
목차
- 부분 문자열
- 배열 안정화
- 가구 연결
- 배열 곱
- 플라스틱 소화
1. 부문 문자열
문제
부분 문자열은 어떤 문자열에서 문자의 순서를 유지하면서, 일부 문자를 제거한 문자열이다.
예를 들어 "acf"는 "abcdef" 의 부분 문자열이지만, "adc"는 "abcdef"의 부분 문자열이 아니다.
문자열 src와 dst가 주어졌을 때, src의 부분 문자열을 연속으로 이어붙여 문자열 dst를 만들고자 한다.
이 때 필요한 최소의 부분 문자열의 개수를 출력하시오. 단, dst 를 만드는 것이 불가능할 경우 -1을 출력하시오.
입력설명
0 < src.length <= 1000
0 < dst.length <= 5000
출력설명
필요한 최소의 부분 문자열의 개수를 정수로 반환
매개변수 형식
src = "zerobase"
dst = "aero"
반환값 형식
2
예시입출력 설명
부분 문자열 "ae" 와 "ro" 를 덧붙여 "aero" 를 만들 수 있다.
풀이
dst를 탐색해 나간다. src와 같은 문자가 있으면 dst의 다음 문자로 넘어간다.
만약 src를 전부 탐색했는데도 dst의 포인터(i)위치가 그대로라면 없다는 뜻임으로 -1을 리턴한다.
def solution(src, dst):
N = len(src)
M = len(dst)
count = i = 0
while i < M:
prev = i
j = 0
while i < M and j < N:
if dst[i] == src[j]:
i += 1
j += 1
if prev == i:
return -1
count += 1
return count정답지:
def solution(src, dst):
N = len(src)
M = len(dst)
i = 0
j = 0
result = 0
while j < M:
prev_j = j
while i < N and j < M:
if src[i] == dst[j]:
j += 1
i += 1
else:
i += 1
result += 1
i = 0
if j == prev_j:
return -1
return result
# 테스트 1
입력값 > "zerobase", "aero"
기댓값 > 2
# 테스트 2
입력값 > "heroishere", "herheroishere"
기댓값 > 22. 배열 안정화
문제
정수로 이루어진 배열 nums 가 주어졌다.
이 배열에 아래 연산을 적용하려고 한다.
- 배열의 요소가 양 옆의 값보다 작으면 1 증가시킨다.
- 배열의 요소가 양 옆의 값보다 크면 1 감소시킨다.
- 양 끝에 위치한 요소는 변하지 않는다.
위 연산을 적용했을 때 배열에 변화가 생기면 이 배열은 '불안정하다'고 하고,
배열에 변화가 생기지 않으면 '안정하다'고 하자.
배열이 안정해질 때 까지 위 연산을 적용한 결과를 출력하시오.
입력설명
- 3 <= nums.length <= 100
- 0 <= nums[i] <= 1000
출력설명
안정해진 배열을 정수 배열로 반환
매개변수 형식
nums = {10, 8, 6, 7, 5}
반환값 형식
{10, 8, 7, 6, 5}
예제입출력 설명
주어진 배열은 연산을 한번 적용하면 안정된 배열이 된다.
{10, 8, 6, 7, 5} -> {10, 8, 7, 6, 5}
풀이
이 문제는 처음값과 맨 마지막 값은 값이 변경되지 않는다는 것이 특징이다.
처음에는 한 번의 탐색에서 끝내려고 하였다. 그러나 그렇게 풀이하면 정답이랑 일치하지가 않는다.
def solution(nums):
i = 1
while i < len(nums) - 1:
# 가운데 값이 양 끝값 보다 작은 경우
while nums[i-1] > nums[i] and nums[i] < nums[i+1]:
nums[i] += 1
# 가운데 값이 양 끝값 보다 큰 경우
while nums[i-1] < nums[i] and nums[i] > nums[i+1]:
nums[i] -= 1
i+=1
return nums이렇게 시도를 해보고 그 다음방안으로 생각해봐야 할 것은 배열의 처음 부터 끝까지 탐색할 때 하나씩 변경하고 다시 탐색할 때 하나씩 변경하고 이렇게 하다가 이전의 배열과 이후의 배열이 같다면 이제 안정된 배열이라 볼 수 있게된다.
