
목차
- (미완) 은행거래
- 한 끗 차이
- 단어 유사도
1. 은행 거래

풀이
이 문제를 처음에는 순환 그래프인 경우 그것을 1개의 거래로 최적화할 수 있겠구나라는 방식으로 접근하였다.
그러나 이 문제는 누구에게 보내는지에 대한 제약이 없고 그냥 최종적인 결과만 같으면 되는 문제이다.
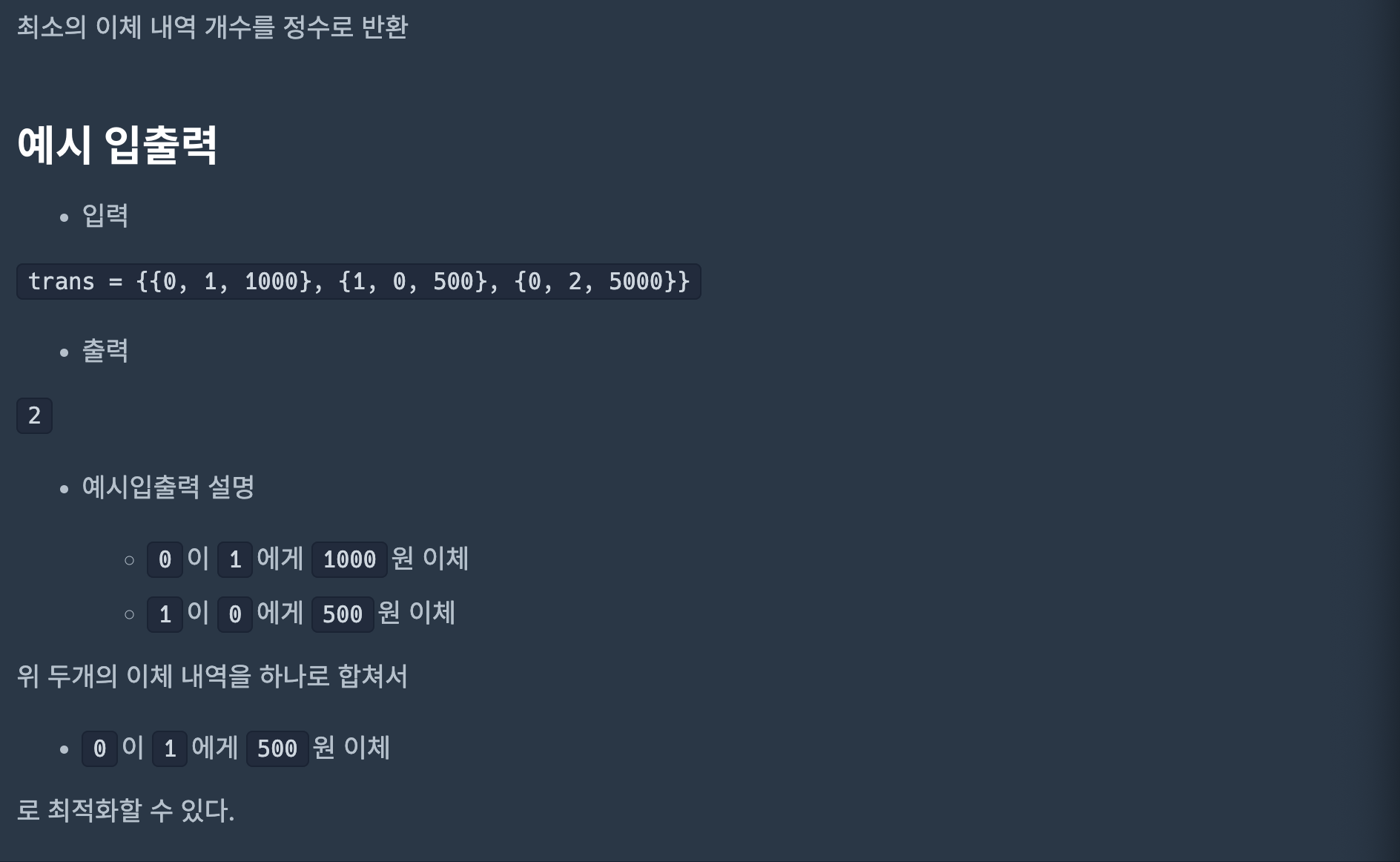
예시: [[0, 1, 1000], [1, 0, 500], [0, 2, 5000]]
0 → 1: 1000원 이체, (0 잔고: -1000, 1 잔고: +1000)
1 → 0: 500원 이체, (1 잔고: 500, 0 잔고: -500)
0 → 2: 5000원 이체, (0잔고: -5500, 1 잔고: 500, 2 잔고: +5000)
따라서 최종 결과는 {0잔고: -5500, 1 잔고: 500, 2 잔고: +5000}가 되야 한다.
