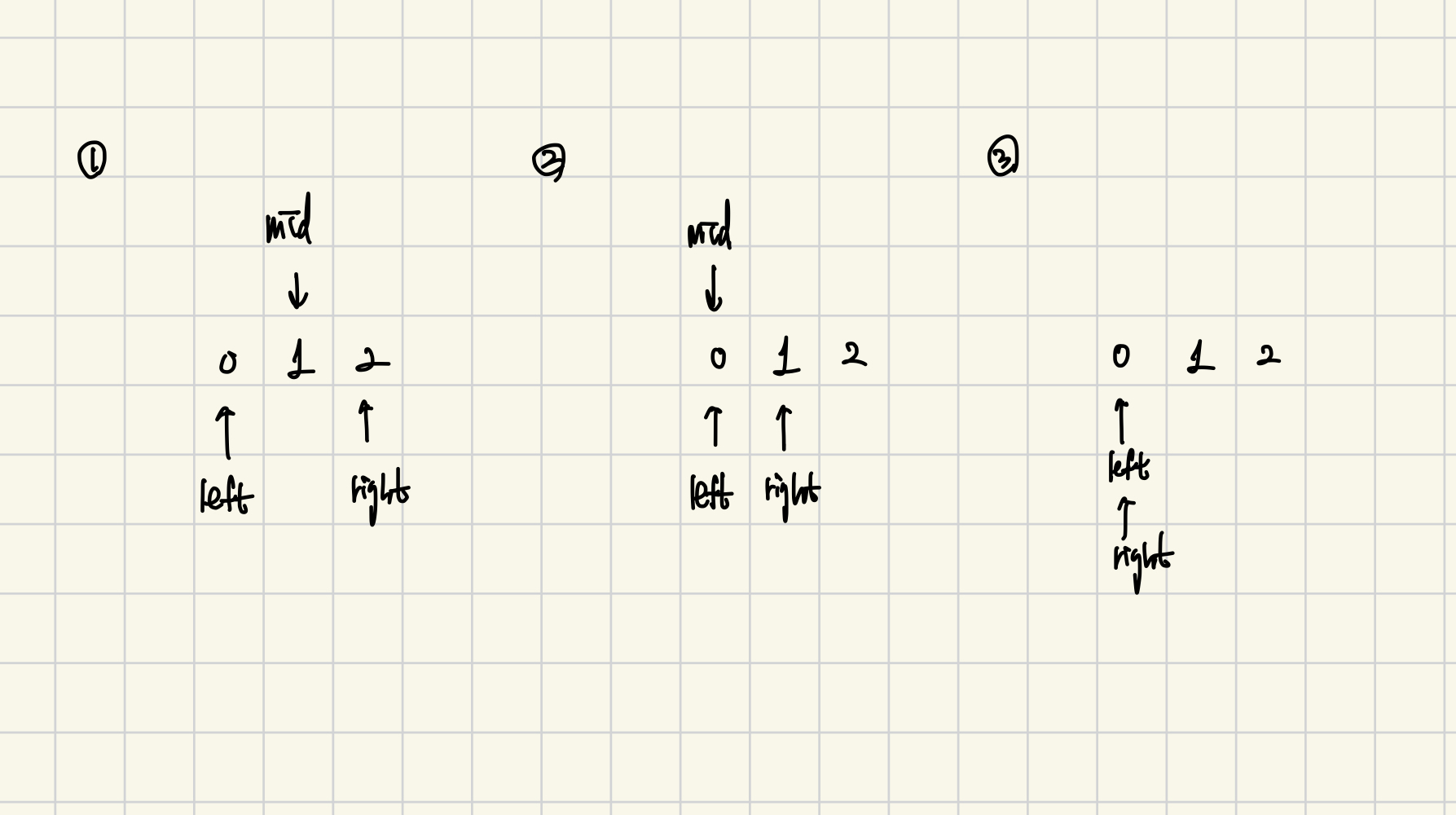
def find_lower(left, right, dir):
checker = vert_check if dir == 'x' else hori_check
while left < right:
mid = (left + right) // 2
if checker(mid):
right = mid
else:
left = mid + 1
return right
min_x = find_lower(0, x, 'x')checker가 vert_check인 경우(x좌표) 행이 선택되면 해당 행에 1이 있으면 참, 없으면 거짓을 리턴하도록 한다. 즉, 1번스탭에서 1행의 위치에 1이 1개라도 있으면 참을 반환한다. 그리고 더 작은 행에 있는지 확인하기 위해 right = mid로 옮긴다. 마찬가지로 mid가 0인 경우 0행에 1이 존재하는지 판단한다.
def vert_check(x):
for i in range(len(image[0])):
if image[x][i] == 1:
return True
return False
min_y = find_lower(0, y, 'y')checker가 hori_check인 경우(y좌표)가 선택되면 해당 열에 1이 있으면 참, 없으면 거짓을 리턴하도록 한다.
정리하면 x좌표는 가로 위치를 결정짓고, y좌표는 세로 위치를 결정한다.