상세한 로직은 한번 탐색에서 이전 배열(current)을 하나 만들고 변경할 배열(new)을 하나 만든다.
그리고 current와 new가 같다면 안정화 상태라 볼 수 있음으로 new를 리턴한다.
만약 다르다면 아직 불안정하다는 뜻임으로 current에 new를 할당해주고 new를 변경해나간다.
이렇게 current와 new가 같아질 때까지 반복한다.
전체 코드는 아래와 같다.
def solution(nums):
current = nums[:]
new = nums[:]
while True:
current = new[:]
for i in range(1, len(nums)-1):
if current[i] > current[i-1] and current[i] > current[i+1]: # v < i > v
new[i] -= 1
if current[i] < current[i-1] and current[i] < current[i+1]: # v > i < v
new[i] += 1
if current == new:
break
return new아래는 메모리를 좀 더 개선했다.
def solution(nums):
prev = nums[:]
while True:
nums = prev[:]
i = 1
while i < len(nums) - 1:
if nums[i-1] > nums[i] < nums[i+1]:
prev[i] += 1
elif nums[i-1] < nums[i] > nums[i+1]:
prev[i] -= 1
i += 1
if prev == nums:
break
return nums
TestCase 1
# 테스트 1
입력값 〉 [10, 8, 6, 7, 5]
기댓값 〉 [10, 8, 7, 6, 5]# 테스트 2
입력값 〉 [74, 24, 69, 45, 59, 6, 84, 64, 27, 77]
기댓값 〉 [74, 52, 52, 52, 52, 52, 64, 64, 64, 77]3. 가구 연결
문제
마을에 n 개의 가구가 있고, 이 모든 가구에 전기를 공급하고자 한다.
가구에 전기를 공급하는 방법은 둘 중 한가지다.
- 가구와 송전선을 연결한다.
- 전기를 공급받고 있는 가구와 다른 가구를 연결한다.
t 번째 가구와 송전선을 연결하는 데에 들어가는 비용은 cost[i] 로 주어지며,
가구1과 가구2를 연결하는 데에 들어가는 비용은 line[i] = {가구1, 가구2, 비용} 으로 주어진다.
임의의 두 가구는 연결이 가능한 경우에만 line 에 주어지며, 이 연결은 양방향 모두 가능하다.
또한, 동일한 두 가구를 연결하는 비용이 다른 연결선이 여럿 있을 수 있다.
이 때, 모든 가구에 전기를 공급하는 데에 필요한 최소의 비용을 구하시오.
입력설명
- 2 <= n <= 1000
- 0 < line.length <= 10000
출력설명
최소 비용을 정수로 반환
매개변수 형식
n = 3
cost = {5, 10, 7}
line = {{0, 1, 3}, {2, 0, 4}, {0, 2, 2}}
반환값 형식
10
입출력 예시 설명
아래와 같이 연결하면 모든 가구를 연결할 수 있다.
- 0 번 가구와 송전선을 연결한다. (비용 5)
- 1 번 가구를 0 번 가구와 연결한다. (비용 3)
- 2 번 가구를 0 번 가구와 연결한다. (비용 2)
풀이
이 문제는 최소 신장트리(Minimum spanning Tree)문제로 각 노드(가구)를 최소한의 비용으로 간선(연결)을 연결해야 하는 문제 접근하면 된다.
가중치 그래프에서 모든 정점을 최소 비용으로 연결하는 크루스칼(Kruskal’s) 알고리즘을 사용하면 된다.
반드시 송전선과 가구는 최소 1개는 연결되어야 함으로 송전선 노드를 따로 추가해준다.
그럼 반드시 송전선 노드는 하나는 연결되게 되어있다.
- 동작과정
- 그래프의 간선을 가중치 기준으로 오름차순으로 정렬한다.
- 모든 노드는 각자의 그룹으로 구성되어 있다.
- 간선 선택
- 두 정점이 같은 집합에 속하지 않으면(사이클이 생기지 않으면) 해당 간선을 MST에 추가
- 두 정점을 같은 집합으로 합친다.