위에는 3번의 이체로 위 결과를 만들었다면 2번 이체만으로도 가능하다.
0 → 2에게 5000원을 보내고, 0 → 1에게 500원을 보내된다: {0: -5500, 1: 500 2: 5000}
따라서 이 문제는 dfs를 사용하면 해결이 가능하다.
핵심1: 보내야하는 사람에게는 -, 받아야하는 사람은 +금액을 한다.
이렇게 하는 이유는 예를들어 이런 케이스인 경우는 총 3번의 이체가 이뤄진다.
[[0, 1, 500], [1, 0, 500], [2, 3, 100]]
그러나 {0 잔고: 0, 1 잔고: 0, 2 잔고: -100, 3 잔고: 100} 이렇게 됨으로 0과 1번 계좌는 고려할 필요가 없다.
def solution(trans):
# 각 계좌의 순수한 채권/채무 관계를 기록하기 위한 딕셔너리
account = defaultdict(int)
# 모든 거래 내역을 순회하며 각 계좌의 금액 변화를 기록
for a, b, v in trans:
account[a] -= v # 송신자는 v만큼 감소 (빚 증가)
account[b] += v # 수신자는 v만큼 증가 (빚 감소)
# 0이 아닌 값만 남김 (빚이 없는 계좌 제거)
debt = [v for v in account.values() if v != 0]
# 채권/채무가 없는 경우 최적화할 거래 내역이 없으므로 0 반환
if not debt:
return 0이후 dfs를 적용한다.
만약 dept[node]가 0이라면 이 노드를 건너뛰고 다음 노드를 탐색한다.
받거나 보내야할 것이 없음으로 이미 송금처리가 완료된 것이다.
# node가 0인 값(이미 해결된 빚)을 만나면 다음 노드로 이동
while node < n and debt[node] == 0:
node += 1모든 노드의 끝까지 탐색이 끝났다면 몇 번의 이체가 이루어 졌는지 반영한다.
# 마지막 노드에 도달했거나 남은 빚이 없으면 최솟값 갱신 후 종료
if node >= n - 1:
min_count = min(min_count, count)
returndfs는 모든 경우의 수를 다 확인한다. 따라서 초기 inf였던 min_count가 모든 노드의 탐색이 끝나 모든 이체 횟수가 반영되었다.
그런데 다른 경우의 모든 노드를 탐색하려는 과정 중, 이전에 모든 노드를 탐색했던 이체 횟수보다 크다면 이는 더 탐색할 필요가 없음으로 dfs를 종료한다.
# 현재 이체 횟수가 이미 최소값을 초과하면 탐색 종료
elif count > min_count:
return각 송금을 최적화 하기 위해서는 현재 노드와 i번쨰 노드의 부호가 달라야 0원으로 상쇄가 가능하다.
다음 단계(dfs(node+1, count+1))에서는 node를 건너뛰고(= node는 이미 처리했다고 간주) 다음 노드를 탐색한다.
즉 node에 있던 금액을 i에게 넘겼다(상쇄 시도) 로 해석하고, node는 이제 해결된 것으로 간주하고 넘어간다.
쉽게 말해 “한 번의 거래”로, node의 금액을 i가 떠안았다고 볼 수 있다.