최솟값을 이진 탐색으로 발견했다면, 최대값 또한 이진 탐색으로 발견한다.
def find_upper(left, right, dir):
checker = vert_check if dir == 'x' else hori_check
while left < right:
mid = (left + right) // 2
if checker(mid):
left = mid + 1
else:
right = mid
return left - 1
max_x = find_upper(x, len(image), 'x')
max_y = find_upper(y, len(image[0]), 'y')전체 코드는 아래와 같다.
def solution(image, x, y):
def find_lower(left, right, dir):
checker = vert_check if dir == 'x' else hori_check
while left < right:
mid = (left + right) // 2
if checker(mid):
right = mid
else:
left = mid + 1
return right
def find_upper(left, right, dir):
checker = vert_check if dir == 'x' else hori_check
while left < right:
mid = (left + right) // 2
if checker(mid):
left = mid + 1
else:
right = mid
return left - 1
def vert_check(x):
for i in range(len(image[0])):
if image[x][i] == 1:
return True
return False
def hori_check(y):
for i in range(len(image)):
if image[i][y] == 1:
return True
return False
min_x = find_lower(0, x, 'x')
min_y = find_lower(0, y, 'y')
max_x = find_upper(x, len(image), 'x')
max_y = find_upper(y, len(image[0]), 'y')
return (max_x - min_x + 1) * (max_y - min_y + 1)TestCase
입력값 〉 [[0, 0, 1, 1, 1], [0, 0, 0, 1, 0], [0, 1, 1, 1, 0]], 0, 2
기댓값 〉 122. (미완료) 0과 1 ? 이해가 잘 안감
문제
정수 배열 nums는 0 또는 1로만 구성되어 있다.
주어진 정수 배열에서 0보다 1이 많은 부분 배열(subarray)이 몇 가지나 만들어질 수 있는지 알고자 한다.
부분 배열이란, 배열의 일부 구간을 잘라서 만든 배열을 말한다.
조건에 맞는 부분 배열의 개수를 정수로 계산하시오.
답이 너무 커질 수 있으므로 10007로 나눈 나머지를 반환하시오.
입력 설명
0 < nums.length <= 100000
출력 설명
부분 배열의 개수를 정수로 반환
매개변수 형식
nums = [0, 1, 0, 1, 1, 0, 0, 0]
반환값 형식
10
예시 입출력 설명
아래 10 개의 부분 배열이 성립 된다.
{1}3개{1, 1}{0, 1, 1}{1, 1, 0}{1, 0, 1}{1, 0, 1, 1}{0, 1, 0, 1, 1}{1, 0, 1, 1, 0}
풀이
이 문제를 나는 슬라이딩 윈도우로 하여 풀었다.
left를 기준으로 right을 옮겨가며 1이 과반수 이상인 경우 count를 증가시킨다.
이후 다시 left를 한 칸 옮기고 left부터 탐색하는 방식이다.
시간복잡도가 O(n^2)이 나오는데 정확도에서는 통과되나 효율성에서 실패한다.
def solution(nums):
left = 0
right = 0
N = len(nums)
count = 0
while left < N:
right = left
while right < N:
sliced = nums[left:right+1]
if sliced.count(1) > len(sliced) // 2:
count += 1
right += 1
left += 1
return count
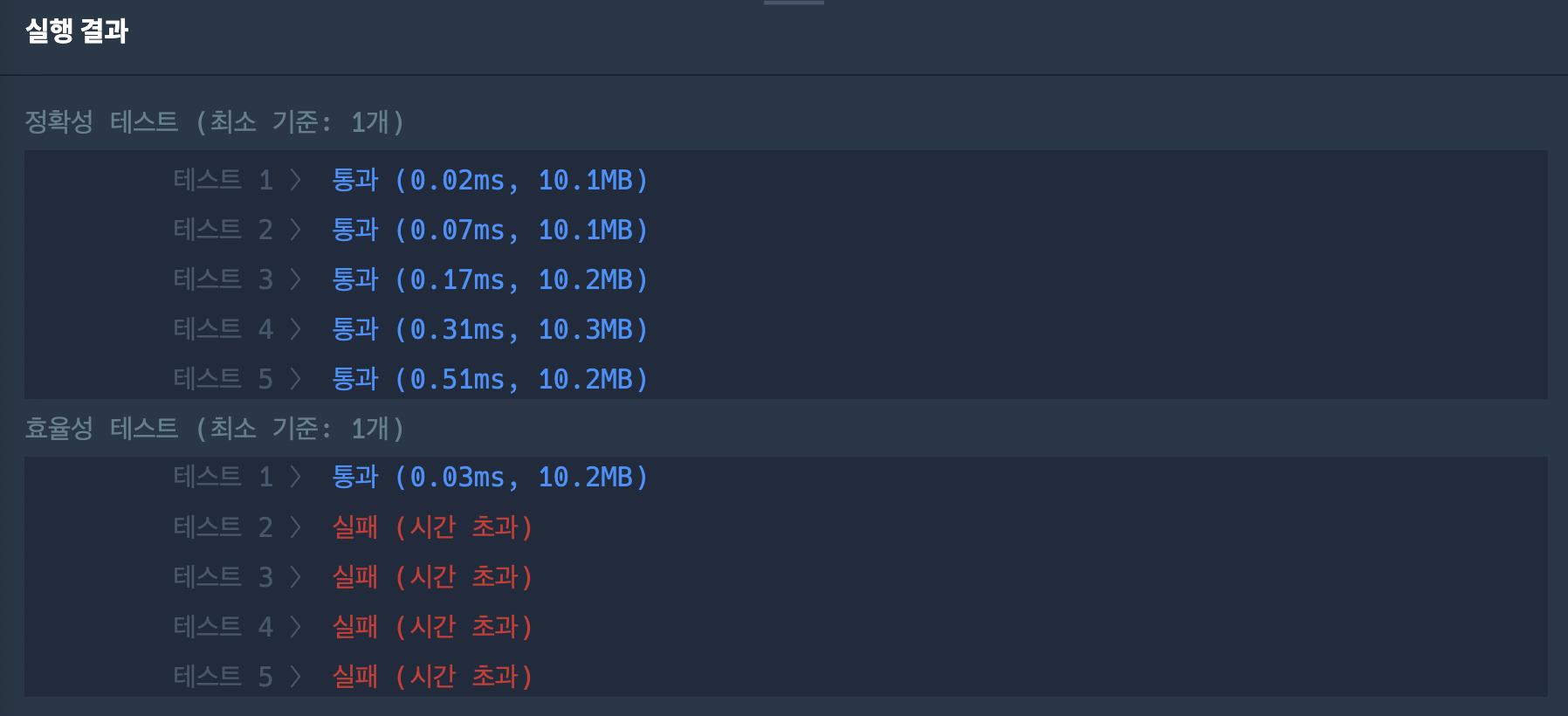
최적화하는 경우 O(n)에 풀이할 수 있다.