- 최소 신장트리가 완성될 때까지 반복(edge의 수가 vertax-1이 될 때까지 반복한다)
크루스칼 알고리즘에서 사용되는 Union-Find를 구현해보자
Union은 두 노드가 서로 같은 부모(같은 그룹)를 같는다면 False를 리터하여 이미 연결되어있음을 알리고 다른 그룹이라면 True를 리턴하여 합쳐준다.
def union_find(parent, a, b):
rootA = find(parent, a)
rootB = find(parent, b)
if rootA != rootB:
return True
return False
추가로 rank를 사용하여 두 노드중 rank가 더 큰 트리에 작은 트리를 붙이는 방식으로하여 효율적인 트리를 구성하도록 한다.
def union_find(parent, rank, a, b):
rootA = find(parent, a)
rootB = find(parent, b)
if rootA != rootB:
if rank[rootA] > rank[rootB]:
parent[rootB] = rootA
elif rank[rootA] < rank[rootB]:
parent[rootA] = rootB
else:
parent[rootB] = rootA
rank[rootA] += 1
return True
return False
이제 부모(루트) 노드를 찾는 find함수는 재귀적으로 탐색하다가 자식과 부모의 값이 같으면 루트 노드임을 알 수 있다. 그리고 한번 탐색하여 부모노드를 찾았다면
def find(parent, x):
if parent[x] != x:
return find(parent, parent[x])
return x이제 가중치를 오름차순으로 정렬해주고 최소비용을 계산해주도록 구현하면 최종코드는 아래와 같다.
def find(parent, x):
if parent[x] != x:
return find(parent, parent[x])
return x
def union(parent, rank, a, b):
rootA = find(parent, a)
rootB = find(parent, b)
if rootA != rootB:
if rank[rootA] > rank[rootB]:
parent[rootB] = rootA
elif rank[rootA] < rank[rootB]:
parent[rootA] = rootB
else:
parent[rootB] = rootA
rank[rootA] += 1
return True
return False
def solution(n, cost, line):
# 가상의 송전선 노드 인덱스: n
edges = []
# 송전선 노드와 각 가구를 연결하는 간선 추가
for i in range(n):
edges.append((cost[i], n, i)) # (비용, 노드n, 노드i)
# 가구간 연결선 추가
for l in line:
u, v, w = l
edges.append((w, u, v))
# 비용 기준으로 정렬
edges.sort(key=lambda x: x[0])
parent = [i for i in range(n+1)]
rank = [0] * (n+1)
mst_cost = 0
# Kruskal MST
for w, u, v in edges:
if union(parent, rank, u, v):
mst_cost += w
return mst_cost
TestCase
# Test 1
입력값 〉 3, [5, 10, 7], [[0, 1, 3], [2, 0, 4], [0, 2, 2]]
기댓값 〉 10
# Test 2
입력값 〉 5, [931, 989, 553, 947, 368], [[3, 0, 680], [4, 1, 617], [1, 3, 498], [1, 3, 995], [3, 0, 262], [1, 2, 91], [3, 2, 197], [3, 2, 245], [3, 4, 214], [0, 4, 479], [2, 1, 114], [4, 2, 681]]
기댓값 〉 11324. 배열 곱
문제
정수로 이루어진 x 와 y 배열이 주어져 있다.
x 배열의 크기를 N, y 배열의 크기를 M이라 할 때, N <= M 을 항상 만족한다.
다음 과정을 통해 두 배열로부터 점수를 계산할 수 있다고 하자.
- 점수는 0 부터 시작한다.
- x 배열의 첫번째 요소를 제거한다.
- y 배열의 첫번째 요소 또는 마지막 요소를 제거한다.
- 위에서 제거한 두 값을 곱해 점수에 더한다.
- x 배열에 남은 요소가 없을 때 까지 반복한다.
위 조건에 맞게 계산할 수 있는 점수 중 최대값을 구하시오.
입력설명
- 0 < x.length <= 100000
- x.length <= y.length <= 100000
- -100 < x[i], yli] <= 100
출력 설명
가능한 점수의 최대값을 반환
매개변수 형식
- X= {5, -2, 1}
- Y = {6, 1, 2, 3, 4}
반환값 형식
32
예시입출력 설명
Y 배열에서 '첫번째 값, 첫번째 값, 마지막 값' 순서로 뽑으면 아래와 같이 계산된다.