이 시점에서 node는 더 이상 별도 조정 없이 넘어가고, i가 새롭게 금액이 갱신 되었으니 이 다음 단계에서 i가 또 다른 노드와 상쇄할 수 있도록 만든다.
if debt[node] + debt[i] == 0: 이 조건은 받아야하는 금액과 보내야하는 금액이 1:1로 딱 맞아떨어져서 서로 완벽히 소멸되었기 때문에 그 한 번의 거래는 최적의 매칭이며, 추가로 i+1, i+2 등 다른 후보를 볼 필요가 없다.
따라서, 이 경우는 다른 i를 더 탐색할 필요가 전혀 없다고 보고 break로 탈출한다.
for i in range(node + 1, n):
if debt[node] * debt[i] < 0:
debt[i] += debt[node]
dfs(node + 1, count + 1)
debt[i] -= debt[node]전체 코드는 아래와 같다.
def solution(trans):
# 각 계좌의 순수한 채권/채무 관계를 기록하기 위한 딕셔너리
account = defaultdict(int)
# 모든 거래 내역을 순회하며 각 계좌의 금액 변화를 기록
for a, b, v in trans:
account[a] -= v # 송신자는 v만큼 감소 (빚 증가)
account[b] += v # 수신자는 v만큼 증가 (빚 감소)
# 0이 아닌 값만 남김 (빚이 없는 계좌 제거)
debt = [v for v in account.values() if v != 0]
# 채권/채무가 없는 경우 최적화할 거래 내역이 없으므로 0 반환
if not debt:
return 0
# 최소 이체 횟수를 기록하기 위한 변수 (무한대로 초기화)
min_count = float('inf')
n = len(debt) # 남은 채권/채무의 개수
# DFS 함수 정의 (node: 현재 탐색 중인 노드, count: 현재까지 이체 횟수)
def dfs(node, count):
nonlocal min_count # 바깥쪽 함수의 min_count 변수 접근
# node가 0인 값(이미 해결된 빚)을 만나면 다음 노드로 이동
while node < n and debt[node] == 0:
node += 1
# 마지막 노드에 도달했거나 남은 빚이 없으면 최솟값 갱신 후 종료
if node >= n - 1:
min_count = min(min_count, count)
return
# 현재 이체 횟수가 이미 최소값을 초과하면 탐색 종료
elif count > min_count:
return
# 현재 노드의 채무를 해결하기 위해 다른 노드와 상쇄를 시도
for i in range(node + 1, n):
# debt[node]와 debt[i]의 부호가 반대일 때 상쇄 가능
if debt[node] * debt[i] < 0:
# debt[i]에 debt[node]를 추가해 상쇄 시도
debt[i] += debt[node]
# 다음 노드로 이동하여 탐색 (이체 횟수 +1)
dfs(node + 1, count + 1)
# 백트래킹: debt[i] 값을 원래대로 복구
debt[i] -= debt[node]
# 만약 debt[node]와 debt[i]가 완전히 상쇄되었다면 더 이상 탐색할 필요 없음
if debt[node] + debt[i] == 0:
break
# DFS 탐색 시작 (노드 0부터 탐색, 초기 이체 횟수 0)
dfs(0, 0)
# 최소 이체 횟수 반환
return min_countTestCase
# 테스트 1
입력값 〉 [[0, 1, 1000], [1, 0, 500], [0, 2, 5000]]
기댓값 〉 2
# 테스트 2
입력값 〉 [[0, 3, 2000], [1, 0, 2200], [0, 2, 200]]
기댓값 〉 22. 한끗 차이


풀이
한 문자가 추가된 경우의 예시는
- s = “abc” , t = “abcd” 인 경우
- 길이 차이: abs(len(s) - len(t)) = 1
비교 과정
- 반복문에서 s 와 t 의 첫 세 문자를 비교: s[0] == t[0] , s[1] == t[1] , s[2] == t[2] .
- 반복문 종료 후, t 의 마지막 문자 “d” 는 s 에 없으므로 한 문자가 추가된 경우에 해당.