def solution(nums):
hash_table = defaultdict(int)
hash_table[0] = 1
running_sum, res, total = 0, 0, 0
for i in nums:
if i > 0:
running_sum += 1
total += hash_table[running_sum-1]
else:
running_sum -= 1
total -= hash_table[running_sum]
res += total
hash_table[running_sum] += 1
return res % 10007TestCase
입력값 〉 [0, 1, 0, 1, 1, 0, 0, 0]
기댓값 〉 10
입력값 〉 [1, 0, 0, 1, 0, 1, 0, 1, 1]
기댓값 〉 153. 전광판 채우기
문제
하나의 문장 S 가 당신에게 주어져 있다. 이 문장을 단어별로 구분하여 전광판에 최대한 여러번 반복하려 한다.
전광판의 크기는 M x N 의 크기로 주어지며, 문장은 단어를 순서대로 쓰되, 단어끼리는 공백이나 다음 줄로 구분되어야 한다.
또한, 한 단어는 반드시 한 줄 이내에 적혀야 한다.
예를 들어, i love zerobase 라는 문장이 주어져 있고, 5 X 9 크기의 전광판이 주어졌다고 하자.
이 경우 아래와 같이 최대 2 번 반복이 가능하다. 알아보기 쉽게 하기 위해 공백 대신 ^로표기하였다.
i^love^^^
zerobase^
i^love^^^
zerobase^
i^love^^^주어진 s, M, N 에 대하여 최대로 문장을 반복할 수 있는 횟수를 구하시오.
입력설명
- 0 <=
s.length()<= 100000 - 0 <
M<= 10000 - 0 <
N<= 10000
매개변수 형식
s = "i want to study more" M = 7 N = 7
반환값 형식
2
예시 입출력 설명
아래와 같이 2 번 반복 가능하다
i^want^
to^^^^^
study^^
more^i^
want^to
study^^
more^i^풀이
M이 끝날 때 까지 반복하며 j가 s의 모든 문자를 반영했다면 j = 0으로 만든다.
A: total = total - len(s[j]) - 1 에서 -1을 준 이유는 글자당 띄어쓰기가 이뤄져야 하기 때문이다.
예를들어 I가 나왔다면 띄어쓰기가 추가되어 -1을 추가로 해준다.
B: if total == -1: 이 부분은 예를들어 열의 갯수(N)가 7인데 want^to이렇게 7글자가 꽉 차는 경우가 있다.
A에서 항상 -1을 더해 띄어쓰기를 처리해줬기 때문에 total이 -1로 끝나면 want^to^ 이렇게 끝나게된다는 것임으로 띄어쓰기 처리를 해서는 안된다. 따라서 total == -1인 경우에 대해서는 다시 +1을 해준다.
이렇게 풀이하면 정확도 테스트는 통과하나 효율성 테스트에서 실패한다.