5*6 + (-2)x1 + 1*4 = 32
풀이
x를 하나씩 제거한 후 x가 음수일 수 있기 떄문에 단순히 y[0] > y[-1]로 값을 비교하지 않고 x를 곱한 수와 비교하여 더 큰 값을 산출해내는 방식으로 풀이했다.
def solution(x, y):
result = 0
for num in x:
if num * y[0] > num * y[-1]:
result += num * y.pop(0)
else:
result += num * y.pop()
return result그러나 위 코드는 단순히 그리디방식으로 풀이하여 최대값을 찾도록 하였는데 추가적인 테스트 케이스에 대해서는 통과하지 못한다.
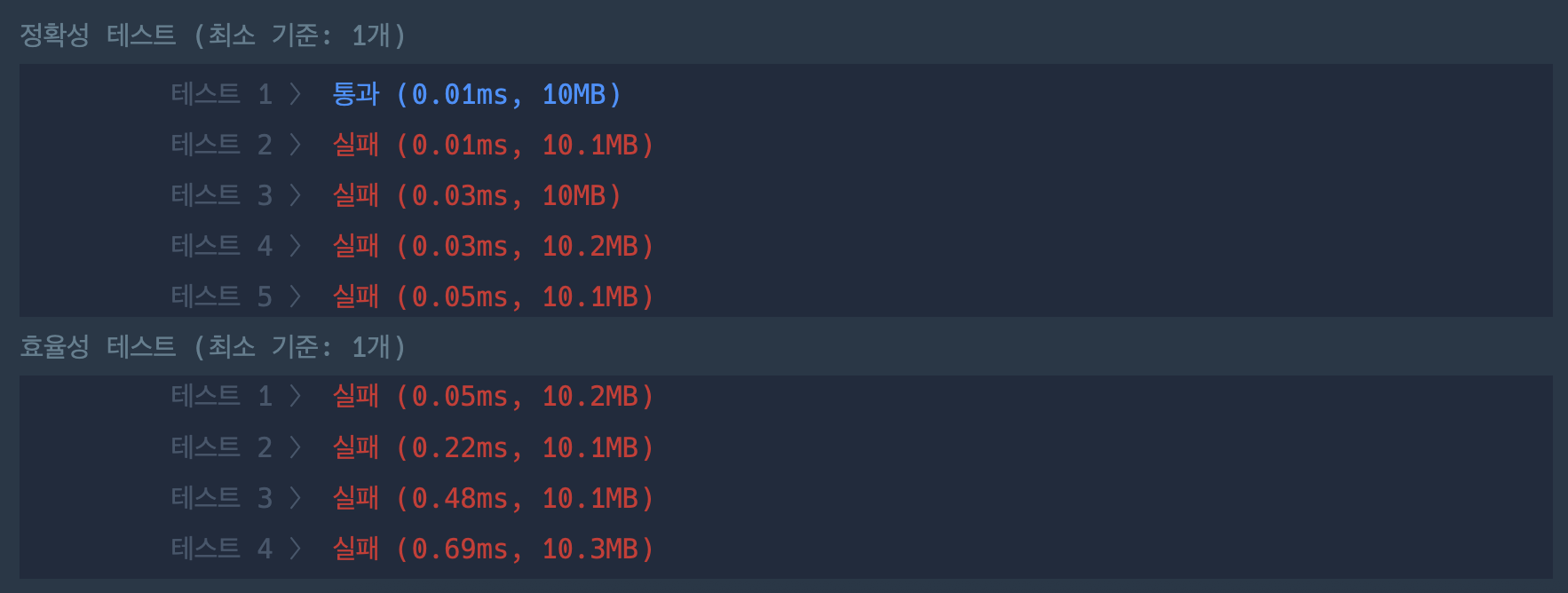
그 이유는 단순히 현재 상태에서의 큰 값만을 고려하여 값을 추출해 곱하는 경우 이후에 더 최대값을 만드는 경우에 대해서는 고려하지 않고 현재 상태만 고려하기 때문이다.