- 조건 abs(len(s) - len(t)) == 1 이 만족되므로 True를 반환.
def solution(s, t):
# 두 문자열이 동일하면 한끗차이가 아니므로 False 반환
if s == t:
return False
# 문자열 길이 차이가 1보다 크면 한끗차이가 될 수 없음
if abs(len(s) - len(t)) > 1:
return False
# 두 문자열의 최소 길이만큼 반복
for i in range(min(len(s), len(t))):
# 두 문자열에서 서로 다른 문자를 찾았을 때
if s[i] != t[i]:
# 1. s에서 한 문자를 변경해 t로 만들 수 있는지 확인
if s[i+1:] == t[i+1:]:
return True
# 2. s에서 한 문자를 삭제해 t로 만들 수 있는지 확인
if s[i+1:] == t[i:]:
return True
# 3. t에서 한 문자를 삭제해 s로 만들 수 있는지 확인
if s[i:] == t[i+1:]:
return True
# 위 세 가지 조건을 모두 만족하지 않으면 한끗차이가 아님
return False
# 반복문이 끝난 뒤 문자열 길이 차이가 1이면 한 문자를 추가/삭제한 경우이므로 True
if abs(len(s) - len(t)) == 1:
return True
# 그 외에는 한끗차이가 아님
return FalseTestCase
# 테스트 1
입력값 〉 "zEroBase", "zeroBase"
기댓값 〉 true
# 테스트 2
입력값 〉 "proudDeveloper", "fraudDeveloper"