def solution(s, M, N):
s = s.split()
j = 0
count = 0
for _ in range(M):
total = N
while j < len(s):
total = total - len(s[j]) - 1
if total == -1:
total += 1
if total < 0:
break
j += 1
if j == len(s):
count += 1
j = 0
M += 1
return count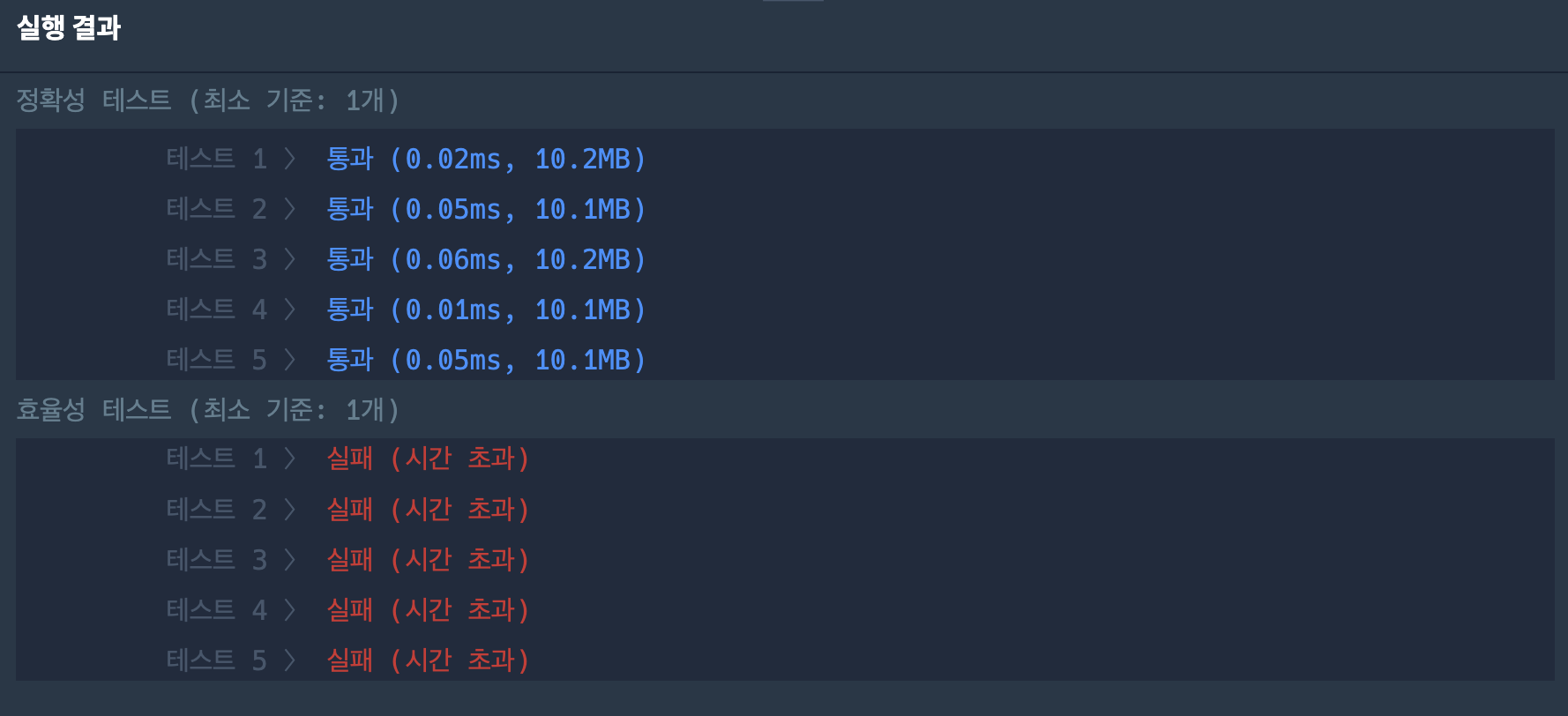
좀 더 최적화할 수 있는 다른 방법으로 풀어보자.
- 문장을 한 줄씩 배치 (N칸씩 옮김)
- 전광판의 한 줄에 최대 N개의 글자를 배치합니다.
- 문장의 현재 위치를 나타내는 인덱스 포인터는 한 번에 N만큼 이동

- 단어가 끊기지 않도록 조정
- 만약 현재 인덱스 위치가 공백이 아니라면, 공백이 나올 때까지 한 칸씩 뒤로 이동합니다.
- 단어가 한 줄 내에서만 완전하게 포함되도록 하기 위한 조치입니다.
- 공백을 찾았다면, 해당 위치를 한 줄에 배치 가능한 최대 문자 수로 간주하고, 공백 다음 글자부터 새 줄을 시작
- 문장의 끝에 정확히 도달했을 때 최적화
- 만약 현재 인덱스 포인터가 문장의 길이로 나누어떨어진다면, 이는 문장이 완전히 끝난 지점임을 의미
- 이때, 지금까지 사용한 행 수(row)와 전체 행 수(M)를 이용해 최적화를 진행
- 남은 행으로 반복 가능 횟수 계산
- 남은 행 = 전체 행(M) ÷ 현재까지 사용한 행(row) 을 계산
- 이 값(x)을 이용해, 앞으로 남은 행에서도 동일한 패턴으로 문장을 반복할 수 있는 횟수를 계산
- 현재 인덱스 값을 x 배만큼 늘려 한 번에 최적화
6. 남은 행 계산
- 최적화 이후, 남은 행을 계산하기 위해 row = 0으로 초기화하고, M = M % row로 남은 행을 설정
- 이 남은 행에 대해 다시 한 줄씩 계산
마지막으로 문장 끝에 공백을 추가하는 이유는, 단어가 붙어 잘못된 출력이 생기는 것을 방지하기 위함이다.
예를 들어, 문장이 "I love zerobase" 라면, 전광판에서 문장이 반복될 때 "zerobase" 와 "I" 가 붙어 "zerobaseI" 처럼 처리된다.
위 내용을 코드로 구현하면 아래와 같다.
def solution(s, M, N):
s = s + ' '
infinite_index, l, row = 0, len(s), 0
while row < M:
if infinite_index % l == 0 and row > 0:
infinite_index *= M // row
row, M = 0, M % row
else:
infinite_index += N
while s[infinite_index % l] != ' ':
infinite_index -= 1
infinite_index += 1
row += 1
return infinite_index//l
TestCase
입력값 〉 "i want to study more", 7, 7
기댓값 〉 2
입력값 〉 "i just called to say i love you by stevie wonder", 10, 20
기댓값 〉 44. 장대 정상에 올라가기
문제
당신은 명작 만화영화 '뮬란'에 등장한 훈련법을 이용하여 수련하고자 한다.
이 훈련법은 아래와 같다.
높이가 L 인 장대가 주어진다.
당신은 한 번에 U 만큼 장대를 올라갈 수 있다.