이 방법은 직전 단계에서의 국소적 최적(local optimum) 선택이 곧 전역적 최적(global optimum)을 보장한다는 전제가 없다는 뜻이다. (그리디 접근법에서는 이것이 보장된다)
그리디 알고리즘은 국소 최적 해(Local Optimum)를 선택했을 때, 이 선택이 결국 전역 최적 해(Global Optimum)로 이어진다는 전제가 있을 때 사용할 수 있다.
예를들어 x = [5, -2, 1], y = [6, 1, 2, 3, 4] 경우는 단순히 현재 단계에서의 가장 큰 값만을 y에서 추출하면 된다. 그러나 x = [-2, -7, -1], y = [-4, -5, -6] 경우는 그렇지 않다.
위 코드 방식대로 한다면
- (-2) * (-6) = 12
- (-7) * (-5) = 35
- (-1) * (-4) = 4
Total: 51
실제 최대값:
- (-2) * (-4) = 8
- (-7) * (-6) = 42
- (-1) * (-5) = 5
Total: 55
임으로 그리디 방식이 아닌 다이나믹 프로그래밍으로 접근해야 한다.
위 문제를 효율적으로 해결하기 위해 dfs에 DP를 결합한다.
def solution(x, y):
N = len(x)
M = len(y)
memo = {}
def dfs(left, i):
if i == N:
return
if (left, i) in memo:
return memo[(left, i)]
right = M - 1 - (i - left)
left_pick = x[i] * y[left] + dfs(left+1, i+1)
right_pick = x[i] * y[right] + dfs(left, i+1)
res = max(left_pick, right_pick)
memo[(left, i)] = res
return res
result = dfs(0, 0)
return result
코드 동작 방식:

TestCase
# Test 1
입력값 〉 [5, -2, 1], [6, 1, 2, 3, 4]
기댓값 〉 32
# Test 2
입력값 〉 [-51, 38, -9, 19, -88], [69, 28, -46, 54, -44, -27, 24, 77, 100]
기댓값 〉 5540
5. 플라스틱 소화
문제
당신은 플라스틱을 소화할 수 있다는 놀라운 비밀을 간직하고 있는 히어로 '플라스틱-소화-맨-또는-우먼'이다.
플라스틱은 탄소 체인으로 만들어져 있고, 당신이 소화하는 데에 걸리는 시간은 탄소 체인의 길이에 비례한다.
당신은 비밀스럽게 플라스틱을 섭취해야 하기 때문에 최대한 빠르게 식사량을 채워야 한다.
당신은 오늘 활동한 정도를 따져본 결과, hungry 만큼의 플라스틱을 섭취해야 한다.
당신이 숨겨놓은 플라스틱은 여러 종류가 있으며, i번째 플라스틱 종류를 plastic[i] 만큼 보유하고 있다.
i 번째 플라스틱은 탄소 체인의 길이가 chain[i] 이며, 이 플라스틱은 1만큼 섭취하는 데에 탄소 체인 길이만큼의 시간이 소요된다.
즉, i번째 플라스틱을 모두 섭취하려면 plastic[i] * chain[i] 만큼의 시간이 걸리는 셈이다.
그런데 당신은 플라스틱을 빠르게 섭취하기 위한 '플라스틱-소화잘돼-빔'을 사용할 수 있다.
이 방법을 사용하면 한 종류의 플라스틱의 탄소 체인을 반으로 줄일 수 있다.
이 때 정수 나눗셈을 사용하여, 소숫점이 발생할 경우 버림한다.
대신에 이 방법을 한번 사용할 때 마다 price 만큼 플라스틱을 섭취해야 하는 양이 늘어난다.
가장 빨리 필요한 양의 플라스틱을 섭취했을 때 소요된 시간을 구하시오.
(조건) 단, 모든 플라스틱을 섭취해도 식사량이 충족되지 않을 경우 모든 플라스틱을 섭취하는 데에 걸리는 최소 시간을 반환하시오.
입력설명
- 0 < hungry <= 100000
- 0 < price <= 100000
- 0 < plastic.length = chain.length <= 100
- 0 < plasticli] <= 100
- 0 < chain[i] <= 100
출력설명
필요한 최소의 시간을 정수로 반환
매개변수 형식
hungry = 100
price = 10
plastic = [35, 12, 16, 44, 1, 16]
chain = [12, 6, 11, 32, 1, 7]
반환값 형식
1211
예시입출력 설명
0번 플라스틱과 3 번 플라스틱에 빔을 사용하면 2회 빔을 사용하므로 배고픔 수치는 120이 된다. 그리고 다른 모든 플라스틱을 섭취한 후, 3번 플라스틱을 배부를 때 까지 섭취하면 총 시간은 1211 만큼 소요된다.