기댓값 〉 false4. 단어 유사도
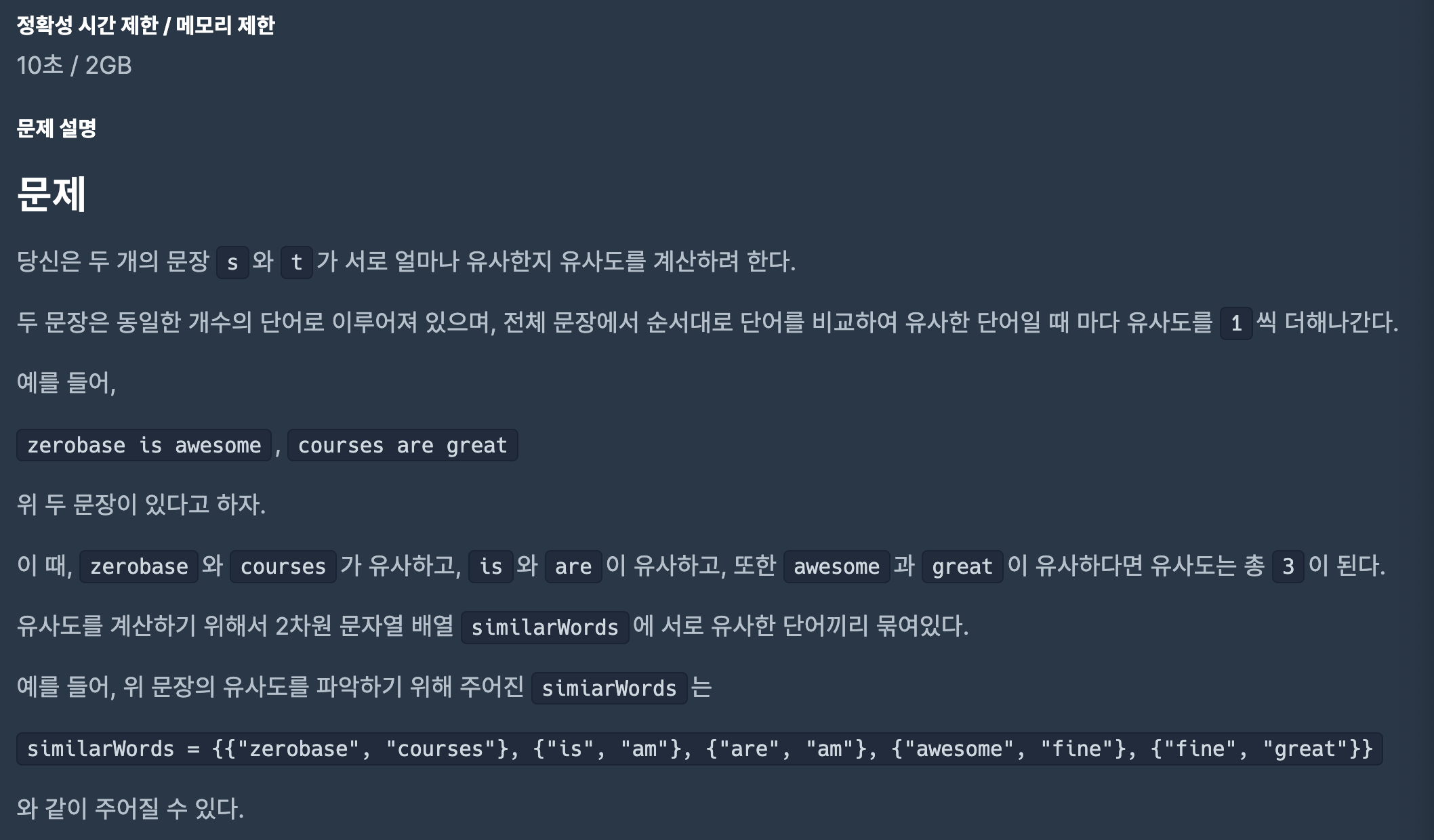
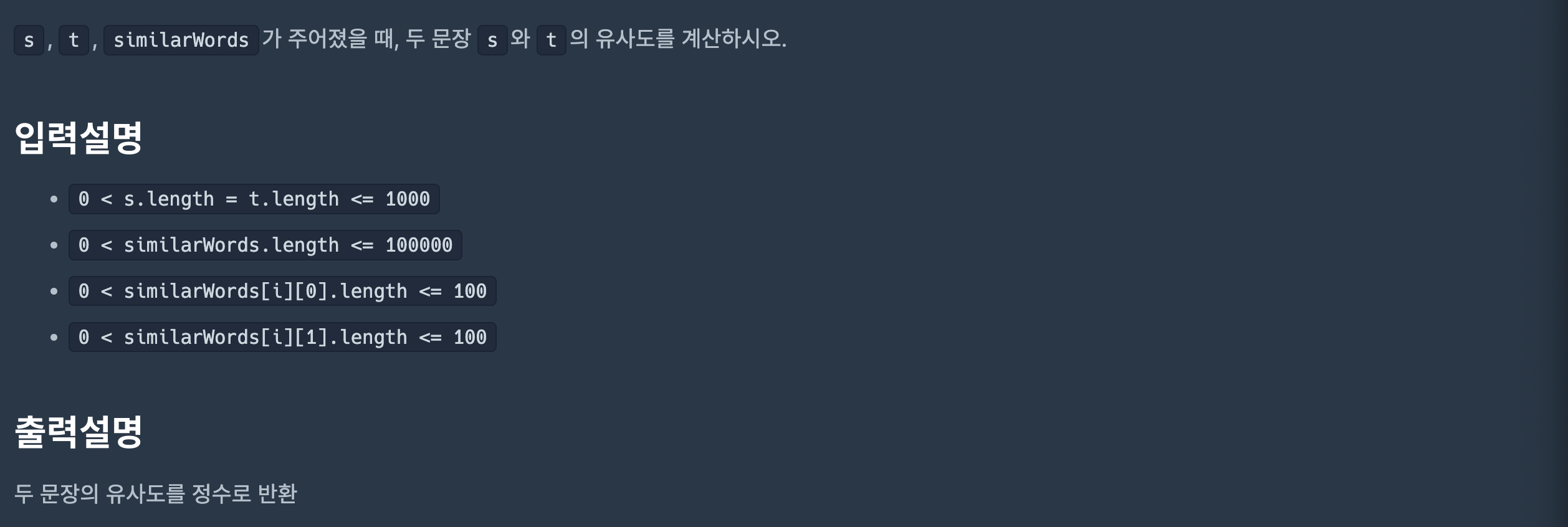
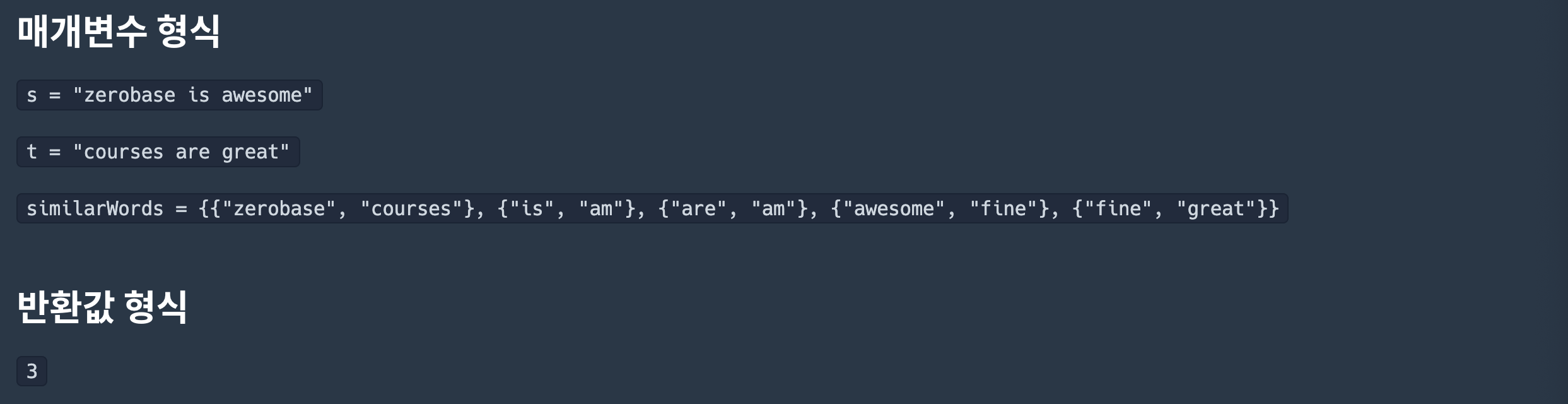
풀이
이 문제는 Union-Find알고리즘을 통해 유사한 워드끼리 묶어 트리를 구성하도록하여 해결하면 된다.
Testcase 1번을 트리형태로 그려보면 아래 처럼 생성된다.
parent의 key는 child를 의미하며 value는 parent를 의미한다.
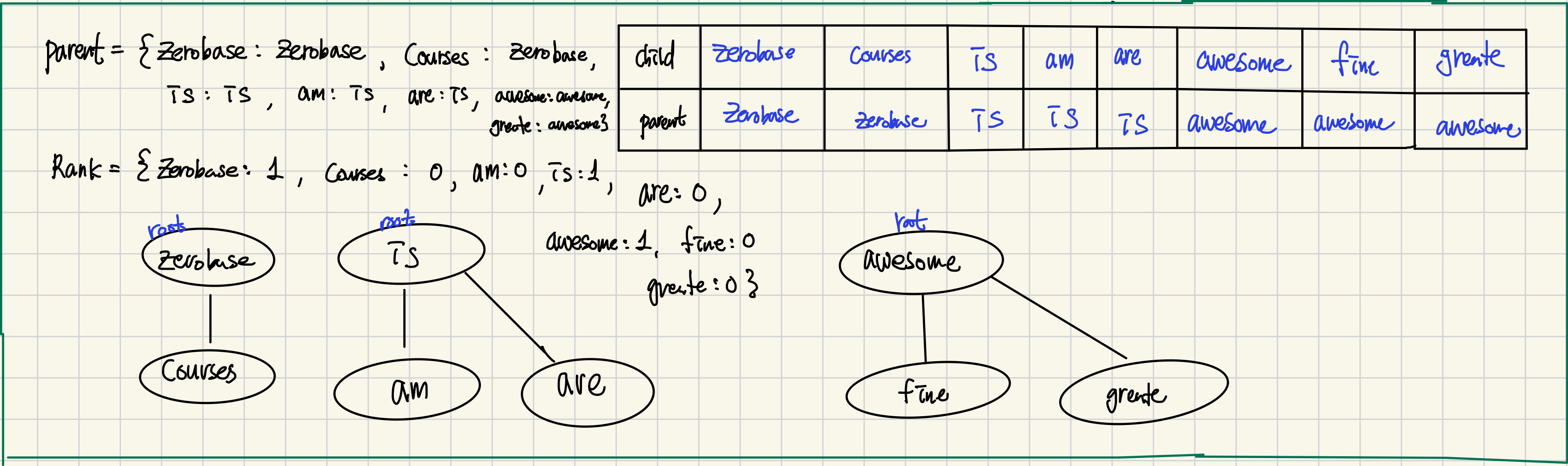
이렇게 트리를 구성하고 각 단어를 find의 입력으로 넣어 본인의 트리의 root노드의 값을 추출하도록 한다.