장대를 한 번 올라간 후, 장대의 정상에 도달하지 못하면 D 만큼 미끄러진다.
단, U는 항상 D보다 크다.
장대의 정상에 도착하기 위해서 몇 번 올라가야 하는지 구하시오.
입력설명
- 0 < L <= 100000
- 0 < U <= 10000
- 0 < D <= 10000
출력설명
몇 번 올라야 하는지 정수로 반환
매개변수 형식
L = 10
U = 5
D = 3
반환값 형식
4
예시입출력 설명
- 1번 오른 결과 높이 변화: 2
- 2번 오른 결과 높이 변화: 2 -> 7 -> 4
- 3번 오른 결과 높이 변화: 4 -> -> 6
- 4번 오른 결과 높이 변화: 6 -> 10 (정상에 도달)
풀이
a가 시작위치이다. 시작위치에서 U만큼 올라갔을 때 L보다 크거나 같으면 반복을 종료한다.
테스트 케이스는 성공하였지만 효율성 테스트에서 실패한다.
def solution(L, U, D):
a = 0
count = 0
while True:
if a + U >= L:
break
count += 1
a = a + U - D
return count + 1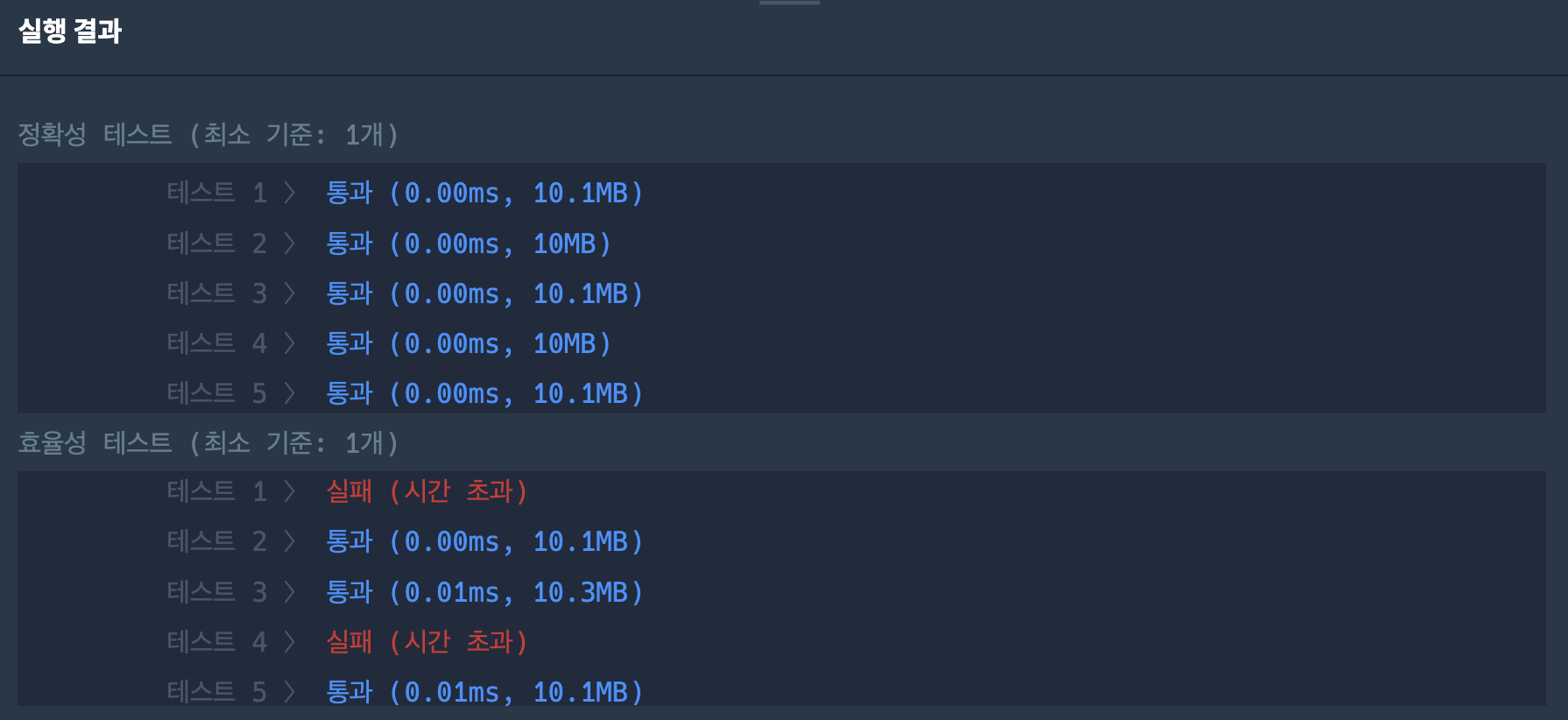
단순히 나누기 연산을 해서 그 횟수를 반환하도록 하면 문제가 된다.
그 이유는 TestCase2를 예시로 들면 목표지점이 100이고 60만큼 올라갔다가 50만큼 내려온다.
이렇게 반복을하다가 현재 위치가 50이 되었을 때 60만큼 올라가면 목표지점에 도달함으로 50만큼 내려오지 않는다.
그렇다면 마지막 부분을 남겨두면 된다.
즉 마지막 올라가는 부분이 50일 때 임으로 100에서 마지막 연산인 50을 미리 뺀다.
그럼 50 만큼은 나누기 연산을 통해 올라가는 횟수랑 동일해진다.