(조건)에 따라 hungry를 다 채우지 못하였다.
풀이
이 문제는 dfs로 모든 경우에 대해서 다 탐색하여 최소시간을 반환하도록 하면 된다.
먼저 빔을 사용해서 줄인시간이 > 플라스틱이 price만큼 늘어나면서 추가되는 시간 보다 작으면 시간을 단축할 수 있다는 뜻이 된다.
def solution(hungry, price, plastic, chain):
N = len(plastic)
max_plastic = sum(plastic)
visited = []
satisfied = False
result = float('inf')
advantage = []
for p, c in zip(plastic, chain):
if p*(c - c//2) > price*c//2:
advantage.append(True)
else:
advantage.append(False)path라는 변수를 사용하여 빔을 사용한 플라스틱을 저장한다.
path에 이미 빔을 사용한 플라스틱이 존재하면 넘어간다.
그리고 advantage가 있는 플라스틱에 대해서만 빔을 사용하도록 한다.
def solution(hungry, price, plastic, chain):
N = len(plastic)
max_plastic = sum(plastic)
visited = []
satisfied = False
result = float('inf')
advantage = []
for p, c in zip(plastic, chain):
if p*(c - c//2) > price*c//2:
advantage.append(True)
else:
advantage.append(False)
def dfs(last_time, path):
nonlocal result, satisfied
for i in range(N):
if i not in path and advantage[i]:
dfs(time, path + [i])
dfs(float('inf'), [])
return result이제 빔사용한 것과 사용하지 않은 것을 구분해 시간을 계산해준다.
빔을 사용한 플라스틱에 대해서 visited라는 리스트를 사용해 기록하여 중복탐색을 방지한다.
def solution(hungry, price, plastic, chain):
N = len(plastic)
max_plastic = sum(plastic)
visited = []
satisfied = False
result = float('inf')
advantage = []
for p, c in zip(plastic, chain):
if p*(c - c//2) > price*c//2:
advantage.append(True)
else:
advantage.append(False)
def dfs(last_time, path):
nonlocal result, satisfied
path.sort()
if path in visited:
return
visited.append(path)
for i in range(N):
if i not in path and advantage[i]:
dfs(time, path + [i])
dfs(float('inf'), [])
return result
이제 플라스틱 섭취 시간을 계산하기 위해 빔을 사용한 플라스틱과 사용하지 않은 플리스틱을 계산한다.
그리고 단위시간당 플라스틱을 가장 많이 섭취하기 위해서는 chain이 작은 순으로 정렬하면 적은 시간으로 많은 양의 플라스틱을 섭취할 수 있다.
같은 플라스틱 2개를 섭취하는데 chain이 클수록 섭취하는 시간만 늘어나는 꼴이된다.
# plastic 고정하고 chain을 변경
- chain: 10 plastic: 2
20시간에 2개를 섭취
1시간에 0.1개를 섭취
- chain: 5 plastic: 2
10시간에 2개를 섭취
1시간에 0.2개를 섭취반면에 plastic이 작아지면 그만큼 섭취시간도 감소하기 때문에 효율과 비효율을 결정하는건 chain값이 결정한다.
# chain 고정하고 plastic을 변경
- chain: 2 plastic: 10
20시간에 10개를 섭취
1시간에 0.5개를 섭취
- chain: 2 plastic: 5
10시간에 5개를 섭취
1시간에 0.5개를 섭취따라서 chain이 작은 순으로 정렬하여 섭취 시간과 섭취량을 계산해준다.
아무리 빔을 사용해도 최대로 플라스틱을 섭취할 수 있는 양은 주어진 plastic의 갯수이다. 왜냐하면 빔은 시간을 단축시켜주는 것이지 플라스틱 섭취량에는 관여하지 않는다.