전체 코드는 아래와 같다.
def solution(s, t, similarWords):
parent = {}
rank = {}
def find(word):
if parent[word] != word:
parent[word] = find(parent[word]) # 경로 압축
return parent[word]
def union(word1, word2):
root1 = find(word1)
root2 = find(word2)
if root1 != root2:
# Union by rank
if rank[root1] > rank[root2]:
parent[root2] = root1
elif rank[root1] < rank[root2]:
parent[root1] = root2
else:
parent[root2] = root1
rank[root1] += 1
# 유사 단어를 Union-Find 구조로 그룹화
for a, b in similarWords:
if a not in parent:
parent[a] = a
rank[a] = 0 # 초기 rank 설정
if b not in parent:
parent[b] = b
rank[b] = 0 # 초기 rank 설정
union(a, b)
# 문장 유사도 계산
sim = 0
words_s = s.split(' ')
words_t = t.split(' ')
for word_s, word_t in zip(words_s, words_t):
if word_s == word_t: # 단어가 동일한 경우
sim += 1
elif word_s in parent and word_t in parent and find(word_s) == find(word_t): # 같은 그룹에 속하는 경우
sim += 1
return simTestCase
# 테스트 1
입력값 〉 "zerobase is awesome", "courses are great", [["zerobase", "courses"], ["is", "am"], ["are", "am"], ["awesome", "fine"], ["fine", "great"]]
기댓값 〉 3
# 테스트 2
입력값 〉 "zerobase is awesome", "games are fine", [["zerobase", "courses"], ["is", "am"], ["are", "am"], ["awesome", "fine"], ["fine", "great"]]
기댓값 〉 25.
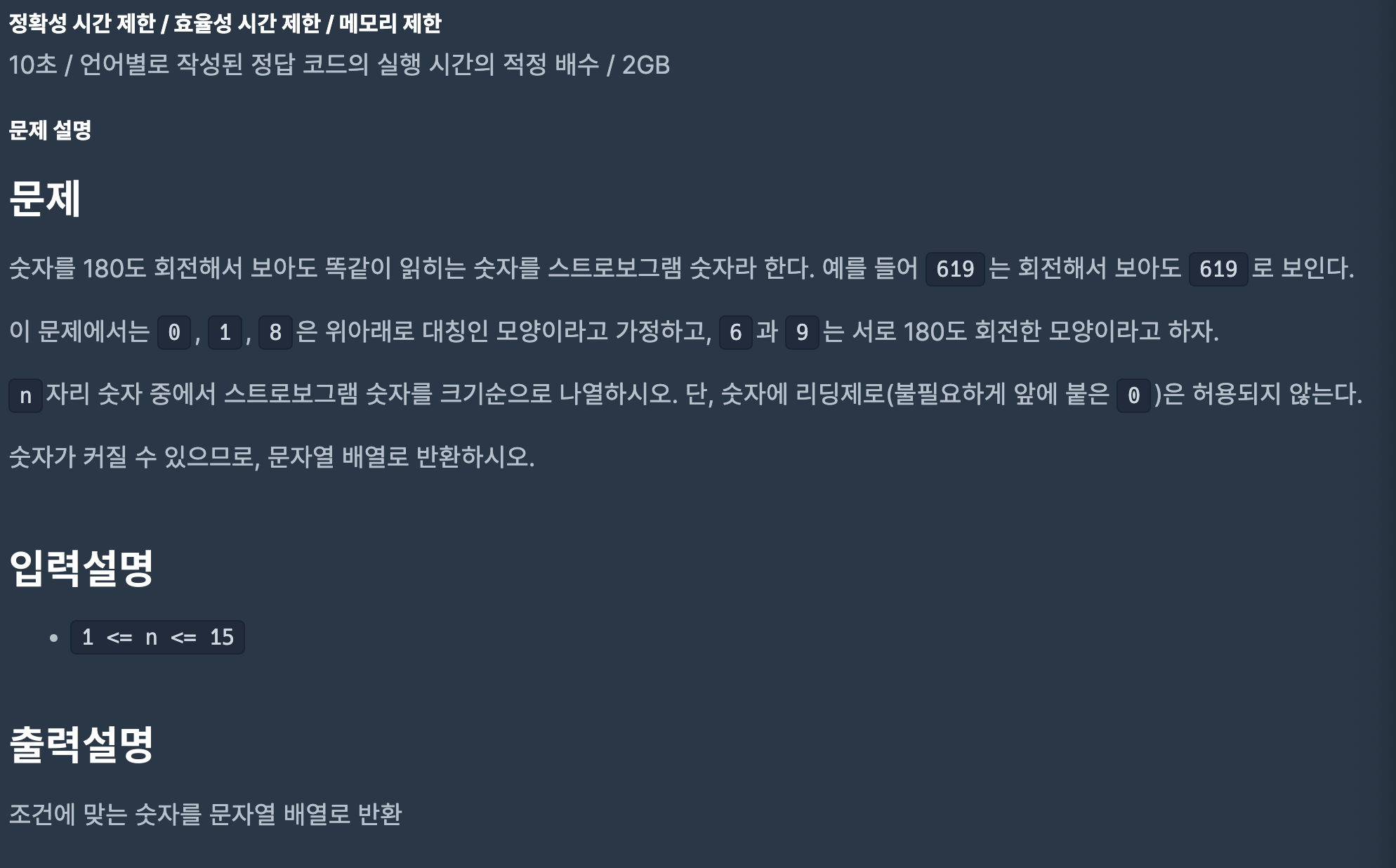
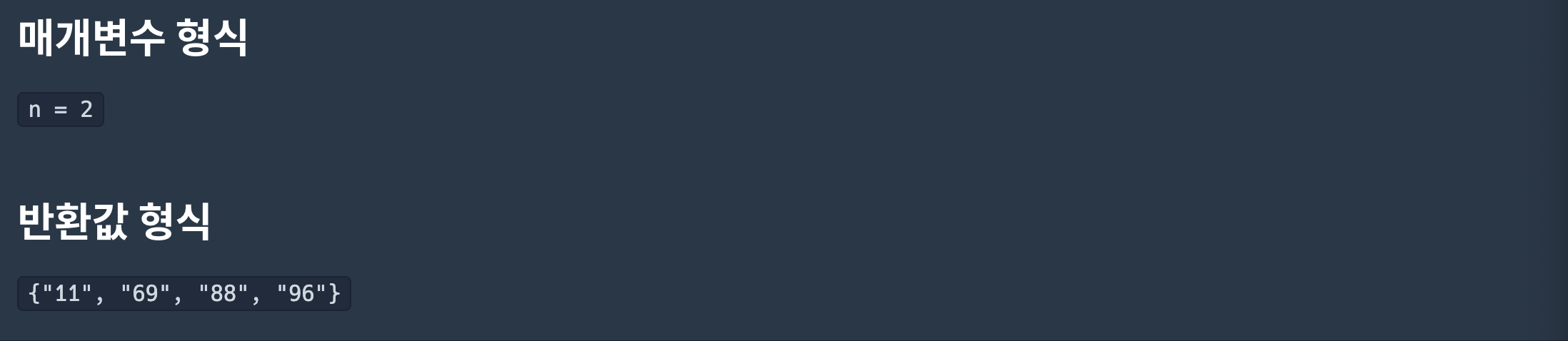
풀이
def solution(n):
answer = []
return answerTestCase
# 테스트 1
입력값 〉 4
기댓값 〉 ["1001", "1111", "1691", "1881", "1961", "6009", "6119", "6699", "6889", "6969", "8008", "8118", "8698", "8888", "8968", "9006", "9116", "9696", "9886", "9966"]
# 테스트 2
입력값 〉 2
기댓값 〉 ["11", "69", "88", "96"]출처
해당 문제와 코드는 제로베이스(ZeroBase)에서 제공받았습니다.
모든 자료는 저작권법에 의하여 보호받는 저작물로서 이에 대한 무단 복제 및 배포를 원칙적으로 금합니다.
Comment