50을 10(60 - 10)으로 나누어 5번을 시도했고 여기서 한 번만 더 올라가면(50+60=110) 100에 도달한다.
이를 코드로 구현하면 아래와 같다.
def solution(L, U, D):
d = U - D # 공차
prev = L - U # 올라가기 직전 값
pos = prev // d
return pos + 1 # 마지막 올라가는 횟수 추가그러나 여기서 한 가지 문제가 있다. TestCase1번을 봐보자.
10에 도달해야 하며 5만큼 올라가고 3만큼 미끄러진다.
여기서 도달직전 5(10 - 5)를 2(5-2)로 나누면 몫이 2가 나온다.
그러나 실제로는 3이 나와야한다. 몫이 2라는 것은 2번올라갔다는 것이고 이는 현재 위치가 4라는 것이다.
따라서 나누어 떨어지면 문제가 없지만 나머지가 있는 경우에 대해서는 올림 계산을 해야한다.
a // b 를 할 때 몫을 올림 처리를 하고싶다면 a + b - 1 // b 를 하면 된다.
- a와 b가 나누어 떨어지는 경우 a = 6, b = 3
- a // b = 2
- a + b - 1 // b:
6 + 3 - 1 // 3= 2
- a와 b가 나누어 떨어지지 않는 경우 a = 5, b = 3
- a // b = 1
- a + b - 1 // b:
5 + 3 - 1 // 3= 2
이 처럼 나누어 떨어지는 경우는 몫이 같고 나누어 떨어지지 않고 나머지가 생기는 경우는 몫이 올림 처리가 된다.
따라서 아래와 같이 코드를 수정해주면 된다.
def solution(L, U, D):
d = U - D
prev = L - U
pos = (prev + d - 1) // d
return pos + 1이렇게하면 효율성 테스트에서 통과된다!
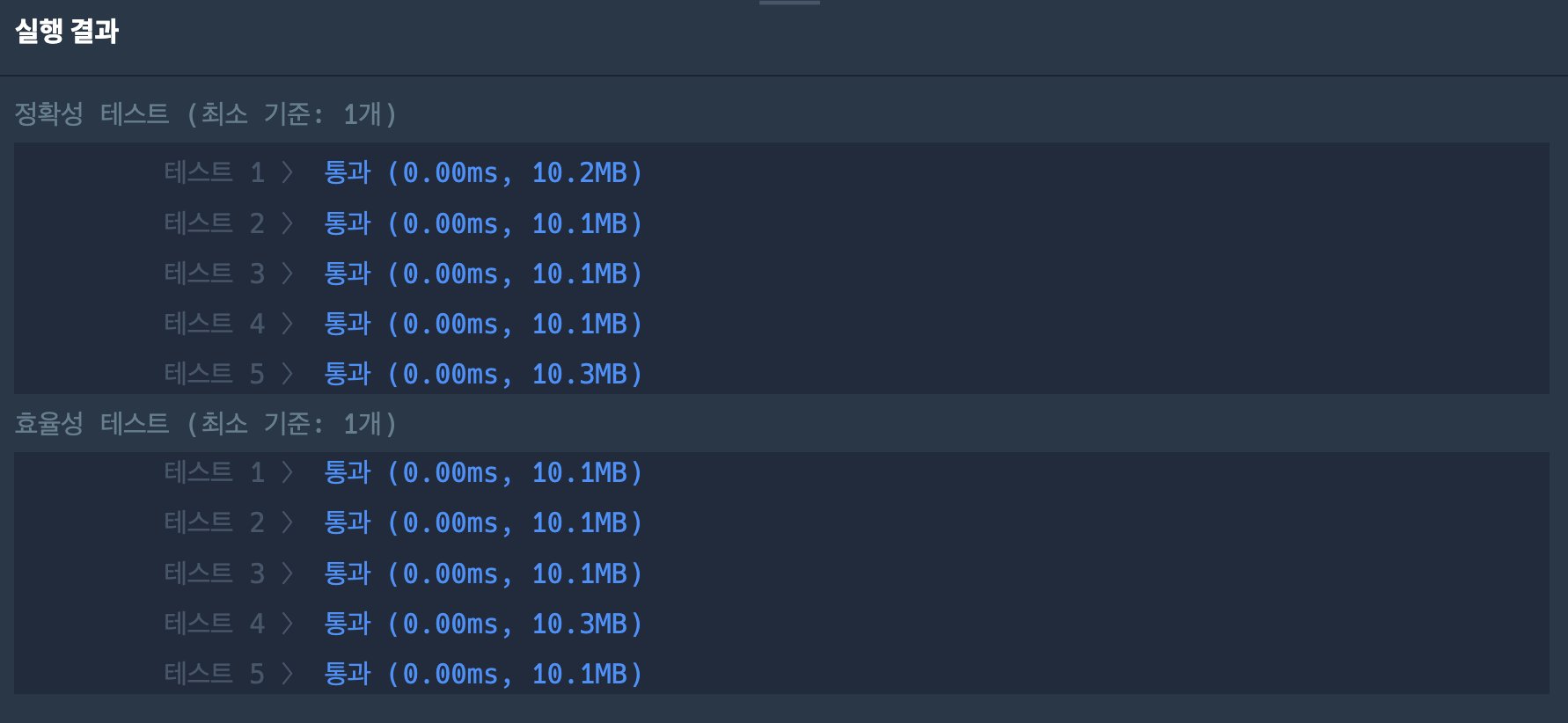
TestCase
# Testcase 1
입력값 〉 10, 5, 3
기댓값 〉 4
# Testcase 2
입력값 〉 100, 60, 50
기댓값 〉 55. 워드 스퀘어
문제
당신은 '개똥아 똥쌌니 아니오' 게임을 하고 있다.