만약 plastic = [35, 12, 16, 44, 1, 16] 라면 최대로 섭취가능한 플라스틱은 plastic을 전부 더한 124이다. 따라서 빔을 많이 사용해서 dst_hungry가 124보다 크면 무슨짓을 해도 플라스틱 섭취를 만족할 수 없다.
그리고 last_time을 추가해준다. result를 기준으로 하지 않고 last_time을 기준으로 하는 이유는 플라스틱을 섭취했고 그 시간보다 더 최적의 시간을 탐색한다
def solution(hungry, price, plastic, chain):
N = len(plastic)
max_plastic = sum(plastic)
visited = []
satisfied = False
result = float('inf')
advantage = []
for p, c in zip(plastic, chain):
if p*(c - c//2) > price*c//2:
advantage.append(True)
else:
advantage.append(False)
def dfs(last_time, path):
nonlocal result, satisfied
path.sort()
if path in visited:
return
visited.append(path)
curr_hungry = hungry + price * len(path)
if curr_hungry > max_plastic: # 최대로 섭취햘 수 있는 양보다 배고픔이 크면 불가능
return
items = []
for i in range(N):
if i in path: # 빔을 사용
items.append((plastic[i], chain[i]//2))
else: # 빔을 사용하지 않음
items.append((plastic[i], chain[i]))
items.sort(key = (lambda x: x[1])) # chain이 작은 순으로 정렬
time = 0
for p, c in items:
if curr_hungry > p: # 섭취해야할 플라스틱 보다 배고픈게 크면
time += p * c
curr_hungry -= p
if time > last_time:
return
else: # 작으면 배고픈 만큼만 섭취
time += (curr_hungry * c)
curr_hungry = 0
break
if time > last_time:
return
for i in range(N):
if i not in path and advantage[i]:
dfs(time, path + [i])
dfs(float('inf'), [])
return result
이제 최솟값을 저장하도록 하는 코드만 추가하면 된다.
last_time을 사용하는 이유는 이전에 탐색했던 시간에서 빔을 사용해 시간을 줄여나가는 것인데, 오히려 시간이 늘어났다면 이는 잘못된 방법임으로 이전 시간을 기록하는 last_time을 주어 불필요한 탐색을 막아준다.
최솟값을 저장할때는 global한 최솟값을 저장해야 함으로 last_time이 아닌 result를 기준으로 비교한다.
전체 코드는 아래와 같다.
def solution(hungry, price, plastic, chain):
N = len(plastic)
max_plastic = sum(plastic)
visited = []
satisfied = False
result = float('inf')
advantage = []
for p, c in zip(plastic, chain):
if p*(c - c//2) > price*c//2:
advantage.append(True)
else:
advantage.append(False)
def dfs(last_time, path):
nonlocal result, satisfied
path.sort()
if path in visited:
return
visited.append(path)
curr_hungry = hungry + price * len(path)
if curr_hungry > max_plastic: # 최대로 섭취햘 수 있는 양보다 배고픔이 크면 불가능
return
items = []
for i in range(N):
if i in path: # 빔을 사용
items.append((plastic[i], chain[i]//2))
else: # 빔을 사용하지 않음
items.append((plastic[i], chain[i]))
items.sort(key = (lambda x: x[1])) # chain이 작은 순으로 정렬
time = 0
for p, c in items:
if curr_hungry > p: # 섭취해야할 플라스틱 보다 배고픈게 크면
time += p * c
curr_hungry -= p
if time > last_time:
return
else: # 작으면 배고픈 만큼만 섭취
time += (curr_hungry * c)
curr_hungry = 0
break
if time > last_time:
return
if not satisfied and curr_hungry == 0:
result = time
satisfied = True
elif curr_hungry == 0 and time < result:
result = time
satisfied = True
elif curr_hungry != 0:
result = time
return
for i in range(N):
if i not in path and advantage[i]:
dfs(time, path + [i])
dfs(float('inf'), [])
return resultTestCase
# Test 1
입력값 〉 100, 10, [35, 12, 16, 44, 1, 16], [12, 6, 11, 32, 1, 7]
기댓값 〉 1211출처
해당 문제와 코드는 제로베이스(ZeroBase)에서 제공받았습니다.
모든 자료는 저작권법에 의하여 보호받는 저작물로서 이에 대한 무단 복제 및 배포를 원칙적으로 금합니다.
Comment