이 게임은, 문자열 배열 words 에 주어진 단어들을 이용하여 워드 스퀘어(word square)를 구성하는 것이다.
워드 스퀘어를 예를 들어 설명하면, {"개똥아", "똥쌌니", "아니오"} 라는 배열은 워드 스퀘어를 성립한다.
개똥아
똥쌌니
아니오이 단어들은 세로로 순서대로 배치해 두었을 때, 세로로 읽어도 가로로 읽어도 동일한 단어가 된다. 문자열 배열 words 에 주어지는 단어는 모두 같은 길이의 단어일 때, words 에서 서로 다른 문자열을 골라 총 몇 개의 워드 스퀘어를 만들 수 있는지 구하시오.
입력설명
- 0 < words.length <= 1000
- 1 <= words[i].length <= 4
출력설명
가능한 워드 스퀘어의 수를 반환
매개변수 형식
words = {"pi", "hi" , "of", "if", "to"}
반환값 형식
3
입출력 예시 설명
아래와 같이 총 3가지의 워드 스퀘어가 가능하다.
pi
ifhi
ifto
of풀이
이 문제는 트라이 자료구조를 사용하는 문제이다.
각 단어들을 트라이에 등록하고 워드 스퀘어(word square)의 규칙에 맞게 트라이에서 탐색하는 방식으로 풀이하면 된다.
먼저 트라이 자료구조를 만들어보자.
self.c는 문자열의 초성을 의미한다. 각 노드가 단어별 초성을 가지고 있게 된다.
self.word는 각 노드별 단어의 마지막을 구별하기 위한 값이다.
self.children은 각 문자열 초성들을 자식노드 순서로 연결해둔다.
self.words는 문자열 전체를 리스트에 담아둔다.
class Node:
def __init__(self, c):
self.c = c # 단어 초성
self.words = [] # 문자열 저장
self.children = {} # 자식 단어
self.word = '' # 문자열의 끝인 경우 문자열형태로 저장아래는 [“개똥아”, “똥쌌니”, “아니오”] 문자열을 트라이에 각각 담아 알고리즘을 도식화하였다.
보면 개똥아로 연결된 문자열들은 리스트 형태로 개똥아를 담고있다가 마지막 ‘아’에 도달하면 리스트가 아닌 word변수로 문자열을 담도록하여 마지막 문자임을 알려주는 역할을 한다.
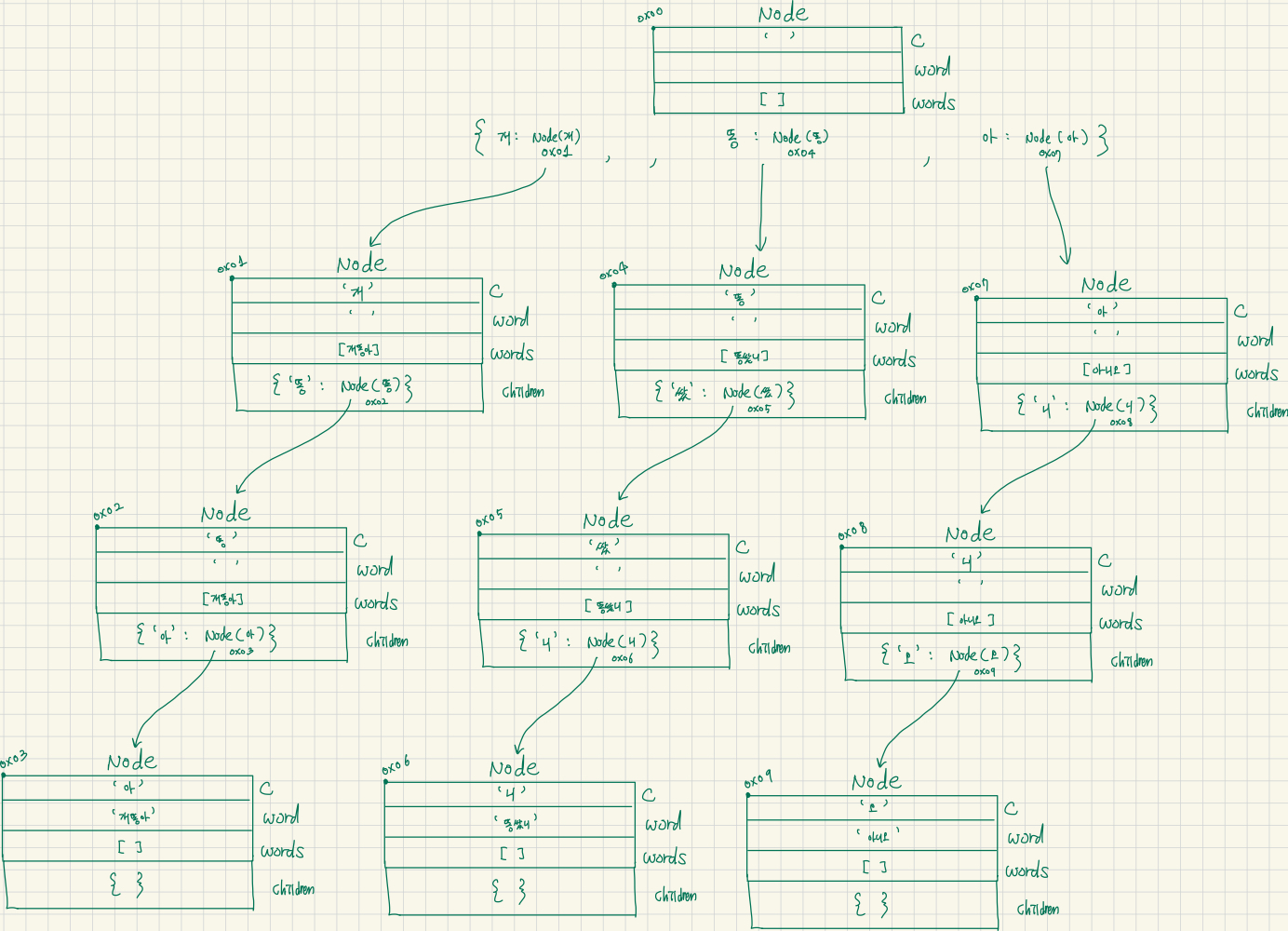
이제 위 처럼 등록하기 위해서 트라이 자료구조를 만들어보자. insert 함수로 구현하였다.
class Trie:
def __init__(self):
self.root = Node('')
def insert(self, w, index = 0, parent = None):
if parent is None:
parent = self.root
c = w[index]
if c not in parent.children:
parent.children[c] = Node(c)
if index == len(w) - 1:
parent.children[w[index]].word = w
return
parent.children[c].words.append(w)
self.insert(w, index + 1, parent.children[c])
def search(self, prefix, index=0, parent=None):
pass
def solution(words):
answer = []
trie = Trie()
for word in words:
trie.insert(word)
이제 탐색을 해야하는데 탐색하는 경우 어떤 문자를 탐색할지를 정해서 트라이에 넘겨줘야한다.
그 부분을 함수로 만들어보자.
def search_to_string(path, index): # [개똥아, 똥쌋니 ], 2 || [개똥아, 똥쌋니, 아니오 ], 3
s = ''
for i in range(index):
s += path[i][index] # [0][2] [1][2] || [0][3] [1][3] [2][3]
return sindex는 path에 담긴 갯수와 일치한다. path에 개똥아 똥쌌니 2개가 담겼다면 index는 2가되고,
3개가 담겨있다면 3이된다.
왜 이렇게하는지는 아래 워드 스퀘어 특성을 봐보면 된다.
예를들어 path = [ball, area, lead] , index = 3 이면 path[0][3], path[1][3], path[2][3]이 lea로 시작해야 4번째에 등장할 녀석의 워드 스퀘어가 조건이 완성된다.

이제 이것을 통해 얻은 결과로 그 단어가 트라이에 있는지 확인해보면 된다.
워드스퀘어를 만족하면 answer에 담도록하고 그렇지 않으면 종료한다.
def solution(words):
answer = []
trie = Trie()
for word in words:
trie.insert(word)
def solve(path, index):
if index == len(path[0]):
answer.append(path[:])
return
to_search = search_to_string(path, index) # 어떤단어를 서치해야하는지 찾고 '똥'
for word in trie.search(to_search): # 그 단어가 트라이에 있는지 확인하고 있으면
solve(path+[word], index+1) # [개똥아, 똥쌋니], 2
path = []
for word in words:
solve(path+[word], 1)
return len(answer)그럼 트라이에 search함수를 추가해 완성시키면 끝난다.
따라서 전체 코드는 아래와 같다.
class Node:
def __init__(self, c):
self.c = c
self.word = ""
self.children = {}
self.words = []
class Trie:
def __init__(self):
self.root = Node('')
def insert(self, w, index = 0, parent = None):
if parent is None:
parent = self.root
c = w[index]
if c not in parent.children:
parent.children[c] = Node(c)
if index == len(w) - 1:
parent.children[w[index]].word = w
return
parent.children[c].words.append(w)
self.insert(w, index + 1, parent.children[c])
def search(self, prefix, index=0, parent=None):
if parent is None:
parent = self.root
if prefix[index] not in parent.children:
return []
curr = parent.children[prefix[index]]
if index == len(prefix) - 1:
return curr.words
return self.search(prefix, index + 1, curr)
def search_to_string(path, index): # [개똥아, 똥쌋니 ], 2 || [개똥아, 똥쌋니, 아니오 ], 3
s = ''
for i in range(index):
s += path[i][index] # [0][2] [1][2] || [0][3] [1][3] [2][3]
return s
def solution(words):
answer = []
trie = Trie()
for word in words:
trie.insert(word)
def solve(path, index):
if index == len(path[0]):
answer.append(path[:])
return
to_search = search_to_string(path, index) # 어떤단어를 서치해야하는지 찾고 '똥'
for word in trie.search(to_search): # 그 단어가 트라이에 있는지 확인하고 있으면
solve(path+[word], index+1) # [개똥아, 똥쌋니], 2
path = []
for word in words:
solve(path+[word], 1)
return len(answer)TestCase
# TestCase 1
입력값 〉 ["pi", "hi", "of", "if", "to"]
기댓값 〉 3출처
해당 문제와 코드는 제로베이스(ZeroBase)에서 제공받았습니다.
모든 자료는 저작권법에 의하여 보호받는 저작물로서 이에 대한 무단 복제 및 배포를 원칙적으로 금합니다.
Comment